









专利摘要
本发明公开一种并行网络流量分类方法,基于Hadoop集群平台提供的MapReduce并行框架,先对数据集进行预处理,通过特征选择方法对高维网络流量数据降维,去除不相关以及冗余特征;然后通过选择性集成学习训练多个基分类器,选出其中准确率高以及差异性大的基分类器集成;最后通过多数投票方式得出最终分类结果。本发明能够有效的解决海量数据降维及分类问题,很大程度上提高了数据处理效率。
权利要求
1.一种并行网络流量分类方法,包括对网络流量数据进行特征选择过程S1和对网络流量分类得到分类结果过程S2,其特征是,上述网络流量数据进行特征选择的过程S1具体如下:
S1-1.将初始数据DA处理成特征向量后,按照设定的向量个数a将其划分为a份特征向量子集,且所有类标签作为单独一个类标签向量C;
S1-2.启动映射任务,将a份特征向量子集Y均分到a个映射任务节点上,并将类标签向量C传到这a个映射任务节点;
S1-3.根据费舍尔得分Fk与类标签互信息标准化值SU(x,C),从各特征向量中预选出鉴别能力强与相关性大的特征向量,整合预选出的特征向量得到整合特征向量子集S,并将整合特征向量子集S与类标签向量C一起发送到规约任务节点上;
S1-4.启动规约任务,规约任务节点计算整合特征向量子集S的每个特征向量与类标签向量的类标签互信息标准化值SU(x,C);
S1-5.初始化优选特征向量子集V,选取整合特征向量子集S中类标签互信息标准化值SU(x,C)最大的特征向量加入优选特征向量子集V,并从整合特征向量子集S中删除该特征向量;
S1-6.再选取整合特征向量子集S中类标签互信息标准化值SU(x,C)最大的特征向量,计算该特征向量与优选特征向量子集V中其它特征向量的特征互信息标准化值SU(x,x’),如果该特征向量存在特征互信息标准化值SU(x,x’)大于类标签互信息标准化值SU(x,C)的情形,则从整合特征向量子集S中删除该特征向量,否则将该特征向量加入到优选特征向量子集中;
S1-7.重复步骤S1-6,直到整合特征向量子集S为空,此时整合优选特征向量子集V与类标签向量C构成训练集L输出到后续对网络流量分类得到分类结果过程S2中。
2.根据权利要求1所述的一种并行网络流量分类方法,其特征是,步骤S1-3中,鉴别能力强与相关性大的特征的预选过程如下:
S1-31.根据费舍尔得分公式计算每个特征向量的费舍尔得分Fk;
式中,i表示类别,c表示类的数量,ni表示第i类样本的数量, 表示第i类中第k个特征的均值, 表示所有样本中第k个特征的均值, 表示第i类中第k个特征的方差;
S1-32.根据互信息的标准化公式计算每个特征向量与类标签向量的类标签互信息标准化值SU(x,C);
式中,H(x)表示特征向量x的信息熵,H(C)表示类标签向量C的信息熵,I(x,C)表示特征向量x与类标签向量C的联合熵;
S1-33.根据给定的权重系数α,将上述两个公式融合得到目标评价函数Tk;
Tk=α×Fk+(1-α)×SU(x,C)
S1-34.选出各特征向量子集Y中目标评价函数Tk大于预设阈值的特征向量,并将特征向量进行整合后得到整合特征向量子集S。
3.根据权利要求1所述的一种并行网络流量分类方法,其特征是,步骤S1-4中的类标签互信息标准化值SU(x,C)和步骤S1-6中的特征互信息标准化值SU(x,x’)的计算公式分别为:
式中,H(x)表示特征向量x的信息熵,H(x’)表示特征向量x’的信息熵,H(C)表示类标签向量C的信息熵,I(x,C)表示特征向量x与类标签向量C的联合熵,I(x,x’)表示特征向量x与特征向量x’的联合熵。
4.根据权利要求1所述的一种并行网络流量分类方法,其特征是,上述对网络流量分类得到分类结果的过程S2具体如下:
