

IPC分类号 : G10L25/03,G10L25/18,G10L25/24,G10L25/45,G10L25/51,G01N9/00,G01N24/00,G01N29/44,G06F17/30






专利摘要
本发明提出一种基于声音特征的物品材质识别方法及装置,属于信号处理和模式识别领域。本方法首先选定不同材质的训练物品,敲击每个训练物品表面获取音频文件,提取音频文件的特征得到训练物品的材质特征系数矩阵,构建材质识别专家数据库并作为训练样本集训练得到极限学习机分类器;获取待测物品的音频文件并提取相应的材质特征系数矩阵,将矩阵输入极限学习机分类器,分类器输出该测试物品的输出预测值矩阵,该矩阵中每个输出值对应一种物品材质类别,最大值所对应的物品材质类别即为该待测物品的材质识别结果。本装置包括麦克风声音采集笔和计算机,两者之间通过蓝牙连接。本发明有效帮助客户进行网购产品材质识别,识别结果准确,实用性强。
权利要求
1.一种基于声音特征的物品材质识别方法,其特征在于,包括以下步骤:
1)采集音频文件;
选定一个训练物品,利用麦克风声音采集笔敲击该训练物品的表面产生振动声音信号,将振动声音信号转换成数字声音信号并上传到计算机保存成一个音频文件;每个音频文件的采样频率为44100Hz,采集时长为1s,采集精度16bit,文件保存为wav格式,转换为数据点共有44100个数据点;
2)特征提取;具体包括以下步骤:
2-1)对步骤1)得到的训练物品音频文件的声音数据进行预处理;具体步骤如下:
2-1-1)预加重:将步骤1)得到的音频文件中的声音数据通过高通滤波,表达式如下:
H(z)=1-μz-1
式中,H(z)代表高通滤波器函数,预加重系数μ为0.97,z代表z变换;
2-1-2)对完成预加重的音频文件的声音数据进行分帧处理:令每帧的帧长为1104个数据点,则对应的每帧的时长为1104/44100*1000=25ms;帧移为441个数据点,则对应帧移时长为441/44100*1000=10ms,则该音频文件的声音数据划分后得到对应的帧数为98帧;
2-1-3)加窗处理:设分帧后的任意一帧中声音数据是xi(n),n=0,1,…,N-1,N为每帧中的数据点的个数,N=1104,i代表声音数据分帧后第i帧,i=1,2,…,98;乘上汉明窗后x′i(n)=xi(n)×W(n);
汉明窗公式为:
式中,W(n)代表汉明窗函数,汉明窗系数α=0.46;
2-2)对经过步骤2-1)预处理完毕的音频文件的声音数据提取特征,提取的特征包括:声音静态特性MFCC特征系数、声音动态特性MFCC一阶差分系数DMFCC和声音动态特性MFCC二阶差分系数D2MFCC;具体步骤如下:
2-2-1)提取声音静态特性MFCC特征系数:具体步骤如下:
2-2-1-1)将预处理完毕后的每帧声音数据进行快速傅里叶变换FFT得到每帧的频谱,表达式如下:
式中,Xi(k)为第i帧声音数据的频谱,k为第i帧中FFT变换的数据点数,x'i(n)为步骤2-1-3)得到的加窗后的每帧声音数据;
2-2-1-2)计算每帧声音数据的功率谱Pim,表达式如下:
Pim=|Xi(k)|2
2-2-1-3)将每帧声音数据的功率谱Pim通过Mel三角滤波器组进行滤波,Mel三角滤波器组中包括M个滤波器,Mel三角滤波器组的表达式如下:
式中, f(m)代表第m个Mel滤波器的中心频率,0≤m≤M-1;
2-2-1-4)计算Mel三角滤波器组输出的每帧声音数据的对数能量,表达式如下:
2-2-1-5)对步骤2-2-1-4)得到的对数能量进行离散余弦变换得到每帧声音数据的梅尔倒谱特征系数MFCC,表达式如下:
