







专利摘要
本发明公开一种基于FPGA的分级并行高速网络TCP流重组方法,采用基于FPGA的分级并行结构,作为第一级的主节点对捕获网络数据包实现负载均衡调度,在保证流粒度的前提下,将高速网络数据流瞬时均衡地调度至作为第二级的从节点中;从节点先并发访问快表以及基于哈希的双向循环链表,若访问快表先找到流记录则结束哈希双向循环链表查找流记录,否则将依赖哈希双向循环链表查找结果,从而确定该TCP流的状态,再判定此次访问TCP流记录的数据包是否有序,对于乱序数据包才为其分配存储空间,并以静态链表维护该流中的乱序数据包来实现TCP流局部重组,在保证该TCP流数据包局部有序的前提下,实现该TCP流的数据包整体有序。
权利要求
1.基于FPGA的分级并行高速网络TCP流重组方法,其特征是包括如下步骤:
S1.负载均衡调度,主节点FPGA对捕获的数据包实现负载均衡调度,在保证流粒度的前提下,使数据流均衡地调度至从节点FPGA上;即
S11.提取数据包首部信息,FPGA采用TEMAC核将物理层比特流封装成MAC帧,再相应提取源IP地址、目的IP地址、源端口、目的端口、复位RST、同步SYN和终止FIN,然后并发执行哈希运算与流映射管理,并采取流映射端口优先的策略选择输出端口;
S12.根据输出端口并发执行将数据包从相应端口发出,将数据包相应信息写入对应端口队列并按周期反馈当前最大剩余数据量,以及统计并反馈本周期内的最小流量端口同时基于速率反馈动态调整下一次统计的周期;
S2.TCP流记录访问,包括流记录添加、流记录查找和流记录清除;即
S21.提取数据包首部信息,FPGA采用TEMAC核将物理层比特流封装成MAC帧,然后再相应提取源IP地址、目的IP地址、源端口、目的端口、序号、确认号、复位RST、同步SYN和终止FIN;
S22.将提取的源IP地址和目的IP地址匹配快表中的CAM,若匹配命中,则将匹配命中的CAM地址作为地址访问RAM得到该TCP流记录的首地址,再根据该首地址访问TCP流记录并反馈该TCP流记录的报文确认号以及该数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址并更新时间标记,然后结束哈希双向循环链表访问TCP流记录;若匹配不命中,则不做任何处理;
S23.对提取的源IP地址、目的IP地址、源端口和目的端口进行四元组哈希运算,并将哈希结果求模取余数,然后判断TCP新建连接,若SYN=1,则为该TCP流记录分配存储空间,并将该TCP流记录插入根据哈希取模结果对应的双向循环链表中,另外将源IP地址、目的IP地址、确认号、链表前驱与后继地址、时间标记、乱序数据包组首地址写入该TCP流记录存储空间中,之后反馈该TCP流记录的报文确认号以及访问该流记录的数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址,最后将上述数据包的源、目的IP地址写入快表中的CAM,另外以该CAM地址作为地址访问RAM,将该流记录首地址写入RAM,从而达到更新快表的目的;若SYN=0,则执行S24;
S24.根据哈希取模结果访问对应双向循环链表,若找到流记录,则判断TCP复位,若RST=1,则将该TCP流记录首地址和对应乱序数据包组首地址以及对应的分块数据包组首地址分别写入指定FIFO以示清除,从而解决存储空间不够用的情况,若RST=0,则执行S25;若没有找到流记录,则不做任何处理;
S25.反馈该TCP流记录的报文确认号以及访问该流记录的数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址并更新时间标记,最后将上述数据包的源、目的IP地址写入快表中的CAM,另外以该CAM地址作为地址访问RAM,将该流记录首地址写入RAM,从而达到更新快表的目的,再判断TCP终止,若FIN=1,则将该TCP流记录首地址和对应乱序数据包组首地址以及对应的分块数据包组首地址分别写入指定FIFO以示清除,尽量解决存储空间不够用的情况,否则不做任何处理;
