









专利摘要
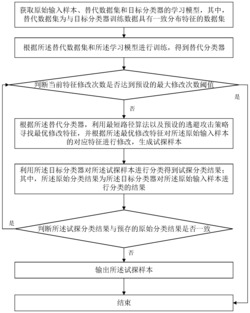
本发明公开了一种基于Linux病毒检测方法,具体包括如下步骤:步骤一:从待测文件中提取出样本特征;步骤二:通过多个不同的基分类器分别对待测文件的样本特征进行检测并生成检测结果;步骤三:对所有基分类器的检测结果进行整合得出待测文件是否为病毒的检测结果。该方法采用多个不同的基分类器对待测文件进行检测,提高了检测的准确性。
权利要求
1.一种基于Linux病毒检测方法,具体包括如下步骤:
步骤一:从待测文件中提取出样本特征;
步骤二:通过多个不同的基分类器分别对待测文件的样本特征进行检测并生成检测结果;
步骤三:对所有基分类器的检测结果进行整合得出待测文件是否为病毒的检测结果,
其特征在于,步骤二中的多个基分类器用以下步骤进行训练:
步骤1:给定训练样本集:S={(x1,y1),…,(xi,yi),…,(xm,ym)},其中xi是实例样本,xi∈X,yi是类别标志,yi∈Y={-1,+1},当yi=+1时,xi为正常文件,当yi=-1时,xi为病毒,其中i∈{1,2,……,m};
步骤2:对样本权重进行初始化:Dt(i)=1/m,其中t∈{1,2,……,T},T为基分类器的个数;
步骤3:获取基分类器ht=H(x,y,Dt)的权重:
a)计算该基分类器的错误率:
b)计算对正样本的识别正确率:
c)计算得到基分类器的权重:
其中,
d)更新样本权重:
e)返回到步骤a中对下一个基分类器的权重进行计算,直到T个基分类器的权重全部计算完成。
2.根据权利要求1所述的一种基于Linux病毒检测方法,其特征在于,在步骤三中,通过以下公式对步骤二中每个基分类器检测的结果进行整合:
3.根据权利要求1所述的一种基于Linux病毒检测方法,其特征在于,在步骤三中,通过D-S证据理论对步骤二中的检测结果进行整合,整合过程如下:步骤Ⅰ:计算归一化因子:
步骤Ⅱ:计算待测文件为病毒文件的信任度:
其中,mt为第t个基分类器对命题﹁N的概率分配,mt的值等于at或1-at,具体取哪一个值与对应的基分类器对本次待测文件的判定结果有关;
步骤Ⅲ:将获取的信任度与预先设定的阈值进行比较,当信任度高于阈值时,判断待测文件为病毒文件,否则为正常文件。
4.根据权利要求3所述的一种基于Linux病毒检测方法,其特征在于,所述阈值可调。
说明书
技术领域
本发明涉及病毒检测领域,尤其涉及一种Linux病毒检测方法。
背景技术
随着大数据及智能化时代的到来,稳定性好、性能高的Linux操作系统已逐渐成为当下应用主流,随之而来的,针对Linux的各种病毒攻击也越来越频繁。但是由于各种原因,Linux上的病毒检测工具远不如Windows平台上的丰富和有效,而且相关的理论研究也不多。因此,对于Linux病毒检测技术的研究具有较大的现实意义。
目前,最简单直接的病毒检测方案为采用特征提取方法从待测文件中得到样本特征,然后通过某种分类算法进行判断,最后得到检测结果。但这种方案存在不足,单个分类器分类能力是有局限的,其检测准确率不是太高,且容易对特定样本产生过拟合性。
发明内容
本发明的主要目的在于提供一种Linux病毒检测方法,通过采用改进的AdaBoost算法对多个不同的基分类器进行训练进而对病毒进行检测,同时采用了基于D-S证据理论对多个基分类器的检测结果进行整合,提高了病毒检测的准确性。
为达到以上目的,本发明采用的技术方案为:一种基于Linux病毒检测方法,其特征在于,具体包括如下步骤:
步骤一:从待测文件中提取出样本特征;
步骤二:通过多个不同的基分类器分别对待测文件的样本特征进行检测并生成检测结果;
步骤三:对所有基分类器的检测结果进行整合得出待测文件是否为病毒的检测结果。
优选地,步骤二中的多个基分类器用以下步骤进行训练:
步骤1:给定训练样本集:S={(x1,y1),…,(xi,yi),…,(xm,ym)},其中xi是实例样本,xi∈X,yi是类别标志,yi∈Y={-1,+1},当yi=+1时,xi为正常文件,当yi=-1时,xi为病毒,其中i∈{1,2,……,m};
步骤2:对样本权重进行初始化:Dt(i)=1/m,其中t∈{1,2,……,T},T为基分类器的个数;
步骤3:获取基分类器的权重:
a)在当前的样本权重分布Dt下,训练得到基分类器:ht=H(x,y,Dt);
b)计算该基分类器的错误率:
c)计算对正样本的识别正确率:
d)计算得到基分类器的权重:
e)更新样本权重:
其中,Zt为归一化因子;
f)返回到步骤a中对下一个基分类器的权重进行计算,直到T个基分类器的权重全部计算完成。
优选地,在步骤三中,通过以下公式对步骤二中每个基分类器检测的结果进行整合:
优选地,在步骤三中,通过D-S证据理论对步骤二中的检测结果进行整合,整合过程如下:
步骤Ⅰ:计算归一化因子:
其中N表示待测文件为正常文件, 表示待测文件为病毒文件,Mt(N)和 为每个基分类器的基本概率函数,每个基分类器的基本概率函数为对应的权重值at或者1-at;
步骤Ⅱ:计算待测文件为病毒文件的信任度:
其中,mt为第t个基分类器对命题﹁N的概率分配,mt的值等于at或1-at,具体取哪一个值与对应的基分类器对本次待测文件的判定结果有关;
步骤Ⅲ:将获取的信任度与预先设定的阈值进行比较,当信任度高于阈值时,判断待测文件为病毒文件,否则为正常文件。
优选地,所述阈值可调。
与现有技术相比,本发明具有以下有益效果:
1)该病毒检测方法采用不同的基分类器对待测文件进行检测,通过对每个基分类器的检测结果进行整合并最终判断待测文件是不是病毒,相比于单个基分类器进行检测,检测结果更加准确;
2)该方法采用的多个基分类器的权重不同,这样能够使那些准确度更高的基分类器具有更大的比重,进而增加了检测的准确性;同时,在计算基分类器权重的时候引入了 其中 是 增函数,通过这种方式求得新的基分类器权重,在分类错误率相同的情形下,那些具有更高正样本识别能力的基分类器将被赋予更大的权重;
3)在整合基分类器的检测结果时,引入了D-S证据理论,这样对病毒的检测从简单的“是“与“否”的判断转化为可量化的数值输出,例如当对检测敏感度要求比较高时,可以把病毒判定的阀值调低,从而将更多可疑文件判定为病毒,反之亦然,通过这种方式,使系统更加适用于不同的检测场景。
具体实施方式
以下描述用于揭露本发明以使本领域技术人员能够实现本发明。以下描述中的优选实施例只作为举例,本领域技术人员可以想到其他显而易见的变型。
实施例一
一种基于Linux病毒检测方法,具体包括如下步骤:
步骤一:从待测文件中提取出样本特征;
步骤二:通过多个基分类器分别对待测文件的样本特征进行检测并生成检测结果;
步骤三:对所有基分类器的检测结果进行整合得到最终检测结果。
步骤一中,可以采用ELF文件的头表信息作为样本特征来源。具体地,ELF(Executable and Linking Format,执行与连接格式)文件格式是Linux操作系统下一种主要的目标文件格式,其属于现有技术,此处不再详述。
步骤二中的基分类器采用BP神经网络分类器,具体地,BP神经网络设置为36x20x12,学习算法为误差反向传播算法,学习率为lr=0.1,最大学习次数为20000次,学习目标误差平方和为Err_goal=10
为了使步骤二中的基分类器的检测结果更加的准确,在检测病毒之前,需要对所有的基分类器进行训练,具体的训练步骤如下:
步骤1:给定训练样本集:S={(x1,y1),…,(xi,yi),…,(xm,ym)},其中xi是实例样本,xi∈X;yi是类别标志,yi∈Y={-1,+1},当yi=+1时,xi为正常文件,当yi=-1时,xi为病毒。
步骤2:对样本权重进行初始化:Dt(i)=1/m。