式中,Ci(η)表示第i帧声音数据的第η阶MFCC系数,L为MFCC系数的总阶数;训练物品的每个音频文件得到一个98*L的MFCC特征矩阵;
2-2-2)提取声音动态特性MFCC一阶差分特征系数DMFCC;
MFCC一阶差分特征系数DMFCC的表达式为:
式中,Di(η)是第i帧声音数据第η阶MFCC特征系数的一阶差分参数;θ表示一阶导数的时间差;训练物品的每个音频文件得到一个98*L的DMFCC特征矩阵;
2-2-3)提取声音动态特性MFCC二阶差分特征系数D2MFCC;
MFCC二阶差分特征系数D2MFCC的表达式为:
式中,Di2(η)是第i帧声音数据第η阶MFCC特征系数的二阶差分参数,ω表示二阶导数的时间差;训练物品的每个音频文件得到一个98*L的D2MFCC特征矩阵;
2-2-4)将步骤2-2-1)至2-2-3)得到的三个特征矩阵组合,得到步骤1)选定的训练物品的材质特征系数矩阵:
将提取到的MFCC特征矩阵,DMFCC特征矩阵和D2MFCC特征矩阵组合成一个98*3L的特征矩阵,将组合后的特征矩阵的首两行和尾两行去除,组合后的特征矩阵的每一列代表特征系数,对每一列特征系数求取平均值,最后得到该训练物品的音频文件的1*3L的混合MFCC声音特征矩阵并保存,该混合MFCC声音特征矩阵即为得到步骤1)选定的训练物品的材质特征系数矩阵;
3)重复步骤1)至步骤2),对步骤1)选定的训练物品重复采集20次音频文件并提取相应的材质特征系数矩阵;
4)选取A种不同类别的材质,每种材质中选取B个不同的物品作为训练物品,重复步骤1)至步骤3),获取每个训练物品相应的音频文件并提取相对应的材质特征系数矩阵,共提取 个材质特征系数矩阵作为训练样本,将所有的训练样本组建成材质识别专家数据库;
5)训练极限学习机ELM分类器;
5-1)构建ELM分类器;
ELM分类器包括输入层、隐含层和输出层三个层次;设置输入层有a个神经元,每个神经元分别对应每个训练样本的一个输入特征,则a=3L;设输出层有c个神经元,每个神经元分别对应步骤4)得到的材质识别专家数据库中的一种物品材质的类别,c=A;设定隐含层神经元个数为l;
5-2)ELM分类器的输入矩阵X表达式为:
式中,每一列代表一个训练样本,每一行代表一种特征;共有 个训练样本,每个训练样本均包含a个特征,则输入矩阵X有a行 列;
实际输出矩阵Y表达式为:
式中,实际输出矩阵Y为c行R列,每一列代表一个训练样本的输出结果,每一个训练样本的输出结果均包含输出c个输出值,每个输出值对应不同的材质类别;
5-2)随机选择输入层与隐含层间的连接权值w和隐含层神经元的偏置b;
输入层和隐含层之间的连接权值w,表达式如下:
式中,wσp表示输入层第p个神经元与隐含层第σ个神经元间的连接权值;
隐含层神经元的偏置b,表达式如下:
式中,bσ表示隐含层第σ个神经元的偏置;
5-3)计算隐含层输出矩阵H;
选择一个无限可微的函数作为隐含层神经元的激励函数g(x),记隐含层与输出层间的连接权值为β,表达式为:
得到ELM分类器的预测输出矩阵T为:
其中,
式中,wσ=[wσ1,wσ2,…,wσa];xq=[x1q,x2q,…,xaq]T;
上式中,预测输出矩阵T表示为:Hβ=T'
计算得到隐含层输出矩阵H:
5-4)计算隐含层与输出层的最优连接权值
β的值通过求解如下表达式的最小二乘解获得:
其最优解为 表达式如下:
式中,H+为隐含层输出矩阵H的Moore-Penrose广义逆,ELM分类器训练完毕;
6)材质识别;具体步骤如下:
6-1)选定任一待测物品,重复步骤1),采集该测物品产生的振动声音信号,并保存为相应的音频文件;
6-2)重复步骤2),对步骤6-1)得到的音频文件提取特征,获取该待测物品的材质特征系数矩阵;