S2-1.对经过特征选择之后的训练集L按样本向量化,按设定的向量个数s重复抽样s份作为样本训练集,随机抽取其中的一份作为测试集;
S2-2.再次启动映射任务,将划分后的s-1份样本训练集均分到s-1个映射任务节点上,并将测试集传到这s-1个映射任务节点;
S2-3.对每个样本训练集训练一个基分类器,用测试集分别测试各基分类器得到该基分类器的预测类标签向量;将预测类标签向量中的类标签与实际的类标签向量中的类标签逐一进行比较,获得每个基分类器的分类准确率;选出分类准确率大于设定阈值的基分类器,将被选基分类器、该基分类器对应的分类准确率和预测类标签向量一起传送到规约任务节点;
S2-4.再次启动规约任务,根据不一致性度量公式计算各基分类器的差异性值dij,选出差异性大的基分类器集成为分类器集;
S2-5.通过多数投票方式,用得到的分类器集对测试集进行分类。
5.根据权利要求4所述的一种并行网络流量分类方法,其特征是,步骤S2-4具体如下:
S2-41.根据不一致性度量公式计算两个基分类器di和dj之间的差异dij;
式中,N00和N11分别表示2个基分类器di与dj均预测错误与均预测正确的样本数目,N01表示基分类器di预测错误而基分类器dj预测正确的样本数目,N10表示基分类器di预测正确而基分类器dj预测错误的数目;
S2-42.度量n个基分类器间的差异,可得基分类器差异性矩阵Div;
式中,dij表示基分类器di与dj的差异性值;
S2-43.根据下式计算每个基分类器di在整体基分类器的差异性值 ;
式中,dij表示基分类器di与dj的差异性值,n表示基分类器的个数;
S2-44.整合上述3个公式得到基分类器差异性矩阵Ds;
式中, 表示基分类器di在整体基分类器的差异性值,i=1,2,...,n,n表示基分类器的个数;
S2-45.根据下公式计算整体基分类器的平均差异性值AV;
式中, 表示基分类器di在整体基分类器的差异性值,i=1,2,...,n,n表示基分类器的个数;
S2-46.将基分类器差异性矩阵Ds中各基分类器的差异性 与平均差异性值AV比较,当 ,则选中该基分类器di参与最后的集成预测。
6.根据权利要求5所述的一种并行网络流量分类方法,其特征是,步骤S2-41中dij的值的变化范围在[0,1]之间,dij值越大,表示基分类器间的差异性越大。
说明书
技术领域
本发明属于数据处理技术领域,具体涉及一种并行网络流量分类方法。
背景技术
随着高速网络的迅速发展,新型网络业务不断涌现,网络规模因其开放性、共享性等特点不断地扩大,不同的应用流量呈现不同特征,日趋严重的网络安全以及网络服务质量问题给网络流量分类领域带来巨大的挑战。网络流量分类是认识、管理和优化各种网络资源的重要依据,它将基于TCP/IP协议的Internet产生的双向TCP流或UDP流按照网络应用类型(例如WWW、FTP、MAIL、P2P等)进行分类。
网络流量特征选择作为流量分类的关键步骤,在损失较少信息的情况下,从大量候选特征属性中删除无关或冗余的特征,降低候选特征维数,减少训练时间和计算复杂度,提高学习算法效率及分类的精度。虽然特征选择从研究之初到现在,已有很多成熟的方法,但是关于网络流量方面的特征选择方法研究较少。
在网络流量分类算法方面,基于流统计特征的机器学习方法成为主流,大多数基于流统计特征的机器学习方法均使用单个基分类器处理流量分类问题,而其缺陷在于难以适应网络环境的动态变化,在不同环境下的分类效果差距较大。集成学习通过对样本学习训练出若干个基分类器,然后根据某种规则将这些分类结果进行整合以解决某一具体问题。而大量研究发现,选择部分基分类器进行集成学习比选择所有的基分类器具有更好的泛化性,这种方法被称为选择性集成。基分类器选择性集成学习目的在于不降低甚至进一步提高基分类器预测精度的前提下,尽可能减少参与集成学习的基分类器数目。