S3.TCP流重组,对TCP流中的乱序数据包分配对应存储空间并对其重组,从而使得该TCP流的数据包整体有序;即
S31.比较流记录确认号与访问流记录的数据包的TCP报文序号,若确认号等于报文序号,则为按序到来的数据包,然后用上述数据包的报文确认号更新该流记录中确认号,同时更新其时间标记并将该按序数据包发出;否则,执行S32;
S32.根据乱序数据包组首地址访问乱序数据包组,将该乱序数据包的报文序号、确认号与数据包长度写入该静态链表中,然后判断该数据包大小与额定存储块的大小,若该数据包大小大于额定存储块大小,则分配存储空间,将该数据包分块,并采用分块数据包组维护上述分块;否则,执行S33;
S33.按确认号先后顺序维护静态链表,进而实现TCP流局部重组,并更新流记录中乱序数据包组首地址,然后判断链表首部数据包中报文序号与流记录中的确认号,若上述报文序号等于流记录确认号,则乱序数据包已经重组为有序的数据包,将该数据包的存储空间首地址以及分块数据包首地址分别存储于对应FIFO中以示清除,尽量解决存储空间不够用的情况,之后用上述数据包的报文确认号更新流记录中确认号,同时更新其时间标记并将该按序数据包发出;否则,不做任何处理;
S4.TCP流记录超时检测,根据TCP流时间标记更新哈希循环链表中流记录,即
周期性地访问每一条哈希双向循环链表,比较该TCP流记录时间标记与当前时间标记,删除超时的TCP流记录,并重新维护该哈希双向循环链表。
2.根据权利要求1所述的基于FPGA的分级并行高速网络TCP流重组方法,其特征是,
步骤S11中流映射管理根据当前最大剩余数据量判断当前端口的拥塞程度,进而依概率选择最小流量端口为输出端口;在步骤S12中采用将前一个周期中端口速率以及当前端口速率按一定关联因子计算出速率,进而依据当前端口流量得出下一个统计周期值。
3.根据权利要求1所述的基于FPGA的分级并行高速网络TCP流重组方法,其特征是,
步骤S22中快表访问与步骤S23、S24和S25所组成的哈希双向循环链表访问流记录为并发执行;另外,S22中快表访问流记录优先,若访问流记录命中,则结束哈希双向循环链表访问流记录。
4.根据权利要求1所述的基于FPGA的分级并行高速网络TCP流重组方法,其特征是,
步骤S32中,对于乱序数据包组中有数据包长度超过额定块大小时,才采用静态链表与数组共同维护乱序数据包,一般的乱序数据包则仅采用静态链表来维护。
5.根据权利要求1所述的基于FPGA的分级并行高速网络TCP流重组方法,其特征是,
步骤S1、S2、S3和S4并发执行。
说明书
技术领域
本发明涉及互联网技术领域,具体涉及一种基于FPGA的分级并行高速网络TCP流重组方法。
背景技术
随着网络犯罪手段不断趋于复杂化和多样化,传统方法无法检测出某些特殊的新型入侵行为,若敏感信息分片到几个不同的数据包中,数据包特征就会消失从而无法检测出恶意行为,无法满足网络安全防护和打击网络犯罪的实际需要。
为了提高恶意数据流检测的准确性,不能只是运用数据包级的处理,必须将每条TCP流的所有数据包重组为完整的会话流,以进行应用级分析。由于TCP流在IP层被切分成多个IP分片来传输,使得整个数据传输过程中可能存在TCP报文段失序、重复,甚至还会有丢包的情况。通过统计骨干网上的真实流量获知骨干网上的平均报文长度为300字节左右,而且只有极少数乱序数据包,另外在同一条TCP流,95%以上的乱序数据包报文间隔为一个报文段。针对上述情况,为增加网络吞吐量,选择合理的TCP流重组方法至关重要。
当前现有的TCP流重组方法多采用多线程来并行处理,但其进行磁盘I/O(Input/Output,输入/输出)操作时依然造成巨大延时,导致重组效率较低,因此很难满足高速网络数据流分析等对TCP流重组的实时性需求。
发明内容
本发明所要解决的技术问题是现有TCP流重组方法延时大且效率较低的不足,提供一种基于FPGA的分级并行高速网络TCP流重组方法。