6-3)将提取到的该待测物品的材质特征系数矩阵输入到步骤5)训练完毕的极限学习机ELM分类器,分类器输出得到该测试物品对应的c×1的输出预测值矩阵,该输出预测值矩阵中包含c个输出值,每个输出值对应一种物品材质类别,输出值中的最大值所对应的物品材质类别即为该待测物品的材质识别结果。
2.一种基于如权利要求1所述方法的物品材质识别装置,其特征在于,包括:麦克风声音采集笔和计算机,两者之间通过蓝牙连接;所述麦克风声音采集笔包括:金属敲击棒、麦克风传感器、声音模数转换模块、蓝牙传输模块、显示模块和笔体;所述麦克风传感器、声音模数转换模块、蓝牙传输模块和显示模块均安装在笔体内部,金属敲击棒一端放置在笔体内部,另一端放置在笔体外部;所述金属敲击棒用于敲击物品的表面产生振动声音信号,麦克风传感器用于采集振动声音信号并传送给声音模数转换模块,声音模数转换模块用于将振动声音信号转换成声音数字信号并传送给蓝牙传输模块,蓝牙传输模块通过蓝牙将声音数字信号上传至计算机保存成音频文件,计算机对音频文件进行识别后输出物品材质识别结果并通过蓝牙返回给蓝牙传输模块,蓝牙传输模块将识别结果通过显示模块显示给用户。
说明书
技术领域
本发明涉及了一种基于声音特征的物品材质识别方法及装置,属于信号处理和模式识别的领域。
背景技术
目前,作为“互联网+”的应用先锋,网上购物也是电子商务的核心子行业。在这个互联网提供基础设施的世界里,原先面对面的交易被电脑和网线取代了,交易双方只需在电脑前轻轻点击鼠标即可达成交易,交易的过程变得更加快捷容易,浏览、下单、支付和配送更加流畅高效。但同时交易双方之间也产生了新的问题:信任。提供商品的卖家是否有信誉,其销售的商品品质如何,商品是否符合商家的语言和图片描述,成为了网购相比于传统交易需要克服的一个很大的问题。
对于网购客户而言,产品的材质无疑是消费者最关心的问题。虽然商家也对产品的材质通常都有文字进行描述,甚至会拍摄图片,但对于普通消费者而言,由于无法直接看到或者感知到所描述的材质,这种对产品感觉的详细而无偏倚的口头描述并不一定有用。因此消费者在这种情况下购买产品的可能性会有所降低。
基于声音特征的物品材质识别是利用不同的材质发出声音的音色、音调、频率、响度等不同的特性,进行物品材质的识别,例如金属、塑料、布料、木材、纸质、玻璃、陶瓷等等,另外金属又可以分为铁、铜、铝、钢等等,木材也可分为杨木、柳木、榆木等诸多种类。通过声音,不仅可以知道物品的材质,还可以了解到物品的内部特征,比如实心或者空心等等。
现有的声音识别技术,大多是语音的识别,语音识别技术的主要的内容包括声音特征提取、模式匹配原则以及模型训练三个方面。语音识别的应用包括语音导航、语音搜索、语音拨号、语音翻译等,其主要涉及的领域包括模式识别、人工智能、信号处理等等。现阶段尚没有将声音特征应用于物品材质识别的相关技术。
ELM极限学习机为一种典型的单隐层前馈神经网络结构,其以学习速度快、泛化能力强等优点,吸引了国内和国际上的诸多专家学者的关注和研究。ELM不仅适用于回归和拟合问题,也适用在分类和模式识别等领域。ELM在各个领域都得到了广泛的应用。与此同时,ELM不少改进的方法和策略也被陆续提出,使得ELM的性能得到了很大的改善。其应用范围也越来越广泛,重要性因此日益提高。
发明内容
本发明目的是为了克服网购过程中单纯的利用文字描述来进行物品材质识别不足的问题,提出一种基于声音特征的物品材质识别方法及装置。本发明利用混合的MFCC声音特征实现物品材质识别的方法及装置。本发明可有效的帮助客户进行网购产品的材质识别,识别结果准确,实用性强。
本发明提出的一种基于声音特征的物品材质识别方法,其特征在于,包括以下步骤:
1)采集音频文件;