步骤3:获取基分类器的权重:
a)在当前的样本权重分布Dt下,训练得到基分类器:ht(x)=H(x,y,Dt),其中t∈{1,2,……,T},T为基分类器的个数。
b)计算该基分类器的错误率:
通过ht(xi)≠yi来判断基本分类器的分类结果与样本的实际情况是否一致,当不一致时即为分类错误,将对应的样本的权重计入错误率中。
c)计算对正样本的识别正确率:
在上述公式中,将正样本的权重相加得到正确率。
d)计算得到基分类器的权重:
其中, 部分为现有技术中计算基分类器的权重的公式, 是φt增函数,其中ξ为一个常数,其取值满足在当次循环中令最小错误率的上界下降。通过这种方式求得新的基分类器权重,在分类错误率相同的情形下,那些具有更高正样本识别能力的基分类器将被赋予更大的权重。
e)更新样本权重:
其中,Zt为归一化因子。
f)返回到步骤a中对下一个基分类器的权重进行计算,直到T个基分类器的权重全部计算完成。
步骤三中,进行整合得到最终检测结果的得到是通过对所有基分类器的检测结果进行带权重投票的加权和方式,用下面公式计算得到:
通过基分类器的权重at与对应的基分类器的检测结果ht相乘,综合考虑了该基分类器的权重与检测结果,使最终的检测结果更加准确。
实施例二
实施例二与实施例一的不同在于步骤三,该实施例中采用D-S证据理论对所有基分类器结果进行整合得到最终检测结果,公式如下:
H(x)=D-Stheory(at,ht(x))。
具体地,得到最终检测结果的过程如下:
步骤Ⅰ:计算归一化因子
其中,上述公式为D-S证据理论计算归一化因子的一般公式,此处对其不再详述。由于病毒检测系统共包括两个基本命题:1)样本为正常文件,记为N;2)样本为病毒,记为 且 所以命题空间为 其中N表示对样本判定为正常文件的信任,﹁N对样本判定为病毒的信任。本发明中描述的病毒检测系统有多个基分类器,每个基分类器可以对基本命题做出判断。对于一个给定的测试样本,每个基分类器都会做出对其类型的判断,即信任其正常文件(N)或者信任其为病毒(﹁N)。式中Mt(At)为第t个基分类器对命题At的基本概率函数,T为基本分类器的个数。上式可变换为:
对于每个基分类器的基本概率函数的定义,本发明将实施例一中步骤3中获取的基分类器的权重at作为对应的基本概率函数。例如两个基分类器m1、m2的权重分别为a1、a2,在一次检测中,它们对待测样本的判断分别为N与﹁N,则它们的基本概率函数定义如表所示(两个基分类器的基本概率分配):
同理,可以对多个基分类器的基本概率函数做出定义。
每一次检测,K值重新计算,与每个基分类器对待测样本判断结果相关,因为判断结果不同,每一个基分类器的基本概率分配是不同的。
步骤Ⅱ:计算待测文件为病毒文件的信任度
对由T个基分类器组成的检测系统,采用Dempster正交合成规则来对命题的基本概率函数进行合成,得到检测系统对该命题的信任度分配:
其中,mt为第t个基分类器对命题﹁N(病毒文件)的概率分配,mt的值等于at或1-at,具体取哪一个值与该基分类器对本次待测文件判定的结果有关。例如:该基分类器对本次待测文件的判定结果是﹁N(病毒文件),则此时mt=at,否则mt=1-at。
步骤Ⅲ:将获取的信任度与预先设定的阈值进行比较,当信任度高于阈值时,判断待测文件为病毒文件,否则为正常文件。并且,所述阈值能够根据需要进行调节,当对病毒的检测灵敏度要求较高时,可以将阈值调低,反之,将阈值调高。
具体地,所述D-S证据理论为现有技术,对于其相关公式的来源以及原理不再详述。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
一种Linux病毒检测方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。




















动态评分
0.0