尽管结合特征选择方法与选择性集成思想可以很大程度上提高分类准确率并体现出较好的泛化性,但随着数据采集和数据存储技术的飞速发展,网络流量数据集规模越来越大,单一的计算节点资源已不能高效快速的解决分类问题,数据存储方式的变化对分类算法的计算效率、并行性和分布化都提出了要求。
发明内容
本发明所要解决的是目前单一计算节点资源不能高效解决大规模数据处理的问题而提供一种并行网络流量分类方法。
为解决上述问题,本发明是通过以下技术方案实现的:
一种并行网络流量分类方法,包括对网络流量数据进行特征选择过程S1和对网络流量分类得到分类结果过程S2。
上述网络流量数据进行特征选择的过程S1具体如下:
S1-1.将初始数据DA处理成特征向量X后,按照设定的向量个数a将其划分为a份特征向量子集Y,且所有类标签作为单独一个类标签向量C;
S1-2.启动映射任务,将a份特征向量子集Y均分到a个映射任务节点上,并将类标签向量C传到这a个映射任务节点;
S1-3.根据费舍尔得分Fk与类标签互信息标准化值SU(x,C),从各特征向量X中预选出鉴别能力强与相关性大的特征向量,整合预选出的特征向量得到整合特征向量子集S,并将整合特征向量子集S与类标签向量C一起发送到规约任务节点上;
S1-4.启动规约任务,规约任务节点计算整合特征向量子集S的每个特征向量与类标签向量C的类标签互信息标准化值SU(x,C);
S1-5.初始化优选特征向量子集V,选取整合特征向量子集S中类标签互信息标准化值SU(x,C)最大的特征向量加入优选特征向量子集V,并从整合特征向量子集S中删除该特征向量;
S1-6.再选取整合特征向量子集S中类标签互信息标准化值SU(x,C)最大的特征向量,计算该特征向量与优选特征向量子集V中其它特征向量的特征互信息标准化值SU(x,x’),如果该特征向量存在特征互信息标准化值SU(x,x’)大于类标签互信息标准化值SU(x,C)的情形,则从整合特征向量子集S中删除该特征向量,否则将该特征向量加入到优选特征向量子集V中;
S1-7.重复步骤S1-6,直到整合特征向量子集S为空,此时整合优选特征向量子集V与类标签向量C构成训练集L输出到后续对网络流量分类得到分类结果过程S2中。
步骤S1-3中,鉴别能力强与相关性大的特征的预选过程如下:
S1-31.根据费舍尔得分公式计算每个特征向量的费舍尔得分Fk;
式中,i表示类别,c表示类的数量,ni表示第i类样本的数量, 表示第i类中第k个特征的均值, 表示所有样本中第k个特征的均值, 表示第i类中第k个特征的方差;
S1-32.根据互信息的标准化公式计算每个特征向量与类标签向量的类标签互信息标准化值SU(x,C);
式中,H(x)表示特征向量x的信息熵,H(C)表示类标签向量C的信息熵,I(x,C)表示特征向量x与类标签向量C的联合熵;
S1-33.根据给定的权重系数α,将上述两个公式融合得到目标评价函数Tk;
Tk=α×Fk+(1-α)×SU(x,C)
S1-34.选出各特征向量子集Y中目标评价函数Tk大于预设阈值的特征向量,并将特征向量进行整合后得到整合特征向量子集S。
步骤S1-4中的类标签互信息标准化值SU(x,C)和步骤S1-6中的特征互信息标准化值SU(x,x’)的计算公式分别为:
式中,H(x)表示特征向量x的信息熵,H(x’)表示特征向量x’的信息熵,H(C)表示类标签向量C的信息熵,I(x,C)表示特征向量x与类标签向量C的联合熵,I(x,x’)表示特征向量x与特征向量x’的联合熵。
上述对网络流量分类得到分类结果的过程S2具体如下:
S2-1.对经过特征选择之后的训练集L按样本向量化,按设定的向量个数s重复抽样s份作为样本训练集,随机抽取其中的一份作为测试集;