选定一个训练物品,利用麦克风声音采集笔敲击该训练物品的表面产生振动声音信号,将振动声音信号转换成数字声音信号并上传到计算机保存成一个音频文件;每个音频文件的采样频率为44100Hz,采集时长为1s,采集精度16bit,文件保存为wav格式,转换为数据点共有44100个数据点;
2)特征提取;具体包括以下步骤:
2-1)对步骤1)得到的训练物品音频文件的声音数据进行预处理;具体步骤如下:
2-1-1)预加重:将步骤1)得到的音频文件中的声音数据通过高通滤波,表达式如下:
H(z)=1-μz-1
式中,H(z)代表高通滤波器函数,预加重系数μ为0.97,z代表z变换;
2-1-2)对完成预加重的音频文件的声音数据进行分帧处理:令每帧的帧长为1104个数据点,则对应的每帧的时长为1104/44100*1000=25ms;帧移为441个数据点,则对应帧移时长为441/44100*1000=10ms,则该音频文件的声音数据划分后得到对应的帧数为98帧;
2-1-3)加窗处理:设分帧后的任意一帧中声音数据是xi(n),n=0,1,…,N-1,N为每帧中的数据点的个数,N=1104,i代表声音数据分帧后第i帧,i=1,2,…,98;乘上汉明窗后x′i(n)=xi(n)×W(n);
汉明窗公式为:
式中,W(n)代表汉明窗函数,汉明窗系数α=0.46;
2-2)对经过步骤2-1)预处理完毕的音频文件的声音数据提取特征,提取的特征包括:声音静态特性MFCC特征系数、声音动态特性MFCC一阶差分系数DMFCC和声音动态特性MFCC二阶差分系数D2MFCC;具体步骤如下:
2-2-1)提取声音静态特性MFCC特征系数:具体步骤如下:
2-2-1-1)将预处理完毕后的每帧声音数据进行快速傅里叶变换FFT得到每帧的频谱,表达式如下:
式中,Xi(k)为第i帧声音数据的频谱,k为第i帧中FFT变换的数据点数,x'i(n)为步骤2-1-3)得到的加窗后的每帧声音数据;
2-2-1-2)计算每帧声音数据的功率谱Pim,表达式如下:
Pim=|Xi(k)|2
2-2-1-3)将每帧声音数据的功率谱Pim通过Mel三角滤波器组进行滤波,Mel三角滤波器组中包括M个滤波器,Mel三角滤波器组的表达式如下:
式中, f(m)代表第m个Mel滤波器的中心频率,0≤m≤M-1;
2-2-1-4)计算Mel三角滤波器组输出的每帧声音数据的对数能量,表达式如下:
2-2-1-5)对步骤2-2-1-4)得到的对数能量进行离散余弦变换得到每帧声音数据的梅尔倒谱特征系数MFCC,表达式如下:
式中,Ci(η)表示第i帧声音数据的第η阶MFCC系数,L为MFCC系数的总阶数;训练物品的每个音频文件得到一个98*L的MFCC特征矩阵;
2-2-2)提取声音动态特性MFCC一阶差分特征系数DMFCC;
MFCC一阶差分特征系数DMFCC的表达式为:
式中,Di(η)是第i帧声音数据第η阶MFCC特征系数的一阶差分参数;θ表示一阶导数的时间差;训练物品的每个音频文件得到一个98*L的DMFCC特征矩阵;
2-2-3)提取声音动态特性MFCC二阶差分特征系数D2MFCC;
MFCC二阶差分特征系数D2MFCC的表达式为:
式中,Di2(η)是第i帧声音数据第η阶MFCC特征系数的二阶差分参数,ω表示二阶导数的时间差;训练物品的每个音频文件得到一个98*L的D2MFCC特征矩阵;
2-2-4)将步骤2-2-1)至2-2-3)得到的三个特征矩阵组合,得到步骤1)选定的训练物品的材质特征系数矩阵:
将提取到的MFCC特征矩阵,DMFCC特征矩阵和D2MFCC特征矩阵组合成一个98*3L的特征矩阵,将组合后的特征矩阵的首两行和尾两行去除,组合后的特征矩阵的每一列代表特征系数,对每一列特征系数求取平均值,最后得到该训练物品的音频文件的1*3L的混合MFCC声音特征矩阵并保存,该混合MFCC声音特征矩阵即为得到步骤1)选定的训练物品的材质特征系数矩阵;
3)重复步骤1)至步骤2),对步骤1)选定的训练物品重复采集20次音频文件并提取相应的材质特征系数矩阵;
4)选取A种不同类别的材质,每种材质中选取B个不同的物品作为训练物品,重复步骤1)至步骤3),获取每个训练物品相应的音频文件并提取相对应的材质特征系数矩阵,共提取 个材质特征系数矩阵作为训练样本,将所有的训练样本组建成材质识别专家数据库;
5)训练极限学习机ELM分类器;
5-1)构建ELM分类器;
ELM分类器包括输入层、隐含层和输出层三个层次;设置输入层有a个神经元,每个神经元分别对应每个训练样本的一个输入特征,则a=3L;设输出层有c个神经元,每个神经元分别对应步骤4)得到的材质识别专家数据库中的一种物品材质的类别,c=A;设定隐含层神经元个数为l;
5-2)ELM分类器的输入矩阵X表达式为:
式中,每一列代表一个训练样本,每一行代表一种特征;共有 个训练样本,每个训练样本均包含a个特征,则输入矩阵X有a行 列;
实际输出矩阵Y表达式为:
式中,实际输出矩阵Y为c行R列,每一列代表一个训练样本的输出结果,每一个训练样本的输出结果均包含输出c个输出值,每个输出值对应不同的材质类别;
5-2)随机选择输入层与隐含层间的连接权值w和隐含层神经元的偏置b;
输入层和隐含层之间的连接权值w,表达式如下:
式中,wσp表示输入层第p个神经元与隐含层第σ个神经元间的连接权值;
隐含层神经元的偏置b,表达式如下:
式中,bσ表示隐含层第σ个神经元的偏置;
5-3)计算隐含层输出矩阵H;
选择一个无限可微的函数作为隐含层神经元的激励函数g(x),记隐含层与输出层间的连接权值为β,表达式为:
得到ELM分类器的预测输出矩阵T为:
其中,
式中,wσ=[wσ1,wσ2,…,wσa];xq=[x1q,x2q,…,xaq]T;
上式中,预测输出矩阵T表示为:Hβ=T'
计算得到隐含层输出矩阵H:
5-4)计算隐含层与输出层的最优连接权值
β的值通过求解如下表达式的最小二乘解获得:
其最优解为 表达式如下:
式中,H+为隐含层输出矩阵H的Moore-Penrose广义逆,ELM分类器训练完毕;
6)材质识别;具体步骤如下:
6-1)选定任一待测物品,重复步骤1),采集该测物品产生的振动声音信号,并保存为相应的音频文件;
6-2)重复步骤2),对步骤6-1)得到的音频文件提取特征,获取该待测物品的材质特征系数矩阵;
6-3)将提取到的该待测物品的材质特征系数矩阵输入到步骤5)训练完毕的极限学习机ELM分类器,分类器输出得到该测试物品对应的c×1的输出预测值矩阵,该输出预测值矩阵中包含c个输出值,每个输出值对应一种物品材质类别,输出值中的最大值所对应的物品材质类别即为该待测物品的材质识别结果。
本发明提出的一种基于如上述方法的物品材质识别装置,其特征在于,包括:麦克风声音采集笔和计算机,两者之间通过蓝牙连接;所述麦克风声音采集笔包括:金属敲击棒、麦克风传感器、声音模数转换模块、蓝牙传输模块、显示模块和笔体;所述麦克风传感器、声音模数转换模块、蓝牙传输模块和显示模块均安装在笔体内部,金属敲击棒一端放置在笔体内部,另一端放置在笔体外部;所述金属敲击棒用于敲击物品的表面产生振动声音信号,麦克风传感器用于采集振动声音信号,并传送给声音模数转换模块,声音模数转换模块用于将振动声音信号转换成声音数字信号并传送给蓝牙传输模块,蓝牙传输模块通过蓝牙将声音数字信号上传至计算机保存成音频文件,计算机对音频文件进行识别后输出物品材质识别结果并通过蓝牙返回给蓝牙传输模块,蓝牙传输模块将识别结果通过显示模块显示给用户。
