










专利摘要
本发明公开了一种基于强化学习的水下机器人控制方法及其进行跟踪的控制方法,属于水下机器人控制领域。本发明中控制中心给出水下机器人的期望轨迹信息,并发送至水下机器人;根据水下机器人模型中不确定参数的概率密度函数,分别对其选取采样点,利用采样点对原始的动力学模型降阶;水下机器人和周围环境进行交互以学习环境信息,在不同状态计算一步代价函数进行价值更新,用最小二乘法求解控制策略对应的价值函数的权重,用梯度下降法进行控制策略改进,循环迭代价值更新和策略改进两个过程直至收敛,从而得到当前位置追踪期望轨迹的最优控制策略;重复以上步骤得到对其余期望轨迹追踪的最优控制策略,最终完成追踪任务。
权利要求
1.一种基于强化学习的水下机器人控制方法,其特征在于,包括以下步骤:
步骤1、为水下机器人自身位置建立基于机器人自身期望轨迹位置的固定参考系,以及建立基于水下环境不确定因素的惯性参考系;
步骤2、对于惯性参考系,在前后、左右、上下三个方向上构建由基于不确定因素的系统映射机器人输出模型:
式中,a
根据不确定因素各自的概率密度函数,为每个不确定因素定点采样,利用采样点对系统映射机器人输出模型进行训练,构建降阶系统映射机器人输出模型:
式中,
步骤3、将水下机器人真实位置转化为步骤1的固定参考系中的坐标,并获取步骤2惯性参考系中的机器人降阶系统映射的模型输出;
步骤4、定义水下机器人在不同的状态k下的真实位置为:
p(k)=[x(k),y(k),z(k)]
定义水下机器人在不同的状态k下的期望轨迹位置为:
p
定义水下机器人在不同状态k下的下一步动作的一步代价函数为
g
其中(x-x
根据水下机器人位置移动产生的一步代价函数对机器人进行训练,获得价值函数
V(p(k))=E
式中,γ∈(0,1)是折扣因子,E
令V=W
W
式中,
步骤5、对控制方法的价值模型求解;令h(p)=U
其中h(p)是水下机器人进行位置追踪时每个状态下所进行的下一步动作,将h(p)作为最优控制策略;
步骤6、利用迭代权重的方法对控制方法的价值模型更新和控制策略改进两个过程的同时收敛,完成对当前状态下最优控制策略的求解;
步骤7、将步骤3中真实位置输入到步骤4中,经过步骤5-6操作,获取下一步动作的最优控制策略,并将其作为输出输入到步骤2的系统映射机器人输出模型中,然后循环重复步骤3、7操作,完成水下机器人的追踪任务。
2.根据权利要求1所述的一种基于强化学习的水下机器人控制方法,其特征在于,所述步骤1中的不确定因素为水下的浪涌、摇摆和升沉。
3.根据权利要求1所述的一种基于强化学习的水下机器人控制方法,其特征在于,所述步骤2中的降阶系统映射机器人输出模型的输出均值E'(G'(a
4.根据权利要求1所述的一种基于强化学习的水下机器人控制方法,其特征在于,所述步骤4的具体步骤如下:
水下机器人在不同状态k下自身位置为p(k)=[x(k),y(k),z(k)]
V(p(k))=E
式中,γ∈(0,1)是折扣因子,E
在价值更新过程中,令V=W
式中,
其中h(p)是由水下机器人学习通过对环境的学习得到的控制策略,此策略即为最优控制策略。
5.根据权利要求1所述的一种基于强化学习的水下机器人控制方法,其特征在于,所述步骤6的具体内容如下:
当每次利用迭代权重的方法对控制方法的价值模型更新和控制策略改进两个过程,得到的权重变化小于阈值0.001时,视为收敛,迭代完成的h作为控制器的输入u输入至水下机器人。
6.一种利用水下机器人进行跟踪的控制方法,其特征在于,将被跟踪物体在水下运动的轨迹作为水下机器人自身期望轨迹,利用权利要求1所述的一种基于强化学习的水下机器人控制方法,对水下机器人进行控制,实现对被跟踪物体的跟踪。
说明书
技术领域
本发明涉及水下机器人控制领域,具体涉及一种基于强化学习的水下机器人控制方法及其进行跟踪的控制方法。
背景技术
随着海洋资源的应用越来越广泛,水下机器人也受到了人们更多的重视。水下机器人在海洋中的一个重要应用就是位置追踪,但水下环境复杂多变,使得水下机器人的模型参数很难获取,控制难度大。
