









专利摘要
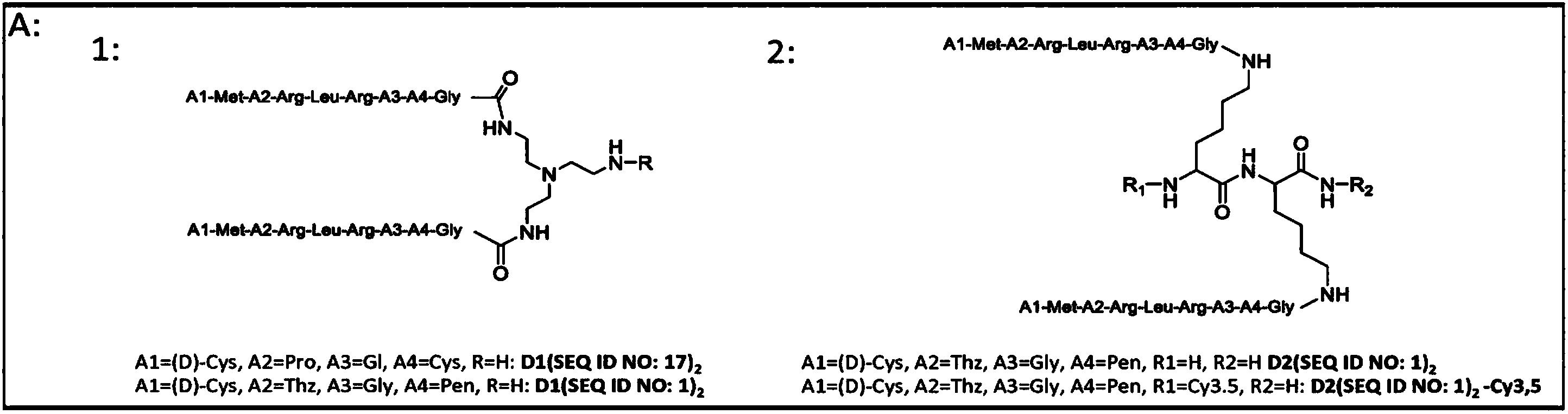
本发明涉及一种特异性地与靶结合的双齿肽结合物及其制造方法,上述靶包含:(a)形成链间非共价键的平行、反平行或平行和反平行氨基酸链的结构稳定化区;以及(b)结合至上述结构稳定化区的两个末端,并包含随机选择的各n及m个氨基酸的靶结合区I及靶结合区II。本发明的双齿肽结合物表现出极低水平(例如nM水平)的KD值(解离常数),对靶表现出十分高的亲和力。本发明的双齿肽结合物不仅具有医药用途,还能用于体内分子成像、体外细胞成像以及药物传递用靶向,并且用作保护分子也非常有效。
说明书
技术领域【技术领域】
本发明涉及一种双齿肽结合物(Bipodal peptide binder)及其制造方法。
技术背景【背景技术】
抗体是作为B细胞所产生的一种血浆蛋白质的免疫球蛋白,其特异性地识别从外部引进的抗原的特定区而结合,从而对抗原进行钝化或中和。通过应用这种抗原-抗体反应的特异性和高度的亲和力及能够区别数千万种类的抗原的抗体的多样性,当今出现了包含诊断剂和治疗剂等的多种抗体产品。目前FDA认证了21种单克隆抗体,如利妥昔单抗(Rituximab)及赫赛汀(Herceptin)的抗体在其他治疗中完全未起到效应的50%以上的患者身上产生了效果,实际上在许多研究过程中利用单克隆抗体在淋巴瘤、大肠癌或乳腺癌等方面呈现成功的临床治疗。预计治疗用抗体的整体市场规模将从2004年100亿美元增加到2010年的300亿美元呈现年均20%的成长率,并预计其市场规模将会急剧增加。踊跃开展利用抗体的新药开发的理由在于:药品的开发期间短,投资费用少,能够容易预测到副作用。并且,抗体作为生药几乎不给人体带来影响,并且抗体在体内的半衰期相当长,其期间相比低分子量药品具有压倒性的优势,因而对患者无害。单克隆抗体尽管具有这种有用性,但是在人体内被识别为外源性抗原而会引起严重的变态反应或超敏反应。并且,临床上使用这种抗癌功能的单克隆抗体时,由于生产成本高,因而具有作为治疗剂的价格急剧上涨的缺点,并且由于培养抗体的方法及纯化方法等广泛领域的技术受到各种知识产权的保护,要支付昂贵的专利权使用费。
因此,为了解决此问题,以美国为中心,欧洲联盟处于抗体替代蛋白质开发的萌发期。抗体替代蛋白质作为如抗体一样具有不变区和可变区的重组蛋白质,将大小较小而稳定的蛋白质的规定部分替换成随机序列的氨基酸而构成文库(library),将其针对靶物质进行淘选而能够找出具有较高的亲和力和优良的特异性的物质。例如报告了抗体替代蛋白质中的高亲合性多聚体(avimer)和亲和体(affibody)对于靶物质具有皮摩尔(picomole)程度的亲和力的例子。报告称这种抗体替代蛋白质由于大小较小而稳定,能够渗透到癌细胞深处,一般很少引起免疫反应。并且,尤其是能够摆脱广泛的抗体专利问题,并且在细菌中能够容易地进行大量纯化,使得生产成本降低,因此经济上相比抗体具有更大的优点。目前开发出的抗体替代蛋白质有40种,其中,在风险投资公司或跨国制药公司正试图商用化的抗体替代蛋白质正在利用纤维连接蛋白III型结构域、脂笼蛋白、LDLR-A结构域、结晶体、蛋白A、锚蛋白重复序列(Ankyrin repeat)以及BPTI这些蛋白质,对于靶具有皮摩尔到数纳摩尔程度的亲和力。其中,艾得奈可汀(Adnectin)、高亲合性多聚体、库尼茨(Kunitz)结构域目前正处于FDA临床实验阶段。
本发明聚焦于与迄今的利用蛋白质的抗体替代蛋白质不同的基于肽的抗体替代蛋白质。肽相比抗体能够实现适当的药物动力学、大量生产率、低毒性、抗原性抑制以及低生产成本等,因而目前替代抗体治疗剂以多种形态应用。作为治疗用药物的肽的优点在于:生产成本低,安全性及反应性高,专利税相对低廉,不太露出在不期望的免疫系统,能够抑制对于肽自身的抗体产生,容易而准确地进行通过合成的变形。但是,由于大部分的肽相比抗体,对于特定蛋白质靶呈现低的亲和力及特异性,因而具有无法使用于多种应用领域的缺点。因此,本领域中便开始涌现出关于能够克服肽的缺点的基于新颖肽的抗体替代蛋白质开发的需求。为此,本发明人们致力于开发出能够以高的亲和性与生物学靶分子特异性地结合的肽物质。预计这将成为能够利用对于目前许多的靶进行了报告的具有低亲和力的肽来短时间内制造具有高亲和性及特异性的新药候补物质的技术。