本发明的技术特点及有益效果:
(1)本发明利用不同材质物品发声不同的特性,对采集到的声音进行特征分析并进行物品的材质分辨,弥补了通过视觉或文字描述等识别物品材质所带来的缺陷。
(2)本发明将基于声音混合MFCC特征系数的方法应用到物品的材质识别中,弥补了简单的声音静态特征梅尔倒谱特征系数对于物品材质识别的结果欠佳的缺漏,引入了声音动态的动态特性梅尔倒谱特征系数的一阶差分和二阶差分,使提取的特征更加准确。
(3)本发明构建了多种材质的敲击声音特征的专家数据库作为分类器的训练集,尽可能多的满足不同材质识别的需求。
(4)本发明利用极限学习机作为分类器对物品材质进行分析,使得工作更加高效。
附图说明
图1为本发明方法的整体流程图。
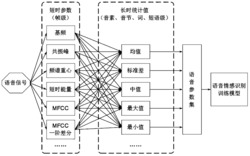
图2为本发明方法中特征提取阶段流程图。
图3为本发明装置中麦克风声音采集笔的结构示意图。
图3中,1-1、金属敲击棒;1-2、麦克风传感器;1-3、声音模数转换模块;1-4、蓝牙传输模块;1-5、显示模块;1-6、笔体。
具体实施方式
本发明提出的一种基于声音特征的物品材质识别方法及装置,下面结合附图和具体实施例进一步详细说明如下。
本发明提出的一种基于声音特征的物品材质识别方法,整体流程如图1所示,包括以下步骤:
1)采集音频文件;
选定一个训练物品,利用麦克风声音采集笔敲击该训练物品的表面(训练物品的材质为已知)产生振动声音信号,将振动声音信号转换成数字声音信号并上传到计算机保存成一个音频文件。本实例中,每个音频文件的采样频率为44100Hz,采集时长为1s,采集精度16bit,文件保存为wav格式,转换为数据点共有44100个数据点。
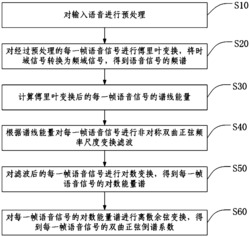
2)特征提取;流程如图2所示,具体包括以下步骤:
2-1)对步骤1)得到训练物品的音频文件中的声音数据进行预处理;具体步骤如下:
2-1-1)预加重:将步骤1)得到的音频文件中的声音数据通过高通滤波,表达式如下:
H(z)=1-μz-1
式中,H(z)代表高通滤波器函数,预加重系数μ为0.97,z代表z变换。
2-1-2)对完成预加重的音频文件的声音数据进行分帧处理:令每帧的帧长为1104个数据点,则对应的每帧的时长为1104/44100*1000=25ms;帧移为441个数据点,则对应帧移时长为441/44100*1000=10ms,则该音频文件的声音数据划分后得到对应的帧数为98帧。
2-1-3)加窗处理:设分帧后的任意一帧中声音数据是xi(n),n=0,1,…,N-1,N为每帧中的数据点的个数,i代表声音数据分帧后第i帧,i=1,2,…,98。乘上汉明窗后x′i(n)=xi(n)×W(n);
汉明窗公式为:
式中,W(n)代表汉明窗函数,汉明窗系数α=0.46。
2-2)对经过步骤2-1)预处理完毕的声音数据提取特征,提取的特征包括:声音静态特性MFCC特征系数、声音动态特性MFCC一阶差分系数DMFCC和声音动态特性MFCC二阶差分系数D2MFCC;具体步骤如下:
2-2-1)提取声音静态特性MFCC特征系数:具体步骤如下:
2-2-1-1)将预处理完毕后的每帧声音数据进行快速傅里叶变换FFT得到每帧的频谱,表达式如下:
式中,Xi(k)为第i帧声音数据的频谱,k为第i帧中FFT变换的数据点数,x'i(n)为步骤2-1-3)得到的加窗后的每帧声音数据,N为每一帧中的数据点的个数,本实例中,N=1104。
2-2-1-2)计算每帧声音数据的功率谱Pim,表达式如下:
Pim=|Xi(k)|2
