










专利摘要
本发明公开了一种基于多层级关系的分布式数据管理方法,属于计算机数据信息存储技术领域。该方法包括以下步骤:建立中介层,中介层分别与源数据库和客服端连接;将分布式的各源数据库的访问接口统一规范,封装成统一的规范封装接口包,在中介层中创建数据访问模块,将规范封装接口包植入数据访问模块中;根据源数据库信息实现中介层的全局信息同步,在中介层中建立数据集成模块;在中介层中建立逻辑分层模块,所述逻辑分层模块为联系实际系统对象的物理分层及实际系统对象的功能逻辑分层;在中介层中形成标准对外接口,规范其应用标准。本方法降低了数据冗余,提高了访问效率,建立起一种具有通用性,且可扩展的管理体系架构。
权利要求
1.一种基于多层级关系的分布式数据管理方法,其特征在于:包括以下步骤:
步骤一:建立中介层,中介层分别与源数据库和客服端连接;
步骤二:将分布式的各源数据库的访问接口统一规范,封装成统一的规范封装接口包,在中介层中创建数据访问模块,将规范封装接口包植入数据访问模块中;
步骤三:根据源数据库信息实现中介层的全局信息同步,在中介层中建立数据集成模块,所述数据集成模块将分布式数据库中的源数据形成一体化的信息集成数据平台,形成无间隙无冗余的融合数据体;
步骤四:在中介层中建立逻辑分层模块,所述逻辑分层模块为联系实际系统对象的物理分层及实际系统对象的功能逻辑分层;
步骤五:在中介层中形成标准对外接口,规范其应用标准。
2.根据权利要求1所述的基于多层级关系的分布式数据管理方法,其特征在于:步骤二中植入数据访问模块的规范封装接口用于完成数据源的添加,删除,各分布式数据源信息的查询,对分布式数据系统的SQL语句查询。
3.根据权利要求2所述的基于多层级关系的分布式数据管理方法,其特征在于:经SQL语句串对底层各数据源进行查询,把结果集进行类型转换,合并,建立集成规则,形成读取数据融合协议,并把融合数据返回给用户,数据访问模块通过读取数据融合协议访问分布式数据库。
4.根据权利要求1所述的基于多层级关系的分布式数据管理方法,其特征在于:步骤三中采用以下方式实现中介层的全局信息规范同步:在每个节点的节点注册信息中登记数据库待同步的源节点和目标节点;依据所述节点注册信息完成源节点的数据库与目标节点的数据库之间的数据同步。
5.根据权利要求4所述的基于多层级关系的分布式数据管理方法,其特征在于:依据所述节点注册信息完成源节点的数据库与目标节点的数据库之间的数据同步的具体步骤包括:通过查找源节点的节点注册信息来确定与源节点同步的目标节点;完成所述源节点的数据库向目标节点的数据库的数据同步。
6.根据权利要求4所述的基于多层级关系的分布式数据管理方法,其特征在于:所述数据集成模块用于维持融合数据空间和各局部异构数据源之间的映射关系,并记录各数据源的物理位置,以保证对分布的各数据源的正确访问。
7.根据权利要求6所述的基于多层级关系的分布式数据管理方法,其特征在于:数据集成模块对各异构数据表的集成规则如下:系统只按照表的名字对表进行集成分类,如果两个数据源中具有同名表,那么就认为在融合数据系统中这是一个表,即用户在融合数据库系统中对这个表进行的操作将在底层被映射成对这两个不同数据源同名表的操作。
8.根据权利要求1所述的基于多层级关系的分布式数据管理方法,其特征在于:步骤四中逻辑分层模块的建立具体包括:建立信息系统的拓扑结构图;建立拓扑结构图中节点;建立节点间有向关系边;建立关系边的权值。
9.根据权利要求8所述的基于多层级关系的分布式数据管理方法,其特征在于:建立拓扑图时采用多层级聚类算法:定义子图之间的相似度;图中每个节点初始为一个子图,然后计算每个子图之间的相似度,将相似度最高的子图合并成一个子图;新的子图作为图的第二层级结构;计算所有子图的相似度,合并相似度更高的子图,形成更高级的层级,不断重复此过程,直到到达分层结束条件,由此获得整个图的多层级结构。