本说明书遍及其所有内容参照并引用了多个论文及专利文献。所引用的论文及专利文献的所有揭示内容作为参照内容编入本说明书中,由此更加明确地说明本发明所属技术领域的水平及本发明的内容。
发明内容【发明内容】
本发明人致力于开发出能够以十分高的亲和性(affinity)与生物学靶分子特异性地结合的肽物质。其结果表明,如果在具有比较坚固(rigid)肽骨架的结构稳定化区的两个末端随机(random)地结合肽,并将所述两个肽共同结合至靶分子,则能够获得具有大大增大的结合能力及特异性的双齿肽结合物,由此完成了本发明。
因此,本发明的目的在于,提供一种双齿肽结合物(bipodal-peptide binder)的制造方法。
本发明的另一目的在于,提供一种与生物学靶分子结合的双齿肽结合物。
本发明的又一目的在于,提供一种对双齿肽结合物进行编码的核酸分子。
本发明的再一目的在于,提供一种双齿肽结合物的表达用载体。
本发明的还一目的在于,提供一种包含双齿肽结合物的表达用载体的转化体。
本发明的其他目的及优点,将通过本发明的详细说明、权利要求书及附图更为明确。
根据本发明的一实施方式,本发明提供一种与生物学靶分子结合的双齿肽结合物(bipodal-peptide binder)的制造方法,
该方法包含如下步骤:
(a)提供双齿肽结合物的文库的步骤,上述双齿肽结合物包含:(i)结构稳定化区(structure stabilizing region),其包含形成有链间(interstrand)非共价键的平行线(parallel)、反平行线(antiparallel)或平行(parallel)和反平行(antiparallel)氨基酸链,以及(ii)靶结合区I(target binding region I)及靶结合区II(target binding regionII),与上述结构稳定化区的两个末端结合,并包含随机选择的各n及m个氨基酸;
(b)使上述文库和靶接触的步骤;以及
(c)选择与上述靶结合的双齿肽结合物。
根据本发明的其他实施方式,本发明提供一种特异性地与靶结合的双齿肽结合物,该双齿肽结合物包含:(a)结构稳定化区(structure stabilizing region),其包含形成有链间(interstrand)非共价键的平行线(parallel)、反平行线(antiparallel)或平行(parallel)和反平行(antiparallel)氨基酸链;以及(b)靶结合区I(target binding region I)及靶结合区II(target binding region II),其与上述结构稳定化区的两个末端结合,并包含随机选择的各n及m个氨基酸。
本发明人等致力于开发出能够以十分高的亲和性(affinity)与生物学靶分子特异性地结合的肽物质。其结果表明,如果在具有比较坚固(rigid)肽骨架的结构稳定化区的两个末端随机(random)地结合肽,并将所述两个肽共同结合至靶分子,则能够获得具有大大增大的结合能力及特异性的双齿肽结合物。
本发明的基本策略在于,在坚固的肽骨架的两个末端连接与靶结合的肽。此时,坚固的肽骨架起着对双齿肽结合物的整体结构进行稳定化的作用,并加强靶结合区I及靶结合区II与靶分子结合。
本发明中能利用的结构稳定化区包含平行线、反平行线或平行和反平行氨基酸键,并包含将形成基于链间(interstrand)氢键、基于静电相互作用、疏水性相互作用、范德瓦尔斯相互作用、π-π相互作用、阳离子-π相互作用或它们的组合的非共价键的蛋白质结构基序。将基于链间氢键、静电相互作用、疏水性相互作用、范德瓦尔斯相互作用、π-π相互作用、阳离子-π相互作用或它们的组合形成的非共价键有助于结构稳定化区的坚固性(rigidity)。
