







专利摘要
本发明属于信息检索与评估领域,具体涉及基于证据理论的中文微博可信度评估方法。本发明从中文微博的固有特点入手,兼顾了这些特点的可测量性和实际任务,系统地梳理了中文微博信息的可信度测量指标,并将其归属为文本信息、信息来源与信息传播三个高层维度。考虑到人类认知的模糊性本质,提出一个基于多维证据的微博可信度评估方法用于融合上述三个异构维度。与现有的仅针对网络文本或互连关系的单一特征评估方法比较,基于证据理论的中文微博可信度评估方法考虑更全面、合理,在同样的查询条件下,可以优选哪些来源可靠,传播广泛的信息。
权利要求
1.基于证据理论的中文微博可信度评估方法,其特征在于步骤如下:
步骤1:预处理,将从各微博平台获取的Json格式微博,通过格式解析形成有效数据,然后借助现有的自然语言处理工具,对有效数据中的微博文本进行分词、词性标注、图标检测、错误词检测、重复标点检测等预处理工作,并统计相关数据;
步骤2:文本信息的可信度测量,信息本身的可信度可以从客观和主观两个方面入手考察,客观因素主要包括句法、语法、语气和语义四个层面,前两个层面,考虑了文本长度Slength和拼写错误Sspelling两个指标,具体计算方法如表1所示,表1同时列出了本发明考虑的和语气相关的三个因素分别是:图标Semoticons、重复标点Spunc以及正性词/负性词Sposi/neg,本发明将语义因素归结到任务相关领域,信息本身的可信度测量不涉及;影响文本信息可信度的主观因素反映的是其他用户对该文本质量的主观看法,通过分析主流中文微博平台数据,发现针对单个文本的可直接测量的主观因素有直接转贴数Sreposts和用户评论数Scomments,具体计算方法如表1所示;
本发明采用均值模式来分别融合客观因素和主观因素,然后再通过一个介于[0,1]之间的权重λ来控制客观和主观因素的相对权重,将各个影响因素的得分进行min-max标准化,计算方法如下:
其中v是需要标准化的值,min与max是某一影响因素得分的最小值与最大值,min'与max'是标准化区间的最小最大值;
所述主观和客观综合可信度值的加权融合计算方法如下:
由于客观因素更重要,本发明设定λ=0.7, 分别表示表1中各客观影响因素和各主观影响因素的标准化取值;
表1文本质量影响因素的计算方法
步骤3:信息来源的可信度测量,任何微博最初都是由人产生的,因此信息来源就是文本信息作者,微博用户可信度由他的客观日常行为和主观外部评价累积形成,可测量客观日常行为包括是否做过实名认证Φ,发布的文本信息总数Sposts,以及发布的高可信文本信息总数SHposts,而微博用户可测量外部评价包括追随者数目Sfellows,文本信息反馈情况Scomments,上述指标中,对作者影响最大的是是否实名认证,本发明将实名认证这一指标定义为一个二值函数[0,1],信息总数和高可信信息总数是两个关联指标,表2列出了这些指标的具体计算方法,作者可信度的加权综合融合方式计算方法如下:
其中 是表2中主观影响因素的min-max标准化取值,waut、wext和wsub分别是认证因素、客观因素和主观因素的权重,为突出认证的重要性本发明权重比例设定waut:wext:wsub=5:3:2;
表2作者影响因素的计算方法
步骤4:信息传播的可信度测量,影响信息传播可信度的因素包括两项,一是时效,二是传播媒介,本发明将时效因素也归结到了任务相关领域,传播媒介对文本信息可信度的影响方式通过两种情况递增:一种是传播媒价中包含可信度高的名人;另外一种是传播媒介中节点数目庞大,这种提升趋向于一个确定的阈值,依据可信度递增规律,本发明定义了用于具体计算传播媒介对微博文本可信度的影响,计算方法如下:
其中Cauthoir是用户根据可信度值递减排序后得到的第i个传播者的可信度,μ<1是递减因子;
步骤5:基于多维证据理论的可信度融合评估,本发明对三个维度可信度检测结果进行合成,得到综合微博可信度的过程将采用改进的D-S证据理论方法对多个维度的基本概率分配函数进行合成,计算方法如下:
其中,辨识框架
说明书
技术领域
基于证据理论的中文微博可信度评估方法属于信息检索与评估领域。
背景技术