S2-2.再次启动映射任务,将划分后的s-1份样本训练集均分到s-1个映射任务节点上,并将测试集传到这s-1个映射任务节点;
S2-3.对每个样本训练集训练一个基分类器,用测试集分别测试各基分类器得到该基分类器的预测类标签向量;将预测类标签向量中的类标签与实际的类标签向量中的类标签逐一进行比较,获得每个基分类器的分类准确率;选出分类准确率大于设定阈值的基分类器,将被选基分类器、该基分类器对应的分类准确率和预测类标签向量一起传送到规约任务节点;
S2-4.再次启动规约任务,根据不一致性度量公式计算各基分类器的差异性值dij,选出差异性大的基分类器集成为分类器集;
S2-5.通过多数投票方式,用得到的分类器集对测试集进行分类。
步骤S2-4具体如下:
S2-41.根据不一致性度量公式计算两个基分类器di和dj之间的差异dij;
式中,N00和N11分别表示2个基分类器di与dj均预测错误与均预测正确的样本数目,N01表示基分类器di预测错误而基分类器dj预测正确的样本数目,N10表示基分类器di预测正确而基分类器dj预测错误的数目;
S2-42.度量n个基分类器间的差异,可得基分类器差异性矩阵Div;
式中,dij表示基分类器di与dj的差异性值;
S2-43.根据下式计算每个基分类器di在整体基分类器的差异性值
式中,dij表示基分类器di与dj的差异性值,n表示基分类器的个数;
S2-44.整合上述3个公式得到基分类器差异性矩阵Ds;
式中, 表示基分类器di在整体基分类器的差异性值,i=1,2,…,n,n表示基分类器的个数;
S2-45.根据下公式计算整体基分类器的平均差异性值AV;
式中, 表示基分类器di在整体基分类器的差异性值,i=1,2,…,n,n表示基分类器的个数;
S2-46.将基分类器差异性矩阵Ds中各基分类器的差异性 与平均差异性值AV比较,当 则选中该基分类器di参与最后的集成预测。
步骤S2-41中dij的值的变化范围在[0,1]之间,dij值越大,表示基分类器间的差异性越大。
与现有技术相比,本发明的有益效果在于:
(1)通过特征选择剔除大量无关的、冗余的特征,实现高维数据的降维,可以提高基分类器的分类准确率;
(2)基于Hadoop集群环境和MapReduce并行计算模型可以提高特征选择和训练基分类器的效率。
附图说明
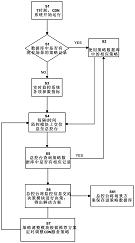
图1是基于互信息与集成学习的并行网络流量分类方法的总流程图。
图2是图1中网络流量特征选择过程的流程图。
图3是图1中网络流量分类过程的流程图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明。
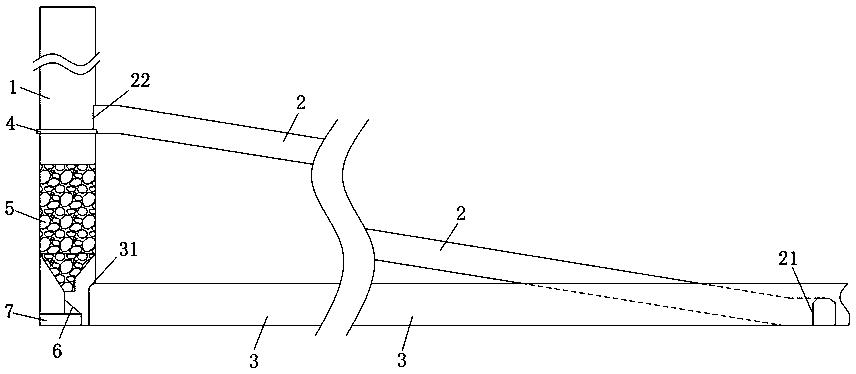
一种并行网络流量分类方法,如图1所示,其通过两个Map-Reduce过程完成:第一个Map-Reduce过程对网络流量数据进行特征选择,剔除不相关及冗余性大的特征;第二个Map-Reduce过程采用选择性集成学习算法对网络流量分类得到分类结果。
如图2所示,基于MapReduce并行框架的网络流量特征选择的过程,先通过费舍尔得分与类标签互信息标准化值预选出鉴别能力较强、相关性较高的特征向量子集,然后通过特征互信息标准化值剔除被选特征向量子集中的冗余特征。
S1-1.数据预处理,将初始数据DA={d1,d2,…,dn}(例如Moore-set,其中di为训练样本,每个样本共249种特征,其中最后一个特征为类标签)处理成特征向量形式X={x1,x2,…,xm}。
按设定的向量个数a划分为a(a<248)份特征向量子集Y={y1,y2,…,yl}(yi∈X,=1,2…l,l<m)。
另外,数据通过预处理之后还剩10个类别:即