根据本发明的优选实施例,在结构稳定化区上的链间(interstrand)非共价键包含氢键、疏水性相互作用、范德瓦尔斯相互作用、π-π相互作用或它们的组合。
选择性地,在结构稳定化区可能有共价键。例如在结构稳定化区形成二硫键,由此能够更加增强结构稳定化区的坚固性。鉴于对双齿肽结合物的靶的特异性及亲和力,增强基于这种共价键的坚固性。
根据本发明的优选实施例,结构稳定化区的各氨基酸链通过连接物连接。在本说明书中谈及链时所用的术语“连接物”是指用于连接物与链之间的物质。例如将β-发夹用作结构稳定化区时,位于β-发夹的换向序列起着连接物的作用,将亮氨酸拉链用作结构稳定化区时,用于连接亮氨酸拉链的两个C-末端的物质(例如肽连接物)起着连接物的作用。
连接物用于连接平行线、反平行线或平行和反平行氨基酸链。例如该连接物连接以平行方式排序的最小2个链(优选为2个链)、以反平行方式排序的最小2个链(优选为2个链)、以平行及反平行方式排序的最小3个链(优选为3个链)。
根据本发明的优选实施例,连接物是换向序列或肽连接物。
根据本发明的优选实施例,上述换向序列是β-换向、γ-换向、α-换向、π-换向或ω-环形(ω-loop)(Venkatachalam CM(1968),Biopolymers,6,1425-1436;Nemethy G and Printz MP.(1972),Macromolecules,5,755-758;Lewis PN et al.,(1973),Biochim.Biophys.Acta,303,211-229;Toniolo C.(1980)CRC Crit.Rev.Biochem.,9,1-44;Richardson JS.(1981),Adv.Protein Chem.,34,167-339;Rose GD et al.,(1985),Adv.Protein Chem.,37,1-109;Milner-White EJ and Poet R.(1987),TIBS,12,189-192;Wilmot CMand Thornton JM.(1988),J.Mol.Biol.,203,221-232;Milner-WhiteEJ.(1990),J.Mol.Biol.,216,385-397;Pavone V et al.(1996),Biopolymers,38,705-721;Rajashankar KR and Ramakumar S.(1996),Protein Sci.,5,932-946)。最优选地,本发明中所利用的换向序列为β-换向。
将β-换向用作换向序列时,优选为I型、I′型、II型、II′型、III型或III′型换向序列,更优选为I型、I′型、II型、II′型换向序列,进而优选为I′型或II′型换向序列,最优选为I′型换向序列(B.L.Sibanda et al.,J.Mol.Biol.,1989,206,4,759-777;B.L.Sibanda et al.,Methods Enzymol.,1991,202,59-82)。
根据本发明的另一优选实施例,能够在本发明中用作换向序列的已在H.Jane Dyson et al.,Eur.J.Biochem.255:462-471(1998)中公开,上述文献作为参照内容编入本说明书中。能够用作换向序列的包含以下氨基酸序列:X-Pro-Gly-Glu-Val;Ala-X-Gly-Glu-Val(X选自20个氨基酸)。
根据本发明的一实施例,将β-折叠或亮氨酸拉链用作结构稳定化区时,优选地通过肽连接物来连接以平行方式排序的2个链或以反平行方向排序的2个链。