最近几年,社会媒体得到迅猛发展,特别是微博,如美国的推特(Twitter)、中国的新浪微博、腾讯微博等,已发展成为互联网上的巨擘。中国互联网络信息中心(CNNIC)于2012年7月发布的《第30次中国互联网络发展状况统计报告》显示,截至2012年6月底,我国微博用户数达到2.74亿,微博的渗透率已经过半,而且微博在手机端的增长幅度仍然明显,增速达到24.2%。根据中国互联网调查社区(http://h.cnnicresearch.cn/sv/result/sid/22253)2013年1月13日完成的关于“社会化媒体使用率的调查”结果显示,微博(73.46%)已经取代“即时聊天工具”(66.93%)、搜索引擎(61.64%)、官方网站(56.64%)成为大众接触最多的社会媒体。
随着微博的蓬勃发展而带来的一大隐患,就是用户对微博内容的真实性和价值越来越难以判断。这主要是由微博内容的固有特点造成的。和其他社会媒体相似,微博的最大特点依然是媒体内容产生于用户(UGC,用户创造内容)和消费者(CGM,消费者产生媒体)。而且比起强调版面布置的博客来说,微博内容更简短、零碎,微博书写更随意、自由。正是由于微博内容的创造者自由度很大,没有编辑条款限制,使得微博上的信息质量差异很大。而且,由于信息的随便发布,群体的话语暴力,不负责任的非理性表达,也使得微博成为了众多网络谣言的发源地。因此,针对微博在信息书写、信息传播、社会网络分析等方面的固有特点,分析、评估微博内容、微博用户,并将其应用于微博信息综合或垂直搜索、微博知识发现等领域的研究,已经引起了国内外计算机科学、信息科学、传媒科学领域研究人员的关注和重视,成为微博研究领域的重要内容之一。
由于时间因素,目前对微博质量的研究实例大多集中于推特(Twitter)分析,这些研究可以分为两类,一类是利用传统分类技术的定性分析,这类研究需要大量样本,获取的是非数值结论,无法用于定量评估;另一类是针对不同性能指标的一些定量算法,只是现有质量评估函数多数只关注信息本身或某一侧面,缺少系统、全面地分析和评估,更没有从模糊认知的角度进行度量。目前针对中文微博质量分析的研究多数集中于内容分析和特定主题提取,缺少专门针对质量进行定量评估的系统方法。
发明内容
本发明从中文微博的固有特点入手,兼顾了这些特点的可测量性和实际任务,系统地梳理了中文微博信息的可信度测量指标,并将其归属为文本信息、信息来源与信息传播三个高层维度,考虑到人类认知的模糊性本质,提出一个基于多维证据的微博可信度评估方法用于融合上述三个异构维度,具体流程如图1所示。与现有的仅针对网络文本或互连关系的单一特征评估方法比较,基于证据理论的中文微博可信度评估方法考虑更全面、合理,在同样的查询条件下,可以优选哪些来源可靠,传播广泛的信息。本发明提供的中文微博可信度评估方法,具体步骤如下:
步骤1:预处理,将从各微博平台获取的Json格式微博,通过格式解析形成有效数据,然后借助现有的自然语言处理工具,对有效数据中的微博文本进行分词、词性标注、图标检测、错误词检测、重复标点检测等预处理工作,并统计相关数据;
步骤2:文本信息的可信度测量,信息本身的可信度可以从客观和主观两个方面入手考察,客观因素主要包括句法、语法、语气和语义四个层面,前两个层面,考虑了文本长度Slength和拼写错误Sspelling两个指标,具体计算方法如表1所示,表1同时列出了本发明考虑的和语气相关的三个因素分别是:图标Semoticons、重复标点Spunc以及正性词/负性词Sposi/neg,本发明将语义因素归结到任务相关领域,信息本身的可信度测量不涉及,影响文本信息可信度的主观因素反映的是其他用户对该文本质量的主观看法,通过分析主流中文微博平台数据,发现针对单个文本的可直接测量的主观因素有直接转贴数Sreposts和用户评论数Scomments,具体计算方法如表1所示;
本发明采用均值模式来分别融合客观因素和主观因素,然后再通过一个介于[0,1]之间的权重λ来控制客观和主观因素的相对权重,将各个影响因素的得分进行min-max标准化,计算方法如下:
其中v是需要标准化的值,min与max是某一影响因素得分的最小值与最大值,min'与max'是标准化区间的最小最大值;
所述主观和客观综合可信度值的加权融合计算方法如下:
由于客观因素更重要,本发明设定λ=0.7, 分别表示表1中各客观影响因素和各主观影响因素的标准化取值;
表1文本质量影响因素的计算方法
步骤3:信息来源的可信度测量,任何微博最初都是由人产生的,因此信息来源就是文本信息作者,微博用户可信度由他的客观日常行为和主观外部评价累积形成,可测量客观日常行为包括是否做过实名认证Φ,发布的文本信息总数Sposts,以及发布的高可信文本信息总数SHposts,而微博用户可测量外部评价包括追随者数目Sfellows,文本信息反馈情况Scomments,上述指标中,对作者影响最大的是是否实名认证,本发明将实名认证这一指标定义为一个二值函数[0,1],信息总数和高可信信息总数是两个关联指标,表2列出了这些指标的具体计算方法,作者可信度的加权综合融合方式计算方法如下:
其中 是表2中主观影响因素的min-max标准化取值,waut、wext和wsub分别是认证因素、客观因素和主观因素的权重,为突出认证的重要性本发明权重比例设定waut:wext:wsub=5:3:2;
表2作者影响因素的计算方法
步骤4:信息传播的可信度测量,影响信息传播可信度的因素包括两项,一是时效,二是传播媒介,本发明将时效因素也归结到了任务相关领域,传播媒介对文本信息可信度的影响方式通过两种情况递增:一种是传播媒价中包含可信度高的名人;另外一种是传播媒介中节点数目庞大,这种提升趋向于一个确定的阈值。依据可信度递增规律,本发明定义了用于具体计算传播媒介对微博文本可信度的影响,计算方法如下:
其中Cauthoir是用户根据可信度值递减排序后得到的第i个传播者的可信度,μ<1是递减因子;
步骤5:基于多维证据理论的可信度融合评估,本发明对三个维度可信度检测结果进行合成,得到综合微博可信度的过程将采用改进的D-S证据理论方法对多个维度的基本概率分配函数进行合成,计算方法如下:
其中,辨识框架
附图说明
图1中文微博可信度评估流程;
图2传播媒介的树形结构;
图3-(a)Json格式的新浪微博样本片段;
图3-(b)解析后获取的有效数据;
图4自然语言预处理后获取的文本信息相关值;
图5特定时间点收集到的样本微博的作者数据;
图6A的单层传播树。
具体实施方式
下面将结合附图和具体实施例对本发明进行详细说明。以下实施例中的微博是新浪微博中的个体样本。计算中文微博可信度的具体处理流程如下:
步骤1:预处理,依据图3-(a)所示是一个从新浪微博平台获取的Json格式微博样例A,图3-(b)是通过Json解析得到的A中对应有效数据。图4是通过自然语言处理工具和相关统计后获取的A的对应值。
步骤2:为待处理的微博文本计算可信度,有了A需要的统计数据,然后根据实际情况确定出各影响因子可能的最大/最小值后,表3中列出了A的具体计算值和对应的区间为[0,1]的标准化值。
表3A的影响因素值
最后根据公式(2)可以得到:
步骤3:计算微博来源可信度,微博来源也即微博作者,为了计算来源的影响因素,需要收集微博作者的相关信息,图5是特定时间点收集到的样本微博A的作者数据,其中标注为“统计:”的数据是需要计算后才能统计获取的,本例为了计算方便采用了人为设置。表4是计算值和标准化值。
表4A作者的影响因素值
最后根据公式(3)可以得到:
步骤4:计算信息传播的可信度,由于选取的微博样本A是最平常的信息,因此传播树高度只有一层如图6所示,使用和上一步骤同样的方式计算传播树中所有传播者的可信度,并根据可信度排序后,使用公式(4)就可以计算该传播树的可信度。假设7个作者的可信度值排序为:{0.85,0.78,0.7576,0.73,0.68,0.40,0.30},且μ=0.6,则A的传播可信度值为:
Cptree=0.6×0.85+0.62×0.78+0.63×0.7576+0.64×0.73+0.65×0.68+0.66×0.4+0.67×0.3≈1.14
假设min=0,max=2,则传播可信度值的标准化取值为:0.57。
步骤5:基于多维证据理论的可信度融合,有了上述文本、作者和传播分量后,获取的可信值可以直接作为概率值,因此根据多维证据合成公式可得到参数k和q(h),分别为:k=1-0.7576×0.6912×0.57-0.2424×0.3088×0.43=0.6693,q(h)=0.6729。
则:m(h)=0.7576×0.6912×0.57+0.6693×0.6729=0.7489
最后应说明的是:以上示例仅用以说明本发明而并非限制本发明所描述的技术方案;因此,尽管本说明书参照上述的示例对本发明已进行了详细的说明,但是,本领域的普通技术人员应当理解,仍然可以对本发明进行修改或等同替换;而一切不脱离发明的精神和范围的技术方案及其改进,其均应涵盖在本发明的权利要求范围当中。
基于证据理论的中文微博可信度评估方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。







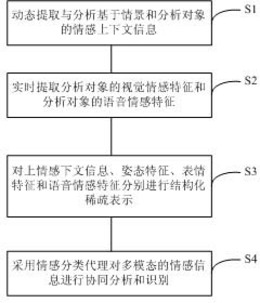

动态评分
0.0