10.根据权利要求9所述的基于多层级关系的分布式数据管理方法,其特征在于:加入动态聚类的多层级算法,降低图的层级间的耦合度,提高多层级结构的适应性。
说明书
技术领域
本发明属于计算机数据信息存储技术领域,涉及一种基于多层级关系的分布式数据管理方法。
背景技术
在信息系统中,面向的实体对象往往结构复杂,数据庞大,呈现多层级,多节点关系的特点,而系统复杂性通常也使得系统采用多种、多数量、不同类型的数据库分布式结构,这些特点使得数据管理上出现访问数据残缺,更新数据实时性差,数据权限管理漏洞多,数据使用效率低下等问题。
为了提高复杂信息系统的使用效率,通常采用融合分布式数据库的办法,使多类型、多数量的数据库形成统一标准规范下的整体数据库,这样就解决了数据库在数据冗余与数据更新方面的问题,使得数据库形成一个整体,并达到任意读取的目的。
但是数据融合后,系统不能体现分布式数据系统的特点,使系统的使用效率提升不大,为了使网络效率更高,需要使系统数据呈现出明显的结构特征。
因此,目前需要一种既能够保持分布式数据库系统的融合性,又能够提升系统使用效率的分布式数据管理方法。
发明内容
有鉴于此,本发明的目的在于提供一种基于多层级关系的分布式数据管理方法,该方法采用数据库融合技术和层次聚类算法对分布式数据库进行处理,从而使复杂系统的数据使用效率更高,消除了冗余数据,达到了更新数据准确,层级权限管理更加清晰的目的。
为达到上述目的,本发明提供如下技术方案:
一种基于多层级关系的分布式数据管理方法,包括以下步骤:步骤一:建立中介层,中介层分别与源数据库和客服端连接;步骤二:将分布式的各源数据库的访问接口统一规范,封装成统一的规范封装接口包,在中介层中创建数据访问模块,将规范封装接口包植入数据访问模块中;步骤三:根据源数据库信息实现中介层的全局信息同步,在中介层中建立数据集成模块,所述数据集成模块将分布式数据库中的源数据形成一体化的信息集成数据平台,形成无间隙无冗余的融合数据体;步骤四:在中介层中建立逻辑分层模块,所述逻辑分层模块为联系实际系统对象的物理分层及实际系统对象的功能逻辑分层;步骤五:在中介层中形成标准对外接口,规范其应用标准。
进一步,步骤二中植入数据访问模块的规范封装接口用于完成数据源的添加,删除,各分布式数据源信息的查询,对分布式数据系统的SQL语句查询。
进一步,经SQL语句串对底层各数据源进行查询,把结果集进行类型转换,合并,建立集成规则,形成读取数据融合协议,并把融合数据返回给用户,数据访问模块通过读取数据融合协议访问分布式数据库。
进一步,步骤三中采用以下方式实现中介层的全局信息规范同步:在每个节点的节点注册信息中登记数据库待同步的源节点和目标节点;依据所述节点注册信息完成源节点的数据库与目标节点的数据库之间的数据同步。
进一步,依据所述节点注册信息完成源节点的数据库与目标节点的数据库之间的数据同步的具体步骤包括:通过查找源节点的节点注册信息来确定与源节点同步的目标节点;完成所述源节点的数据库向目标节点的数据库的数据同步。
进一步,所述数据集成模块用于维持融合数据空间和各局部异构数据源之间的映射关系,并记录各数据源的物理位置,以保证对分布的各数据源的正确访问。
进一步,数据集成模块对各异构数据表的集成规则如下:系统只按照表的名字对表进行集成分类,如果两个数据源中具有同名表,那么就认为在融合数据系统中这是一个表,即用户在融合数据库系统中对这个表进行的操作将在底层被映射成对这两个不同数据源同名表的操作。
进一步,步骤四中逻辑分层模块的建立具体包括:建立信息系统的拓扑结构图;建立拓扑结构图中节点;建立节点间有向关系边;建立关系边的权值。
进一步,建立拓扑图时采用多层级聚类算法:定义子图之间的相似度;图中每个节点初始为一个子图,然后计算每个子图之间的相似度,将相似度最高的子图合并成一个子图;新的子图作为图的第二层级结构;计算所有子图的相似度,合并相似度更高的子图,形成更高级的层级,不断重复此过程,直到到达分层结束条件,由此获得整个图的多层级结构。