肽连接物只要是在本领域中公开的能够利用任何一个。适合的肽连接物的序列能够鉴于如下的因素而选择:(a)能够适用于柔性延伸构象(flexible extended conformation)的能力;(b)不生成与生物学靶分子相互作用的二级结构的能力;以及(c)与生物学靶分子相互作用的疏水性残基或带有电荷的残基的部件。优选的肽连接物包含Gly、Asn及Ser残基。诸如Thr及Ala的其他中性氨基酸也能包含于连接物序列。适合于连接物的氨基酸序列已在Maratea et al.,Gene40:39-46(1985);Murphy et al.,Proc.Natl.Acad Sci.USA83:8258-8562(1986);美国专利第4,935,233号、第4,751,180号及第5,990,275号中公开。肽连接物序列能够由1-50氨基酸残基构成。
根据本发明的优选实施例,结构稳定化区是β-发夹、通过连接物连接的β-折叠或通过连接物连接的亮氨酸拉链,更优选地,结构稳定化区是β-发夹或通过连接物连接的β-折叠,最优选为β-发夹。
本说明书中,术语“β-发夹”是指包含两个β链的最简单的蛋白质基序,这两个β链呈现相互反平行的排序。该β-发夹中的两个β链一般通过换向序列相连接。
优选地,适用于β-发夹的换向序列是I型、I′型、II型、II′型、III型或III′型换向序列,更优选为I型、I′型、II型、II′型换向序列,进而优选为I′型或II′型换向序列,最优选为I′型换向序列。并且,由X-Pro-Gly-Glu-Val;或Ala-X-Gly-Glu-Val(X选自20个氨基酸中)表示的换向序列也能利用于β-发夹。
根据本发明的例示性的实施例,I型换向序列为Asp-Asp-Ala-Thr-Lys-Thr,I′型换向序列是Glu-Asn-Gly-Lys,II型换向序列为X-Pro-Gly-Glu-Val或Ala-X-Gly-Glu-Val(X选自20个氨基酸中),II′型换向序列为Glu-Gly-Asn-Lys或Glu-D-Pro-Asn-Lys。
具有β-发夹构象的肽已为本领域所熟知。例如熟知的有在美国专利第6,914,123号及Andrea G.Cochran et al.,PNAS,98(10):5578-5583)中公开的色氨酸拉链、在WO 2005/047503中公开的被铸型固定的β-发夹模拟体、在美国专利第5,807,979号中公开的各β-发夹变形体。此外,具有β-发夹构象的肽公开在Smith&Regan(1995)Science 270:980-982;Chou&Fassman(1978)Annu.Rev.Biochem.47:251-276;Kim&Berg(1993)Nature 362:267-270;Minor&Kim(1994)Nature 367:660-663;Minor&Kim(1993)Nature 371:264-267;Smith et al.Biochemistry(1994)33:5510-5517;Searle et al.(1995)Nat.Struct.Biol.2:999-1006;Haque&Gellman(1997)J.Am.Chem.Soc.119:2303-2304;Blanco et al.(1993)J.Am.Chem.Soc.115:5887-5888;de Alba et al.(1996)Fold.Des.1:133-144;de Alba et al.(1997)Protein Sci.6:2548-2560;Ramirez-Alvarado et al.(1996)Nat.Struct.Biol.3:604-612;Stanger&Gellman(1998)J.Am.Chem.Soc.120:4236-4237;Maynard&Searle(1997)Chem.Commun.1297-1298;Griffiths-Jones et al.(1998)Chem.Commun.789-790;Maynard et al.(1998)J.Am.Chem.Soc.120:1996-2007;及Blanco et al.(1994)Nat.Struct.Biol.1:584-590中,上述文献作为参照内容编入本说明书中。