2-2-1-3)将每帧声音数据的功率谱Pim通过Mel三角滤波器组进行滤波,Mel三角滤波器组中包括M个滤波器,通常M取值在22~26之间,此实施例中M此处取24。Mel三角滤波器组的计算公式如下:
式中, f(m)代表第m个Mel滤波器的中心频率,0≤m≤M-1。
2-2-1-4)计算Mel三角滤波器组输出的每帧声音数据的对数能量,表达式如下:
2-2-1-5)对步骤2-2-1-4)得到的对数能量进行离散余弦变换(DCT)得到每帧声音数据的梅尔倒谱特征系数MFCC,表达式如下:
式中,Ci(η)表示第i帧声音数据的第η阶MFCC系数,L为MFCC系数的总阶数,本实例中L取13。本实施例中每个训练物品采集得到的音频文件的声音数据被分成98帧,每帧声音数据得到13阶MFCC系数,因此训练物品的每个音频文件得到一个98*13的MFCC特征矩阵。
2-2-2)提取声音动态特性MFCC一阶差分特征系数DMFCC;
MFCC一阶差分特征系数DMFCC的表达式为:
式中,Ci(η)是第i帧声音数据第η阶MFCC特征系数,Di(η)是第i帧声音数据第η阶MFCC特征系数的一阶差分参数。θ表示一阶导数的时间差,此处θ取2。本实施例中,训练物品的每个音频文件得到一个98*13的DMFCC特征矩阵。
2-2-3)提取声音动态特性MFCC二阶差分特征系数D2MFCC;
MFCC二阶差分特征系数D2MFCC的表达式为:
式中,Di(η)是第i帧声音数据第η阶MFCC特征系数的一阶差分参数,Di2(η)是第i帧声音数据第η阶MFCC特征系数的二阶差分参数。ω表示二阶导数的时间差,此处ω取2。本实施例中,训练物品的每个音频文件得到一个98*13的D2MFCC特征矩阵;
2-2-4)将步骤2-2-1)至2-2-3)得到的三个特征矩阵组合,得到步骤1)选定的训练物品的材质特征系数矩阵:
将提取到的MFCC特征矩阵,DMFCC特征矩阵和D2MFCC特征矩阵组合成一个98*3L(本实施例为98*39)的特征矩阵,由于DMFCC特征矩阵和D2MFCC特征矩阵的首两行和尾两行为0,故将组合后的特征矩阵的首两行和尾两行去除。组合后的特征矩阵的每一列代表特征系数,对每一列特征系数求取平均值,最后得到该训练物品的音频文件的1*3L(本实施为1*39)的混合MFCC声音特征矩阵并保存,该混合MFCC声音特征矩阵即为得到步骤1)选定的训练物品的材质特征系数矩阵。
3)重复步骤1)至步骤2),对步骤1)选定的训练物品重复采集20次音频文件并提取相应的材质特征系数矩阵;
4)选取A种不同类别(本实施例为7类)的材质,每种材质中选取B个不同的物品(本实施例每种材质类别中选取5个物品)作为训练物品,重复步骤1)至步骤3),获取每个训练物品相应的音频文件并提取相对应的材质特征系数矩阵;将所有的材质特征系数矩阵组建成材质识别专家数据库,并作为极限学习机的分类器的训练样本集,其中,每个特征系数矩阵作为一个训练样本,共包含 个训练样本。其中本实施例中7类不同的材质包括金属、塑料、纺织品、玻璃、木材、纸质、陶瓷。
5)训练极限学习机(ELM)分类器;
5-1)构建极限学习机(ELM)分类器;
本实施例中ELM分类器包括输入层、隐含层和输出层三个层次;设置输入层有a个神经元,每个神经元分别对应每个训练样本的一个输入特征,则a=3L(本实施例每个训练样本为步骤2)得到的一个的材质特征系数矩阵,该矩阵共包含39种特征,则a的取值为39);输出层设有c个神经元,每个神经元对应训练样本集中一种物品材质的类别,c=A,本实施例中c=7。设定隐含层神经元个数为l,l根据经验赋值,本实施例中,l=2000。