进一步,加入动态聚类的多层级算法,降低图的层级间的耦合度,提高多层级结构的适应性。
本发明的有益效果在于:本发明提供的数据管理方法简化了分布式数据的管理,降低了数据冗余,提高了访问效率,建立起一种具有通用性,且可扩展的管理体系架构。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
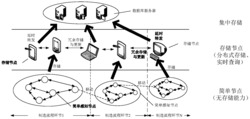
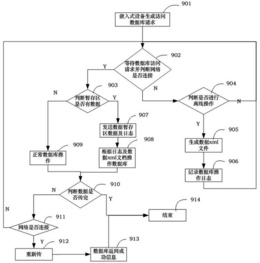
图1为多层级关系的分布式数据管理系统结构图;
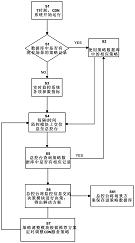
图2为本发明所述方法的设计流程图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
图1为多层级关系的分布式数据管理系统结构图,图2为本发明所述方法的设计流程图。
本发明的基于多层级关系的分布式数据管理方法包括以下具体步骤:步骤一:建立中介层,中介层分别与源数据库和客服端连接;步骤二:将分布式的各源数据库的访问接口统一规范,封装成统一的规范封装接口包,在中介层中创建数据访问模块,将规范封装接口包植入数据访问模块中。步骤三:根据源数据库信息实现中介层的全局信息同步,在中介层中建立数据集成模块,所述数据集成模块将分布式数据库中的源数据形成一体化的信息集成数据平台,形成无间隙无冗余的融合数据体。步骤四:在中介层中建立逻辑分层模块,所述逻辑分层模块为联系实际系统对象的物理分层及实际系统对象的功能逻辑分层;步骤五:在中介层中形成标准对外接口,规范其应用标准。
其中,步骤二中植入数据访问模块的规范封装接口用于完成数据源的添加,删除,各分布式数据源信息的查询,对分布式数据系统的SQL语句查询。经SQL语句串对底层各数据源进行查询,把结果集进行类型转换,合并,建立集成规则,形成读取数据融合协议,并把融合数据返回给用户,数据访问模块通过读取数据融合协议访问分布式数据库。
步骤三中采用以下方式实现中介层的全局信息规范同步:在每个节点的节点注册信息中登记数据库待同步的源节点和目标节点;依据所述节点注册信息完成源节点的数据库与目标节点的数据库之间的数据同步。依据所述节点注册信息完成源节点的数据库与目标节点的数据库之间的数据同步的具体步骤包括:通过查找源节点的节点注册信息来确定与源节点同步的目标节点;完成所述源节点的数据库向目标节点的数据库的数据同步。
所述数据集成模块用于维持融合数据空间和各局部异构数据源之间的映射关系,并记录各数据源的物理位置,以保证对分布的各数据源的正确访问。
数据集成模块对各异构数据表的集成规则如下:系统只按照表的名字对表进行集成分类,如果两个数据源中具有同名表,那么就认为在融合数据系统中这是一个表,即用户在融合数据库系统中对这个表进行的操作将在底层被映射成对这两个不同数据源同名表的操作。
步骤四中逻辑分层模块的建立具体包括:建立信息系统的拓扑结构图;建立拓扑结构图中节点;建立节点间有向关系边;建立关系边的权值。
建立拓扑图时采用多层级聚类算法:定义子图之间的相似度;图中每个节点初始为一个子图,然后计算每个子图之间的相似度,将相似度最高的子图合并成一个子图;新的子图作为图的第二层级结构;计算所有子图的相似度,合并相似度更高的子图,形成更高级的层级,不断重复此过程,直到到达分层结束条件,由此获得整个图的多层级结构。
同时,在本方法中加入动态聚类的多层级算法,降低图的层级间的耦合度,提高多层级结构的适应性。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
一种基于多层级关系的分布式数据管理方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。











动态评分
0.0