将具有β-发夹构象的肽用作结构稳定化区时,最优选为利用色氨酸拉链。
根据本发明的优选实施例,本发明中所利用的色氨酸拉链由以下通式I表示:
通式I
X1-Trp(X2)X3-X4-X5(X′2)X6-X7
X1为Ser或Gly-Glu,X2及X′2相互独立地为Thr、His、Val、Ile、Phe或Tyr,X3为Trp或Tyr,X4为I型、I′型、II型、II′型或III型或III′型换向序列,X5为Trp或Phe,X6为Trp或Val,X7为Lys或Thr-Glu。
更优选地,在上述通式I中,X1为Ser或Gly-Glu,X2及X′2相互独立地为Thr、His或Val,X3为Trp或Tyr,X4为I型、I′型、II型或II′型换向序列,X5为Trp或Phe,X6为Trp或Val,X7为Lys或Thr-Glu。
进而优选地,在通式I中,X1为Ser或Gly-Glu,X2及X′2相互独立地为Thr、His或Val,X3为Trp,X4为I型、I′型、II型或II′型换向序列,X5为Trp,X6为Trp,X7为Lys或Thr-Glu。
再而优选地,在通式I中,X1为Ser,X2及X′2为Thr,X3为Trp,X4为I′型或II′型换向序列,X5为Trp,X6为Trp,X7为Lys。
最优选地,在通式I中,X1为Ser,X2及X′2为Thr,X3为Trp,X4为I′型换向序列(ENGK)或II′型换向序列(EGNK),X5为Trp,X6为Trp,X7为Lys。
适合于本发明的色氨酸拉链的例示性氨基酸序列记载于序列目录第1序列至第3序列以及第5序列至第10序列。
在本发明中,能够用作结构稳定化区的β-发夹肽是来源于蛋白质G的B1域的肽,即为GB1肽。
在本发明中利用GB1肽时,优选地,结构稳定化区由以下通式II表示:
通式II
X1-Trp-X2-Tyr-X3-Phe-Thr-Val-X4
X1为Arg、Gly-Glu或Lys-Lys,X2为Gln或Thr,X3为I型、I′型、II型、II′型或III型或III′型换向序列,X4为Gln、Thr-Glu或Gln-Glu。
更优选地,通式II的结构稳定化区由以下通式II′表示:
通式II
X1-Trp-Thr-Tyr-X2-Phe-Thr-Val-X3
X1为Gly-Glu或Lys-Lys,X2为I型、I′型、II型、II′型或III型或III′型换向序列,X3为Thr-Glu或Gln-Glu。
适合于本发明的GB1β-发夹的例示性氨基酸序列记载于序列目录第4序列以及第14序列至第15序列。
在本发明中,能够用作结构稳定化区的β-发夹肽是HP肽。本发明中利用HP肽时,优选地,结构稳定化区由以下通式III表示:
通式III
X1-X2-X3-Trp-X4-X5-Thr-X6-X7
X1为Lys或Lys-Lys,X2为Trp或Tyr,X3为Val或Thr,X4为I型、I′型、II型、II′型或III型或III′型换向序列,X5为Trp或Ala,X6为Trp或Val,X7为Glu或Gln-Glu。
在本发明中,能够用作结构稳定化区的其他β-发夹肽由以下通式IV表示:
通式IV
X1-X2-X3-Trp-X4
X1为Lys-Thr或Gly,X2为Trp或Tyr,X3为I型、I′型、II型、II′型或III型或III′型换向序列,X4为Thr-Glu或Gly。
通式III及通式IV的β-发夹的例示性氨基酸序列记载于序列目录第11序列至第12序列、第15序列以及第16序列至第19序列。
根据本发明,能够将通过连接物连接的β-折叠用作结构稳定化区。在β-折叠结构中,在β-折叠结构中,平行或反平行的、优选为反平行的两个氨基酸链形成为延伸结构(extended form),在氨基酸链之间形成氢键。
在β-折叠结构中,两个氨基酸链的相邻的两个末端通过连接物相连接。作为连接物能够利用上述多种换向-序列或肽连接物。将换向-序列用作连接物时,最优选为β-换向序列。