在现有技术中检索发现,公开号为CN106708069A的专利申请设计了一种水下移动作业机器人的协调规划与控制方法。该方法包括通过动态追踪微分器,实时规划当前期望的速度与状态,用迭代任务优先方法将笛卡尔空间的任务规划转化到随体坐标系和各关节坐标系的速度与加速度规划,根据速度与加速度规划,利用动力学方法来控制水下机器人和作业臂,从而使得水下移动作业机器人进行巡游与作业。但此发明没有考虑到水下环境中的不确定性对水下机器人的影响,在海洋环境中,水下机器人在运行中会受到各种干扰,如浪涌、摇摆和升沉的作用力的影响,如果不将这些不确定的因素考虑到算法之中,在实际运行中会达不到理想的效果。
再有,公开号为CN107544256A的专利申请设计了基于自适应反步法的水下机器人滑模控制,本发明提供一种基于自适应反步法的水下机器人滑模控制方法。该方法基于对复杂非线性系统的分解,通过为子系统设计虚拟控制量,结合滑动模态逐级递推得到全系统的控制量,针对系统不确定上界引起的抖振问题,控制器中引入径向基函数神经网络,自适应逼近系统内部不确定性与外部干扰,最终实现对系统抖振的控制,并实现高精度跟踪控制,提高闭环系统鲁棒性,满足工程需求。该发明中所提出的内部不确定性与外部干扰是确定参数,但在实际工作环境中,在考虑会对水下机器人造成干扰的参数时,应将参数设置为时变不确定参数。
发明内容
本发明的目的在于克服上述不足,提出一种基于强化学习的水下机器人控制方法,在准确追踪目标轨迹的同时减少对具有不确定参数系统的采样次数,利用水下机器人对环境的学习实现控制。
为实现上述目的,本发明采用下述技术方案:
一种基于强化学习的水下机器人控制方法,其特征在于,包括以下步骤:
步骤1、为水下机器人自身位置建立基于机器人自身期望轨迹位置的固定参考系,以及建立基于水下环境不确定因素的惯性参考系;
步骤2、对于惯性参考系,在前后、左右、上下三个方向上构建由基于不确定因素的系统映射机器人输出模型:
式中,ai是水下机器人受到的第i个不确定因素, 为系数,每个不确定因素ai都遵循独立的概率密度函数
根据不确定因素各自的概率密度函数,为每个不确定因素定点采样,利用采样点对系统映射机器人输出模型进行训练,构建降阶系统映射机器人输出模型:
式中, 是低阶映射中不确定因素的系数;
步骤3、将水下机器人真实位置转化为步骤1的固定参考系中的坐标,并获取步骤2惯性参考系中的机器人降阶系统映射的模型输出;
步骤4、定义水下机器人在不同的状态k下的真实位置为:
p(k)=[x(k),y(k),z(k)]
定义水下机器人在不同的状态k下的期望轨迹位置为:
pr(k)=[xr(k),yr(k),zr(k)]
定义水下机器人在不同状态k下的下一步动作的一步代价函数为
gk(p,u)=(x(k)-xr(k))
其中(x-xr)
根据水下机器人位置移动产生的一步代价函数对机器人进行训练,获得价值函数
V(p(k))=Ea(k){gk(p,u)+γV(p(k+1))}
式中,γ∈(0,1)是折扣因子,Ea(k)表示状态k下的期望函数;
令V=W
Wj+1Φ(p(k))=Ea(k)[gk(p,u)+γWjΦ(p(k+1))]
式中, 为基向量,W是权重向量;
步骤5、对控制方法的价值模型求解;令h(p)=U
其中h(p)是水下机器人进行位置追踪时每个状态下所进行的下一步动作,将h(p)作为最优控制策略;
步骤6、利用迭代权重的方法对控制方法的价值模型更新和控制策略改进两个过程的同时收敛,完成对当前状态下最优控制策略的求解;
步骤7、将步骤3中真实位置输入到步骤4中,经过步骤5-6操作,获取下一步的最优控制策略,并将其作为输出输入到步骤2的系统映射机器人输出模型中,然后循环重复步骤3、7操作,完成水下机器人的追踪任务。
进一步的技术方案在于,所述步骤1中的不确定因素为水下的浪涌、摇摆和升沉。