本发明的设计思想是:采用基于FPGA的分级并行结构,作为第一级的主节点对捕获网络数据包实现负载均衡调度,在保证流粒度的前提下,将高速网络数据流瞬时均衡地调度至作为第二级的从节点中;从节点先并发访问快表以及基于哈希的双向循环链表,若访问快表先找到流记录则结束哈希双向循环链表查找流记录,否则将依赖哈希双向循环链表查找结果,从而确定该TCP流的状态,再判定此次访问TCP流记录的数据包是否有序,对于乱序数据包才为其分配存储空间,并以静态链表维护该流中的乱序数据包来实现TCP流局部重组,在保证该TCP流数据包局部有序的前提下,实现该TCP流的数据包整体有序。
为解决上述问题,本发明是通过以下方案实现的:
基于FPGA的分级并行高速网络TCP流重组方法,包括如下步骤:
S1.负载均衡调度,主节点FPGA(Field-Programmable Gate Array,现场可编程门阵列)对捕获的数据包实现负载均衡调度,在保证流粒度的前提下,使数据流均衡地调度至从节点FPGA上;即
S11.提取数据包首部信息,FPGA采用TEMAC核(Tri-Mode Ethernet MAC,三态以太网MAC核)将物理层比特流封装成MAC帧,再相应提取源IP地址、目的IP地址、源端口、目的端口、复位RST、同步SYN和终止FIN,然后并发执行哈希运算与流映射管理,并采取流映射端口优先的策略选择输出端口;
S12.根据输出端口并发执行将数据包从相应端口发出,将数据包相应信息写入对应端口队列并按周期反馈当前最大剩余数据量,以及统计并反馈本周期内的最小流量端口同时基于速率反馈动态调整下一次统计的周期;
S2.TCP(Transmission Control Protocol,传输控制协议)流记录访问,包括流记录添加、流记录查找和流记录清除;即
S21.提取数据包首部信息,FPGA采用TEMAC核将物理层比特流封装成MAC帧,然后再相应提取源IP地址、目的IP地址、源端口、目的端口、序号、确认号、复位RST、同步SYN和终止FIN;
S22.将提取的源IP地址和目的IP地址匹配快表中的CAM(Content Addressable Memory,内容可寻址存储器),若匹配命中,则将匹配命中的CAM地址作为地址访问RAM(Random Access Memory,随机存储器)得到该TCP流记录的首地址,再根据该首地址访问TCP流记录并反馈该TCP流记录的报文确认号以及该数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址并更新时间标记,然后结束哈希双向循环链表访问TCP流记录;若匹配不命中,则不做任何处理;
S23.对提取的源IP地址、目的IP地址、源端口和目的端口进行四元组哈希运算,并将哈希结果求模取余数,然后判断TCP新建连接,若SYN=1,则为该TCP流记录分配存储空间,并将该TCP流记录插入根据哈希取模结果对应的双向循环链表中,另外将源IP地址、目的IP地址、确认号、链表前驱与后继地址、时间标记、乱序数据包组首地址(默认为空)写入该TCP流记录存储空间中,之后反馈该TCP流记录的报文确认号以及访问该流记录的数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址,最后将上述数据包的源、目的IP地址写入快表中的CAM,另外以该CAM地址作为地址访问RAM,将该流记录首地址写入RAM,从而达到更新快表的目的;若SYN=0,则执行S24;
S24.根据哈希取模结果访问对应双向循环链表,若找到流记录,则判断TCP复位,若RST=1,则将该TCP流记录首地址和对应乱序数据包(若有)组首地址以及对应的分块数据包组(若有)首地址分别写入指定FIFO以示清除,从而解决存储空间不够用的情况,若RST=0,则执行S25;若没有找到流记录,则不做任何处理;
S25.反馈该TCP流记录的报文确认号以及访问该流记录的数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址并更新时间标记,最后将上述数据包的源、目的IP地址写入快表中的CAM,另外以该CAM地址作为地址访问RAM,将该流记录首地址写入RAM,从而达到更新快表的目的,再判断TCP终止,若FIN=1,则将该TCP流记录首地址和对应乱序数据包(若有)组首地址以及对应的分块数据包组(若有)首地址分别写入指定FIFO以示清除,尽量解决存储空间不够用的情况,否则不做任何处理;