根据本发明的另一变形例,能够将亮氨酸拉链或通过连接物连接的亮氨酸拉链用作结构稳定化区。亮氨酸拉链是引起平行的2个α-链的二聚化的保存性肽结构域,一般是从参与基因表达的蛋白质发现的二聚化结构域(″Leucine scissors″.Glossary of Biochemistry and Molecular Biology(Revised).(1997).Ed.David M.Glick.London:Portland Press;Landschulz WH,et al.(1988)Science240:1759-1764)。亮氨酸拉链一般包含七肽(heptad)重复序列,亮氨酸残基位于第4或第5位置。例如能够利用于本发明的亮氨酸拉链包含LEALKEK、LKALEKE、LKKLVGE、LEDKVEE、LENEVAR或LLSKNYH的氨基酸序列。本发明中所利用的亮氨酸拉链的具体例子记载于序列目录第39序列。亮氨酸拉链的各一半由较短的α-链组成,亮氨酸直接接触于α-链之间。转录因子的亮氨酸拉链一般由疏水性亮氨酸拉链区及碱性区(是与DNA分子的主沟槽相互作用的区)构成。本发明中利用亮氨酸拉链时,并非必然需要碱性区。亮氨酸拉链结构中两个氨基酸链(即,两个α-链)的相邻的两个末端能够通过连接物相连接。作为连接物能够利用上述的多种换向-序列或肽连接物,优选地利用不影响亮氨酸拉链的结构的肽连接物。
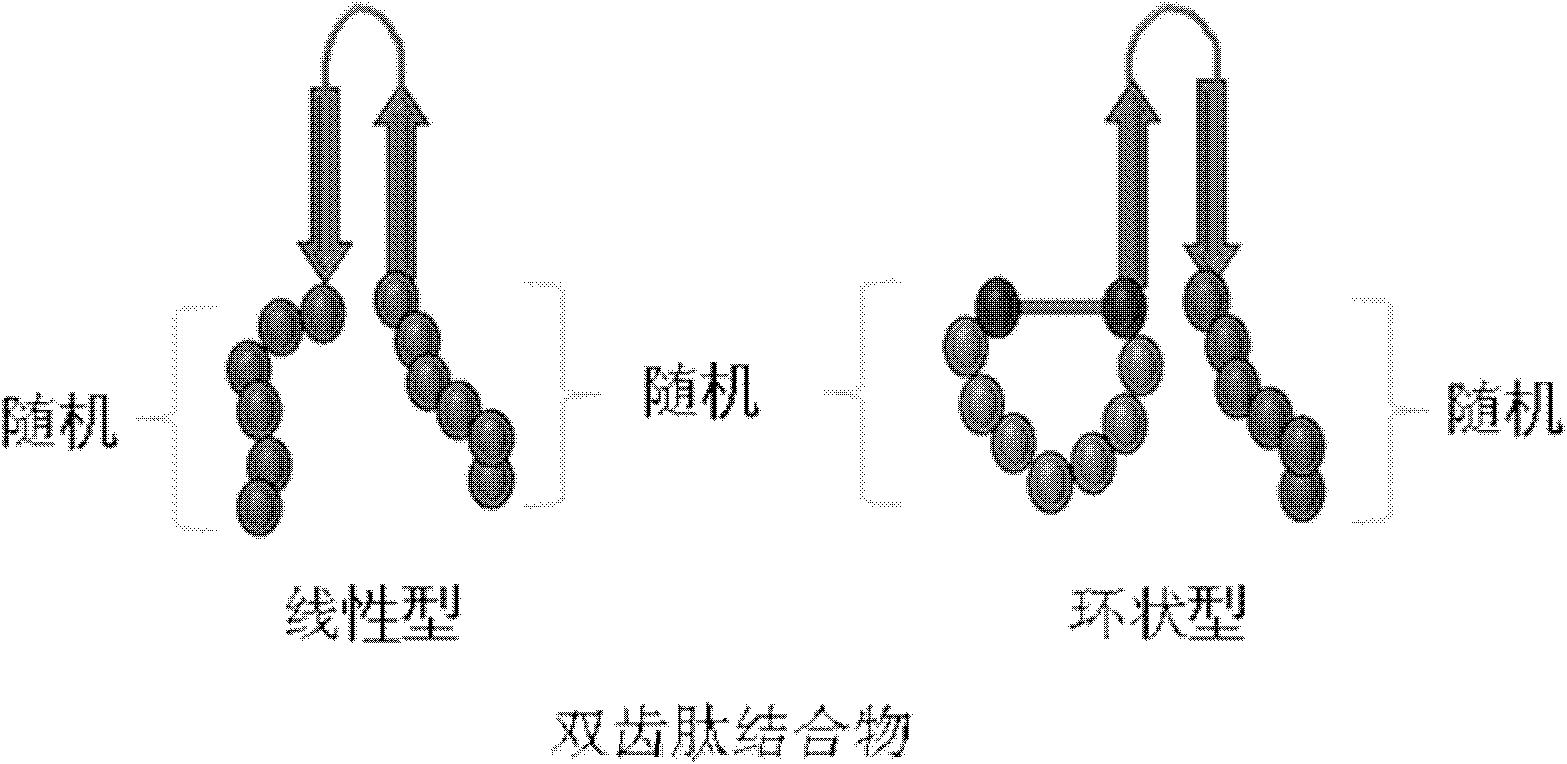
在上述的结构稳定化区的两个末端将结合随机氨基酸序列。上述随机氨基酸序列形成靶结合区I及靶结合区II。本发明的一个最大的特征在于:在结构稳定化区的两侧末端连接靶结合区I及靶结合区II,而以双齿方式制造肽结合物。靶结合区I及靶结合区II相互配合地(cooperatively)与靶结合,从而大大地增加对于靶的亲和力。
靶结合区I的氨基酸数量n不受特殊限制,优选为2-100的整数,更优选为2-50的整数,进而优选为2-20的整数,最优选为3-10的整数。
靶结合区II的氨基酸数量m不受特殊限制,优选为2-100的整数,更优选为2-50的整数,进而优选为2-20的整数,最优选为3-10的整数。
靶结合区I及靶结合区II中能够包含数量相互不同或相同的氨基酸残基。靶结合区I及靶结合区II中能够包含相互不同或相同的氨基酸序列,优选为包含相互不同的氨基酸序列。
包含于靶结合区I和/或靶结合区II的氨基酸序列是线性型氨基酸序列或环状型氨基酸序列。为了增加靶结合区的肽序列的稳定性,在包含于靶结合区I和/或靶结合区II的氨基酸序列中至少一个氨基酸残基能够变形为乙酰基、芴甲氧羰酰基、甲酸基、棕榈酰基、肉豆蔻基、硬脂酰基或聚乙二醇(PEG)。
与生物学靶分子结合的本发明的双齿肽结合物能够利用于生体内生理学反应的调节、生体内物质的检测、体内分子成像、体外细胞成像以及药物传递用靶向,并能够用作保护分子。
根据本发明的优选实施例,在结构稳定化区、靶结合区I或靶结合区II(更优选为结构稳定化区,进而优选为结构稳定化区的连接物)追加结合有功能性分子。上述功能性分子的例子包含产生能够检测的信号的标记物、化学药物、生物药物、细胞穿透肽(CPP)或纳米粒子,但不限于此。
上述产生能够检测的信号的标记物包含T1造影物质(例如Gd螯合物)、T2造影物质(例如超顺磁性物质(例:磁铁矿、Fe3O4、γ-Fe2O3、锰铁氧体、钴铁氧体以及镍铁氧体))、放射性同位素(例如11C、15O、13N、P32、S35、44Sc、45Ti、118I、136La、198Tl、200Tl、205Bi以及206Bi)、荧光物质(荧光素(fluorescein)、藻红素(phycoerythrin)、罗丹明、丽丝胺(lissamine)以及Cy3和Cy5)、化学发光团、磁性颗粒、大量标志或密电子颗粒,但不限于此。