进一步的技术方案在于,所述步骤2中的降阶系统映射机器人输出模型的输出均值E'(G'(a1,a2,a3)),与系统映射机器人输出模型的输出均值E(G(a1,a2,a3))相同。
进一步的技术方案在于,所述步骤4的具体步骤如下:
水下机器人在不同状态k下自身位置为p(k)=[x(k),y(k),z(k)]
V(p(k))=Ea(k){gk+γV(p(k+1))}
式中,γ∈(0,1)是折扣因子,Ea(k)表示状态k下的期望函数;
在价值更新过程中,令V=W
式中, 为基向量;W是权重向量,通过最小二乘法迭代求解;得到价值函数后,在策略改进步骤中,同样利用设置基向量和权重向量的方法求解最优追踪控制策略,求解时,令h(p)=U
其中h(p)是由水下机器人学习通过对环境的学习得到的控制策略,此策略即为最优控制策略。
进一步的技术方案在于,所述步骤6的具体内容如下:
当每次利用迭代权重的方法对控制方法的价值模型更新和控制策略改进两个过程,得到的权重变化小于阈值0.001时,视为收敛,迭代完成的h作为控制器的输入u输入至水下机器人。
进一步的技术方案在于,一种利用水下机器人进行跟踪的控制方法,其将被跟踪物体在水下运动的轨迹作为水下机器人自身期望轨迹,上述所述的一种基于强化学习的水下机器人控制方法,对水下机器人进行控制,实现对被跟踪物体的跟踪。
与现有技术相比,本发明具有如下优点:
本发明运用降阶的方法对水下机器人涉及到水下不确定因素的不确定参数进行采样,可以给出精确的原始映射的输出统计量,进而降低计算成本,有效减少模拟次数。
本发明运用强化学习的方法使水下机器人进行位置追踪,综合了自适应和最优控制的优点,利用环境的响应寻求最优反馈策略。利用周围环境信息,通过多次迭代使水下机器人能够通过自身的学习,找到最符合目标轨迹的控制策略。
本发明实现了水下机器人的智能追踪。运用降阶的方法对水下机器人的不确定参数进行采样与强化学习相结合,使水下机器人系统的后向实时最优控制成为前向自适应控制,使得水下机器人能更好的完成轨迹追踪。
附图说明
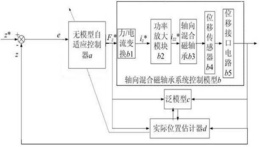
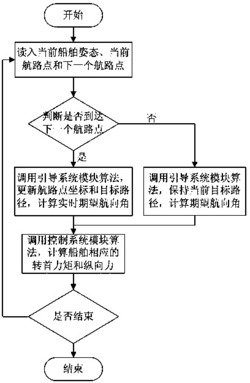
图1是本发明的轨迹追踪流程图。
图2是本发明的水下移动传感器网络结构示意图。
具体实施方式
下面结合附图对本发明做进一步说明:
如图2所示,本发明在水面放有浮标继电器,用其对水下机器人进行自定位,控制中心给出水下机器人的期望轨迹信息,并发送至水下机器人;水下机器人控制器根据系统控制控制驱动器进行驱动,完成水下机器人的运动。
如图1所示,本发明阐述了一种基于强化学习的水下机器人控制方法,其方法包括以下步骤:
步骤一水下机器人在水下受到周围环境的影响,需要对水下机器人模型中的不确定因素进行评估,方可完成水下机器人控制器对驱动器的控制;水下机器人有上、下、左、右、前、后六个自由度,其动力学特性可由两种参考系进行描述,基于机器人自身期望轨迹位置的固定参考系和水下环境不确定因素的惯性参考系。其中固定参考系、惯性参考系均分别考虑上下、左右、前后三个方向,水下的惯性参考系将水下的浪涌、摇摆和升沉等因素作为不确定因素进行不确定参数的引用。
惯性参考系中,浪涌,摇摆和升沉三个方向的线速度两两垂直,同时在线速度的方向上考虑横摇、俯仰和偏航对水下机器人角速度的影响。
步骤二 由于水下环境的随机影响,分别对水下机器人惯性参考系的三个方向上的不确定参数进行估计:根据不确定参数各自的概率密度函数,为每个参数选择一组采样点,利用这些采样点分别进行计算,使机器人模型的阶数减少,从而可以通过较少次数的计算获得控制器输出结果的同时,保证输出均值与原模型的输出均值相同,使水下机器人适应水下环境并且实现更准确的控制。
具体如下:对于惯性参考系,在前后、左右、上下三个方向上构建由基于不确定因素的系统映射机器人输出模型:
ai是水下机器人受到的第i个不确定因素,在本实施例中将水下的浪涌、摇摆和升沉等因素作为不确定因素进行不确定参数的引用。 为系数。每个不确定参数(或称不确定因素)ai都遵循独立的概率密度函数
根据不确定因素各自的概率密度函数,为每个不确定因素定点采样,利用采样点对系统映射机器人输出模型进行训练,构建降阶系统映射机器人输出模型:
其中 是低阶映射中不确定参数新的系数。降阶系统映射机器人输出模型的输出均值E'(G'(a1,a2,a3)),与系统映射机器人输出模型的输出均值E(G(a1,a2,a3))相同,即E'(G'(a1,a2,a3))=E(G(a1,a2,a3))。
步骤三 将水下机器人真实位置转化为步骤1的固定参考系中的坐标,并获取步骤2惯性参考系中的机器人降阶系统映射的模型输出;
步骤四 定义水下机器人在不同的状态k下其自身位置为
p(k)=[x(k),y(k),z(k)]
要进行追踪的期望轨迹为:
pr(k)=[xr(k),yr(k),zr(k)]
为了求得最优控制策略,即水下机器人进行位置追踪时每个状态下所进行的动作h,设置水下机器人在不同状态下的一步代价函数为
gk(p,u)=(x(k)-xr(k))
其中(x-xr)
V(p(k))=Ea(k){gk(p,u)+γV(p(k+1))}
式中,γ∈(0,1)是折扣因子,Ea(k)表示状态k下的期望函数;
令V=W
Wj+1Φ(p(k))=Ea(k)[gk(p,u)+γWjΦ(p(k+1))]
式中, 为基向量。W是权重向量,通过最小二乘法迭代求解。
步骤五 得到价值函数后,在策略改进步骤中,同样利用设置基向量和权重向量的方法求解最优追踪控制策略,求解时,令h(p)=U
其中h(p)是由水下机器人学习通过对环境的学习得到的控制策略,此策略即为最优控制策略。
步骤六通过循环迭代价值更新和策略改进两个过程,当每次迭代价值更新和策略改进过程得到的权重变化小于阈值0.001时,视为收敛,迭代完成的h作为控制器的输出u输入至水下机器人的驱动器,完成对当前状态下最优控制策略的求解。
步骤七 将最优控制策略输入到由步骤二得到的降阶系统中,水下机器人更新自身状态,
再次重复步骤五、六得到对下一步动作的最优控制策略,再次输入到步骤二中......如此循环往复,最终完成控制方法。
本发明还公开了一种利用水下机器人进行跟踪的控制方法,利用被跟踪物体不断移动产生的轨迹信息,将其作为上部步骤1中的期望轨迹信息,利用基于强化学习的水下机器人控制方法,对水下机器人进行控制,实现对被跟踪物体的跟踪。
被跟踪物体移动的轨迹信息获得可由浮标继电器进行定位获取。
下述给出一个实施例具体予以说明:
(1)如图2所示,在给定长6m、宽5m和深1.5m的水域内,部署水下机器人,本发明在水面放有浮标继电器,用其对水下机器人进行自定位,控制中心给出水下机器人的期望轨迹信息xr=2sin(0.1k),yr=0.1k,zr=-1,其中k∈[0,...,100s],并发送至水下机器人。
(2)水下机器人的运动学模型为Sk+1=Sk+Uk+Ak,Sk=[x(k),y(k),z(k)]
(3)用强化学习的方法对位置进行追踪,在设置的一步代价函数V(p(k))=Ea(k){gk(p,u)+γV(p(k+1))}中,设置折扣因子γ=0.9。为了求得价值函数,令V=W
(4)通过循环迭代价值更新和策略改进两个过程,当每次迭代价值更新和策略改进过程得到的权重变化小于阈值0.001时,视为收敛,迭代完成的h作为控制器的输出u输入至水下机器人的驱动器,完成对当前状态下最优控制策略的求解。
(5)将最优控制策略作为输出输入到步骤2的系统映射机器人输出模型中,循环以上步骤,即可实现追踪任务。以上所述的实施仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
一种基于强化学习的水下机器人控制方法及其进行跟踪的控制方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。







动态评分
0.0