S3.TCP流重组,对TCP流中的乱序数据包分配对应存储空间并对其重组,从而使得该TCP流的数据包整体有序;即
S31.比较流记录确认号与访问流记录的数据包的TCP报文序号,若确认号等于报文序号,则为按序到来的数据包,然后用上述数据包的报文确认号更新该流记录中确认号,同时更新其时间标记并将该按序数据包发出;否则,执行S32;
S32.根据乱序数据包组首地址访问乱序数据包组(采用静态链表来组织),将该乱序数据包的报文序号、确认号与数据包长度写入该静态链表中,然后判断该数据包大小与额定存储块的大小,若该数据包大小大于额定存储块大小,则分配存储空间,将该数据包分块,并采用分块数据包组(采用数组来组织)维护上述分块;否则,执行S33;
S33.按确认号先后顺序维护静态链表,进而实现TCP流局部重组,并更新流记录中乱序数据包组首地址,然后判断链表首部数据包中报文序号与流记录中的确认号,若上述报文序号等于流记录确认号,则乱序数据包已经重组为有序的数据包,将该数据包的存储空间首地址以及分块数据包(若有)首地址分别存储于对应FIFO中以示清除,尽量解决存储空间不够用的情况,之后用上述数据包的报文确认号更新流记录中确认号,同时更新其时间标记并将该按序数据包发出;否则,不做任何处理;
S4.TCP流记录超时检测,根据TCP流时间标记更新哈希循环链表中流记录,即
周期性地访问每一条哈希双向循环链表,比较该TCP流记录时间标记与当前时间标记,删除超时的TCP流记录,并重新维护该哈希双向循环链表。
上述方案中,步骤S11中流映射管理根据当前最大剩余数据量判断当前端口的拥塞程度,进而依概率选择最小流量端口为输出端口;在步骤S12中采用将前一个周期中端口速率以及当前端口速率按一定关联因子计算出速率,进而依据当前端口流量得出下一个统计周期值。
上述方案中,步骤S22中快表访问与步骤S23、S24和S25所组成的哈希双向循环链表访问流记录为并发执行;另外,S22中快表访问流记录优先,若访问流记录命中,则结束哈希双向循环链表访问流记录。
上述方案中,步骤S32中,对于乱序数据包组中有数据包长度超过额定块大小时,才采用静态链表与数组共同维护乱序数据包,一般的乱序数据包则仅采用静态链表来维护。
上述方案中,步骤S1、S2、S3和S4并发执行。
本发明的有益效果在于:通过本发明可以利用FPGA实现分级并行高速网络TCP流重组,加速数据包重组速率,并能实现实时TCP流重组,保证同一条TCP流的数据包整体有序,提高网络吞吐量。
附图说明
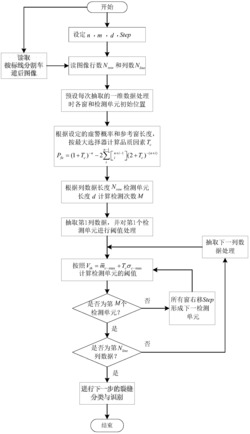
图1是本发明的基于FPGA的分级并行高速网络TCP流重组方法总体结构框图;
图2是本发明的主节点(第一级)负载均衡调度方法结构框图;
图3是本发明的从节点(第二级)TCP流记录访问与TCP重组结构框图;
图4是本发明的从节点TCP流记录访问流程图;
图5是本发明的从节点TCP流重组流程图。
具体实施方式
下面结合附图,给出本发明的具体实施例。需要说明的是:实施例中的参数并不影响本发明的一般性。
参见图1、图2、图3,本发明的设计思想是:采用基于FPGA的分级并行结构,作为第一级的主节点对捕获网络数据包实现负载均衡调度,在保证流粒度的前提下,将高速网络数据流瞬时均衡地调度至作为第二级的从节点中;从节点先并发访问快表以及基于哈希的双向循环链表,若访问快表先找到流记录则结束哈希双向循环链表查找流记录,否则将依赖哈希双向循环链表查找结果,从而确定该TCP流的状态,再判定此次访问TCP流记录的数据包是否有序,对于乱序数据包才为其分配存储空间,并以静态链表维护该流中的乱序数据包来实现TCP流局部重组,在保证该TCP流数据包局部有序的前提下,实现该TCP流的数据包整体有序。
结合图2、图3、图4、图5对基于FPGA的分级并行高速网络TCP流重组过程做进一步说明。具体包含如下步骤:
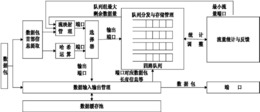
S1.负载均衡调度,主节点FPGA对捕获的数据包实现负载均衡调度,在保证流粒度的前提下,使数据包均衡地调度至从节点FPGA上。参见图2,具体包括如下步骤:
S11.提取数据包首部信息,FPGA采用TEMAC核将物理层比特流封装成MAC帧,再相应提取源IP地址、目的IP地址、源端口、目的端口、复位RST、同步SYN、终止FIN,然后并发执行哈希运算与流映射管理,并采取流映射端口优先的策略选择输出端口;
S12.根据输出端口并发执行将数据包从相应端口发出,将数据包相应信息写入对应端口队列并按周期反馈当前最大剩余数据量,以及统计并反馈本周期内的最小流量端口同时基于速率反馈动态调整下一次统计的周期;
需要指出的是:所述步骤S11中流映射管理根据在本周期中队列组中最大剩余数据量,判断是否存在队列拥塞,若最大剩余数据量,以下简称最大剩余量,小于初始值的70%时视为没有拥塞,则不做任何处理;若最大剩余量超过70%但小于等于80%时视为轻度拥塞,则以1/4为概率选中最小流量端口作为当前数据包的输出端口,并标记流映射端口有效,同时将该数据包对应源IP地址、目的IP地址写入CAM中,并将该CAM地址作为SRAM(Static Random Access Memory,静态随机存储器)地址,将该输出端口值存入SRAM中,以备后续同一条流的数据包访问;若最大剩余量超过80%但小于等于90%时视为中度拥塞,则以1/2为概率选中最小流量端口作为当前数据包的输出端口,后续操作与上类同;若最大剩余量超过90%时视为重度拥塞,则将最小流量端口作为当前数据包的输出端口,即以概率为1选中最小流量端口,后续操作与上类同,不再赘述;在S12中采用将前一个周期中端口速率以及当前端口速率按一定关联因子计算出速率,进而依据当前端口流量得出下一个统计周期值。
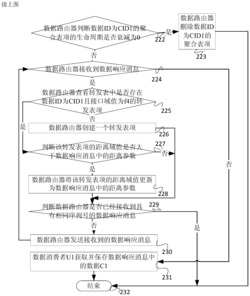
S2.TCP流记录访问,包括流记录添加、流记录查找、流记录清除等。参见图3与图4,具体包括如下步骤:
S21.提取数据包首部信息,FPGA采用TEMAC核将物理层比特流封装成MAC帧,然后再相应提取源IP地址、目的IP地址、源端口、目的端口、序号、确认号、复位RST、同步SYN、终止FIN;
S22.将数据包源IP地址、目的IP地址匹配快表中的CAM,若匹配命中,则将匹配命中的CAM地址作为地址访问SRAM得到该TCP流记录的首地址,再根据该首地址访问TCP流记录并反馈该TCP流记录的报文确认号以及该数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址,然后结束哈希双向循环链表访问TCP流记录;若匹配不命中,则不做任何处理;
S23.对提取的源IP地址、目的IP地址、源端口号、目的端口号四元组哈希运算,将哈希结果求模取余数,然后判断TCP新建连接,若SYN=1,则为该TCP流记录分配存储空间,并将该TCP流记录插入根据哈希取模结果对应的双向循环链表中,另外将源IP地址、目的IP地址、确认号、链表前驱与后继地址、时间标记、乱序数据包组首地址(默认为空)写入该TCP流记录存储空间中,之后反馈该TCP流记录的报文确认号以及访问该流记录的数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址,最后将上述数据包的源、目的IP地址写入快表中的CAM,另外以该CAM地址作为地址访问SRAM,将该流记录首地址写入SRAM,从而达到更新快表的目的;若SYN=0,则执行S24;
S24.根据哈希取模结果访问对应双向循环链表,若找到流记录,则判断TCP复位,若RST=1,则将该TCP流记录首地址和对应乱序数据包(若有)组首地址以及对应的分块数据包组(若有)首地址分别写入指定FIFO以示清除,从而解决存储空间不够用的情况,若RST=0,则执行S25;若没有找到流记录,则不做任何处理;