5-2)将步骤4)建立的材质识别专家数据库作为ELM分类器的训练样本集,其中每个材质特征系数矩阵作为一个训练样本;记该训练数据集共包含 个训练样本,ELM分类器的输入矩阵X表达式为:
式中,每一列代表一个训练样本,每一行代表一种特征;训练样本集共有 个训练样本,每个训练样本均包含a个特征,则输入矩阵X有a行 列;
实际输出矩阵Y表达式为:
式中,实际输出矩阵Y为c行R列,每一列代表一个训练样本的输出结果,每一个训练样本的输出结果均包含输出c个输出值,每个输出值对应不同的材质类别;
5-2)随机选择输入层与隐含层间的连接权值w和隐含层神经元的偏置b;
输入层和隐含层之间的连接权值w,表达式如下:
式中,wσp表示输入层第p个神经元与隐含层第σ个神经元间的连接权值。
隐含层神经元的偏置b,表达式如下:
式中,bσ表示隐含层第σ个神经元的偏置。
5-3)计算隐含层输出矩阵H;
选择一个无限可微的函数作为隐含层神经元的激励函数g(x),记隐含层与输出层间的连接权值为β,表达式为:
进而得到ELM分类器的预测输出矩阵T为:
其中,
式中,wσ=[wσ1,wσ2,…,wσa];xq=[x1q,x2q,…,xaq]T。
上式中,预测输出矩阵T可表示为:Hβ=T'
进而计算得到隐含层输出矩阵H:
5-4)计算隐含层与输出层的最优连接权值
训练ELM分类器的目的是找到最佳的w、b和β,使得 最小。由于当激活函数g(x)无限可微时,w和b训练时可以随机选择,且在训练过程中保持不变。故β可通过求解下式的最小二乘解获得:
其最优解为 表达式如下:
式中,H+为隐含层输出矩阵H的Moore-Penrose广义逆,ELM分类器训练完毕。
6)材质识别,具体步骤如下:
6-1)选定任一待测物品,重复步骤1),采集该测物品产生的振动声音信号,并保存为相应的音频文件;
6-2)重复步骤2),对步骤6-1)得到的音频文件提取特征,获取该待测物品的材质特征系数矩阵;
6-3)将提取到的该待测物品的材质特征系数矩阵输入到步骤5)训练完毕的极限学习机ELM分类器。分类器输出得到该测试物品对应的c×1的输出预测值矩阵,该输出预测值矩阵中包含c个输出值,每个输出值对应一种物品材质类别,输出值中最大值所对应的物品材质类别即为该待测物品的材质识别结果。
本发明提出的一种基于如上所述方法的物品材质识别装置,包括:麦克风声音采集笔和计算机,两者之间通过蓝牙连接;所述麦克风声音采集笔的组成如图3所示,包括金属敲击棒(1-1)、麦克风传感器(1-2)、声音模数转换模块(1-3)、蓝牙传输模块(1-4)、显示模块(1-5)和笔体(1-6)。
所述麦克风传感器(1-2)、声音模数转换模块(1-3)、蓝牙传输模块(1-4)和显示模块(1-5)都安装在笔体(1-6)内部,金属敲击棒(1-1)一端放置在笔体(1-6)内部,另一端放置在笔体(1-6)外部;所述金属敲击棒(1-1)用于敲击物品的表面产生振动声音信号,麦克风传感器(1-2)用于采集振动声音信号并传送给声音模数转换模块(1-3),声音模数转换模块(1-3)用于将振动声音信号转换成声音数字信号并传送给蓝牙传输模块(1-4),蓝牙传输模块(1-4)通过蓝牙将声音数字信号上传至计算机保存成音频文件,计算机对音频文件进行识别后输出物品材质识别结果并通过蓝牙返回给蓝牙传输模块(1-4),蓝牙传输模块(1-4)将识别结果通过显示模块(1-5)显示给用户。
本发明装置中的麦克风传感器可为任意型号,本实施例中应用型号为Raspberry Pi B+2,计算机可为任意型号,其他部件均为常规部件。
一种基于声音特征的物品材质识别方法及装置专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。











动态评分
0.0