"WWW","SERVICES","P2P","MULTIMEDIA","MAIL","FTP-PASV","FTP-DAT A","FTP-CONTROL",DATABASE","ATTACK",
作为单独一个向量,即类标签向量C={c1,c2,…,cn}(第249个特征,ci为xi的类标签。
S1-2.数据部署,在Hadoop平台的各个节点启动Map任务(简称Mapper),将划分后的a份特征向量子集Y均分到a个Mapper节点,并将类标签向量C传到这a个Mapper节点;其传送形式为<key,value>键值对,key值为特征子集向量,value值为类标签向量C。
S1-3.根据费舍尔得分Fk与类标签互信息标准化值SU(x,C),从特征向量子集Y中预选出鉴别能力强与相关性大的特征,整合预选出的特征向量得到整合特征向量子集S,将整合特征向量子集S与类标签向量C一起发送到Reduce任务节点上;其传送形式<key,value>键值对中,key值为整合特征子集向量S,value值为类标签向量C。
S1-31.根据费舍尔得分公式(1)计算每个特征向量的费舍尔得分Fk,其中,类标签i表示类别,c表示类的数量,ni表示第类样本的数量, 表示第i类中第k个特征的均值, 表示所有样本中第k个特征的均值, 表示第i类中第k个特征的方差;
S1-32.根据信息熵公式(2)计算每个特征向量和类标签向量的信息熵,其中,i表示类别,c表示类的数量,p表示出现的概率;
S1-33.根据联合熵公式(3)计算每个特征与类标签向量的联合熵,其中,i,j表示类别,h,c表示类的数量,p表示出现的概率;
S1-34.根据互信息公式(4)计算每个特征向量与类标签向量的互信息;
I(x,C)=H(x)+H(C)-H(x,C) (4)
S1-35.根据互信息的标准化形式(Symmetrical uncertainty,SU)(5)计算每个特征向量与类标签向量的互信息标准化值,其中,H(x)表示特征向量x的信息熵,H(C)表示类标签向量C的信息熵,I(x,C)表示特征向量x与类标签向量C的联合熵;
S1-36.根据费舍尔得分与互信息的标准化形式这两种算法的不同特性,给F和SU分配一个权重系数α。融合公式(1)和(5)得到目标评价函数Tk,根据公式(6)计算每个特征向量的值,当Tk的值越大,表示第k个特征有更好的区分度和类别相关性,选出Tk较大的特征。
Tk=α×Fk+(1-α)×SU(x,C) (6)
需要指出的是:所述步骤S1-36根据目标评价函数计算第k特征向量的值Tk时,权重系数α根据具体的Fk和SU值大小而定(当Fk起主导作用时增加Fk权重,反之增加SU的权重),对Tk值进行排序,选出Tk值较大的特征。
S1-4.启动Reduce任务(简称Reducer),Reducer节点计算整合特征向量子集S的每个特征向量与类标签向量的类标签互信息标准化值SU(x,C)。
S1-5.初始优选特征向量子集V,选取整合特征向量子集S中类标签互信息标准化值SU(x,C)值最大的特征向量加入优选特征向量子集V,并从整合特征向量子集S中删除该特征向量。
S1-6.再选取整合特征向量子集S中类标签互信息标准化值SU(x,C)值最大的特征,计算该特征向量与优选特征向量子集V中其它特征向量的特征互信息标准化值SU(x,x’)值,如果该特征向量存在特征互信息标准化值SU(x,x’)值大于类标签互信息标准化值SU(x,C)值,则从整合特征向量子集S删除该特征向量,否则将该特征向量加入优选特征向量子集V。
S1-7.重复步骤S1-6,直到整合特征向量子集S为空,得到的最优特征向量子集V,整合特征向量子集V与类标签向量C作为训练集L输出到后续网络流量分类过程中;其输出形式<key,value>键值对中,key值为被选特征向量名称,value值为训练集L)。