S25.反馈该TCP流记录的报文确认号以及访问该流记录的数据包的报文序号及确认号,同时反馈该TCP流记录中乱序数据包组首地址,最后将上述数据包的源、目的IP地址写入快表中的CAM,另外以该CAM地址作为地址访问SRAM,将该流记录首地址写入SRAM,从而达到更新快表的目的,再判断TCP终止,若FIN=1,则将该TCP流记录首地址和对应乱序数据包(若有)组首地址以及对应的分块数据包组(若有)首地址分别写入指定FIFO以示清除,尽量解决存储空间不够用的情况,否则不做任何处理;
需要指出的是:S22中快表访问与S23、S24与S25组成的哈希双向链表访问流记录为并发执行,为了描述方便记为S22、S23、S24、S25;其中快表由CAM与SRAM组成,保存有512条最近TCP流访问记录,而且采取先入先出策略,另外S22中快表访问流记录优先,若访问流记录命中,则结束哈希双向循环链表访问流记录;根据哈希取模结果(因快表占用部分存储空间,需加上偏移量512)访问剩余SRAM空间,得到流记录存储在SDRAM(Synchronous Dynamic Random Access Memory,同步动态随机存储器)的首地址,在此给出实施例从节点中64MB SDRAM存储器内容组织,分配16MB存储512K条流记录,分配2MB存储大约21K个乱序数据包组,分配128KB存储大约10K个分块数据包组,分配42MB存储84K个乱序数据块,剩余部分留作它用。
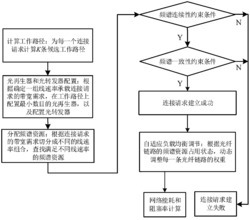
S3.TCP流重组,对TCP流中的乱序数据包分配对应存储空间并对其重组,从而使得该TCP流的数据包整体有序。参见图3与图5,具体包括如下步骤:
S31.比较流记录确认号与访问流记录的数据包的TCP报文序号,若确认号等于报文序号,则为按序到来的数据包,然后用上述数据包的报文确认号更新流记录中确认号,同时更新其时间标记并将该按序数据包发出;否则,执行S32;
S32.根据乱序数据包组首地址访问乱序数据包组(采用静态链表来组织),考虑到乱序数据包的报文间隔数,该乱序数据包组拥有4个元素,即可以存储4个乱序数据包,将该乱序数据包的报文序号、确认号与数据包长度写入该静态链表中,然后判断该数据包大小与额定存储块的大小,考虑到骨干网络上报文的平均长度,选择额定存储块大小为512B,若该数据包大小大于额定存储块大小,则分配存储空间,将该数据包分块,并采用分块数据包组(采用数组来组织)维护上述分块;否则,执行S33;
S33.按确认号先后顺序维护静态链表,进而实现TCP流重组,并更新流记录中乱序数据包组首地址,然后判断链表首部数据包中报文序号与流记录中的确认号,若上述报文序号等于流记录确认号,则乱序数据包已经重组为有序的数据包,将该数据包的存储空间首地址以及分块数据包(若有)首地址分别存储于对应FIFO中以示清除,尽量解决存储空间不够用的情况,之后用上述数据包的报文确认号更新流记录中确认号,同时更新其时间标记并将该按序数据包发出;否则,不做任何处理;
需要指出的是:所述步骤S32中对于乱序数据包组中有数据包长度超过额定块大小时,才采用静态链表与数组共同维护乱序数据包,一般的乱序数据包则仅采用静态链表来维护。
S4.TCP流记录超时检测,周期性地访问每一条哈希双向循环链表,比较该TCP流记录时间标记与当前时间标记,删除超时的TCP流记录,并重新维护该哈希双向循环链表。周期时间设置为2.5h。
需要指出的是:所述步骤S4与S1、S2、S3并发执行,为描述方便记为S1、S2、S3与S4。
以上内容是结合具体的实施方式对本发明的进一步详细说明,不能认定本发明的具体实施方式仅限于此,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单的推演或替换,都应该视为属于本发明的权利要求书的保护范围。
基于FPGA的分级并行高速网络TCP流重组方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。









动态评分
0.0