上述化学药物例如包含抗炎剂、镇痛剂、抗风湿剂、镇痉剂、抗抑郁剂、抗精神病药物、镇静剂、抗焦虑剂、抗麻醉剂、抗帕金森病药物、胆碱能激动剂、抗癌剂、抗血管生成抑制剂、免疫抑制剂、抗病毒剂、抗生素、厌食剂、镇痛剂、抗胆碱能药物、抗组胺剂、抗偏头痛药物、激素药、冠状血管、脑血管或周围血管扩张药、避孕药、抗血栓剂、利尿剂、抗高血压药、心血管病治疗剂、美容成分(例如皱纹改善剂、皮肤老化抑制剂以及皮肤美白剂)等,但不限于此。
上述生物药物能够是胰岛素、IGF-1(insulin-like growth factor1)、生长激素、红细胞生成素、G-CSFs(granulocyte-colony stimulating factors)、GM-CSFs(granulocyte/macrophage-colony stimulating factors)、干扰素-α、干扰素-β、干扰素-γ、白细胞介素-1α及β、白细胞介素-3、白细胞介素-4、白细胞介素-6、白细胞介素-2、EGFs(epidermal growth factors:表皮生长因子)、降血钙素(calcitonin)、ACTH(adrenocorticotropic hormone:促肾上腺皮质素)、TNF(tumor necrosis factor:肿瘤坏死因子)、阿托西班(atosiban)、布舍瑞林(buserelin)、西曲瑞克(cetrorelix)、地洛瑞林(deslorelin)、去氨加压素(desmopressin)、强啡肽A(dynorphin A)(1-13)、依降钙素(elcatonin)、章鱼唾腺精(eledoisin)、依替巴肽(eptifibatide)、GHRH-II(growth hormone releasing hormone-II:生长素释放激素-II)、戈那瑞林(gonadorelin)、戈舍瑞林(goserelin)、组氨瑞林(histrelin)、亮丙瑞林(leuprorelin)、赖氨加压素(lypressin)、奥曲肽(octreotide)、催产素(oxytocin)、加压素(pitressin)、分泌素(secretin)、辛卡利特(sincalide)、特利加压素(terlipressin)、胸腺喷丁(thymopentin)、胸腺素(thymosine)α1、曲普瑞林(triptorelin)、比伐卢定(bivalirudin)、卡贝缩官素(carbetocin)、环孢霉素、艾可西定(exedine)、兰乐肽(lanreotide)、LHRH(luteinizing hormone-releasing hormone:黄体生成素释放激素)、纳发阮林(nafarelin)、甲状旁腺素、普兰林肽(pramlintide)、T-20(enfuvirtide)、胸腺法新(thymalfasin)、齐考诺肽、RNA、DNA、cDNA、反义寡核苷酸以及siRNA,但不限于此。
靶结合区I和/或靶结合区II能够包含与多种靶结合的氨基酸序列。能够被本发明的双齿肽结合物进行靶向的是生化物质、肽、多肽、核酸、碳水化合物、脂质、诸如细胞及组织的生物学靶、化合物、金属或非金属物质,优选为生物学靶。
由靶结合区结合的生物学靶优选为生化物质、肽、多肽、糖蛋白、核酸、碳水化合物、蛋白聚糖、脂质或糖脂。
例如由靶结合区结合的生化物质包含多种生体内代谢产物(例如ATP、NADH、NADPH、碳水化合物代谢产物、脂质代谢产物以及氨基酸代谢产物)。