需要指出的是:所述步骤S1-4中的类标签互信息标准化值SU(x,C)和步骤S1-6中的特征互信息标准化SU(x,x’)均通过步骤S1-3中的公式(2)-(5)计算得出。只是步骤S1-6中的特征互信息标准化SU(x,x’)需要将类标签向量C的信息熵H(C)替换成特征向量x’的信息熵H(x’),特征向量x与类标签向量C的联合熵I(x,C)替换成特征向量与特征向量的联合熵I(x,x’)。
如图3所示,基于选择性集成学习思想对网络流量分类的过程,针对通过特征选择之后训练集L训练出多个基分类器,选出其中准确率高、差异性大的基分类器集成为分类器集,最终分类结果通过该分类器集采用多数投票方式所得,其具体步骤如下:
S2-1.对经过特征选择之后的数据集L={l1,l2,…,ln}按样本向量化,按设定的向量个数s重复抽样s份作为样本训练集(取数据集的1%作为一个训练样本),随机抽取其中一份作为测试集Y。
S2-2.再次启动Mapper,将划分后的s-1份样本训练集均分到s-1个Mapper节点,并将测试集传到这s-1个映射任务节点;其输入形式为<key,value>键值对,key值为偏移量,value值为训练样本集、测试集。
S2-3.对每个样本集训练一个基分类器ci,用测试集分别测试各基分类器得到该基分类器的预测类标签向量A={A1,A2,…,As-1},其中Ai为基分类器ci的预测类标签向量;将预测类标签向量与实际的类标签向量中的每个元素进行逐一对比,如果预测类标签向量里面存在有与类标签向量中元素不一样的,说明预测错误,由此获得该基分类器的分类准确率,选出准确率大于设定阈值γ的基分类器,将被选基分类器、其准确率以及与其对应的预测类标签向量以<key,value>形式传送到Reducer端,key值为被选基分类器准确率,value值为预测类标签向量和被选基分类器。
S2-4.再次启动Reduce任务,Reducer端接收Mapper传送的数据,根据不一致性度量公式计算各基分类器的差异性值dij,选出差异性较大的基分类器集成为分类器集输出;其输出的<key,value>键值对中,key值为差异性值,value值为分类器集。
S2-41.根据不一致性度量公式(7)计算两个基分类器di和dj之间的差异,其中,N00和N11分别表示两个基分类器均预测错误与均预测正确的样本数目,N01表示基分类器di预测错误而基分类器dj预测正确的样本数目,N10表示基分类器di预测正确而基分类器dj预测错误的数目,dij的值的变化范围在[0,1]之间,dij值越大,表示基分类器间的差异性越大;
S2-42.度量n个基分类器间的差异,可得基分类器差异性矩阵Div,其中,dij表示基分类器di与dj的差异性值,如公式(8)所示;
S2-43.根据公式(9)计算每个基分类器di在整体基分类器的差异性值 其中,dij表示基分类器di与dj的差异性值,n表示基分类器的个数;
S2-44.整合公式(8)-(9)得到基分类器差异性矩阵Ds,其中, 表示基分类器di在整体基分类器的差异性值,i=1,2,…,n,n表示基分类器的个数,如公式(10)所示;
S2-45.根据公式(11)计算整体基分类器的平均差异性值AV,其中, 表示基分类器di在整体基分类器的差异性值,i=1,2,…,n,n表示基分类器的个数;
S2-46.将基分类器差异性矩阵中各基分类器的差异性 与平均差异性值AV比较,当 则选中该基分类器di参与最后的集成预测。
S2-5.通过多数投票方式,用得到的分类器集对测试集进行分类。
一种并行网络流量分类方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。








动态评分
0.0