由靶结合区结合的例示性肽或多肽包含酶、配位体、受体、生物标志、激素、转录因子、生长因素、免疫球蛋白、信号转导蛋白质、结合蛋白质、离子通道、抗原、粘附蛋白、结构蛋白质、调节蛋白质、毒蛋白质、细胞因子以及凝血因子,但不限于此。更详细地,双齿肽结合物的靶包含Fibronectin extra domain B(ED-B)、VEGF(vascular endothelial growth factor)、VEGFR(vascular endothelial growth factor receptor)、VCAM1(vascular cell adhesion molecule-1)、nAchR(Nicotinic acetylcholine receptor)、HAS(Human serum albumin)、MyD88、EGFR(Epidermal Growth Factor Receptor)、HER2/neu、CD20、CD33、CD52、EpCAM(Epithelial Cell Adhesion Molecule)、TNF-α(Tumor Necrosis Factor-α)、IgE(Immunoglobulin E)、CD11A(α-chain of lymphocyte function-associated antigen 1)、CD3、CD25、Glycoprotein IIb/IIIa、整合素、AFP(Alpha-fetoprotein)、β2M(Beta2-microglobulin)、BTA(Bladder Tumor Antigens)、NMP22、Cancer Antigen 125、Cancer Antigen 15-3、降血钙素、Carcinoembryonic Antigen、Chromogranin A、雌激素受体、孕激素受体、Human Chorionic Gonadotrop in、Neuron-Specific Enolase、PSA(Prostate-Specific Antigen)、PAP(Prostatic Acid Phosphatase)以及Thyroglobulin,但不限于此。
由靶结合区结合的例示性核酸分子包含gDNA、mRNA、cDNA、rRNA(ribosomal RNA)、rDNA(ribosomal DNA)以及tRNA,但不限于此。由靶结合区结合的例示性碳水化合物是生体内碳水化合物,其包含单糖、双糖、三糖以及多糖,但不限于此。由靶结合区结合的例示性脂质包含脂肪酸、三脂酰甘油、鞘脂、神经节苷脂以及胆固醇,但不限于此。
本发明的双齿肽结合物能够与露出在细胞表面的生体分子(例如蛋白质)结合,但也能与细胞内的生体分子(例如蛋白质)结合,由此能够调节生体分子的活性。
优选地,双齿肽结合物对细胞内的蛋白质进行靶向时,双齿肽结合物还包含细胞穿膜肽(CPP)。
上述CPP包含本领域中公开的多种CPP,例如包含HIV-1Tat蛋白质、Tat肽类似物(例如寡聚精氨酸)、ANTP肽、HSV VP22转录调控蛋白质、来源于vFGF的MTS肽、Penetratin、Transportan或Pep-1肽,但不限于此。将上述CPP与双齿肽结合的方法有多种方法,例如使位于双齿肽的结构稳定化区的环形部分的赖氨酸残基与CPP进行共价键合。
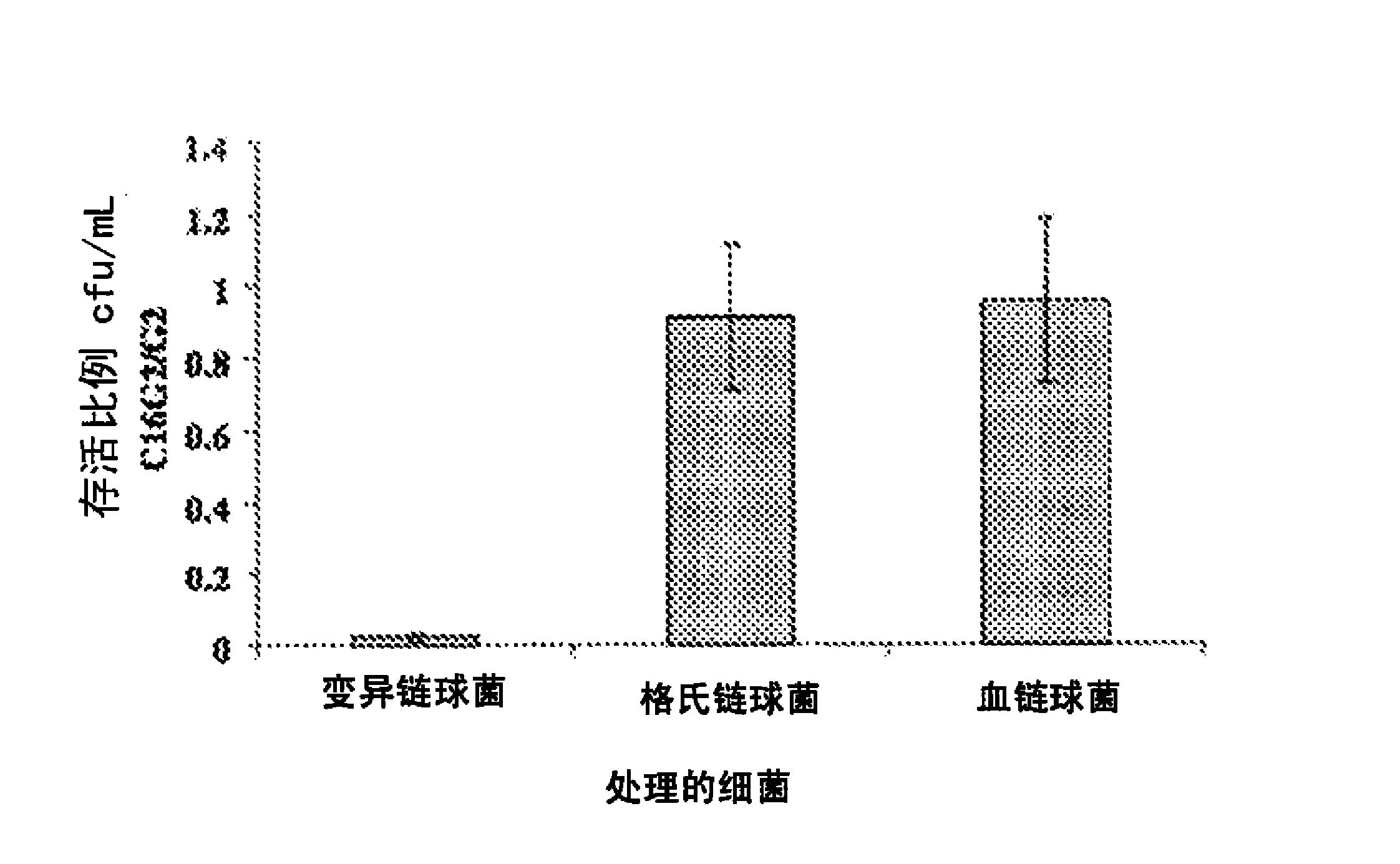
细胞内有着对生理活性起着重要作用的很多靶蛋白,结合有CPP的双齿肽结合物流入到细胞内与该靶蛋白结合而调节(例如抑制)活性。以下实施例19表示双齿肽结合物对细胞内蛋白质进行的靶向的具体例子。MyD88被广知为与TLR 4、白细胞介素1受体、RAC1、IRAK2以及IRAK1相互作用的细胞内蛋白质。由于对MyD88有着结合特异性的CPP-双齿肽结合物进入到细胞内抑制MyD88的功能,从而有效地阻断MMP-13的表达。
如上所述,本发明的双齿肽结合物具有典型的“N-靶结合区I-结构稳定化区的一个链-连接物-结构稳定化区的另一链-靶结合区II-C”组织。
根据本发明的优选实施例,本发明的双齿肽结合物中靶结合区I和结构稳定化区的一个链之间和/或结构稳定化区的另一链-靶结合区II之间包含阻断靶结合区与结构稳定化区之间的相互结构性影响的结构影响抑制区(structure influence inhibiting region)。肽分子中 和ψ的旋转比较自由的氨基酸位于旋转区。 和ψ的旋转比较自由的氨基酸优选为甘氨酸、丙氨酸及丝氨酸。在结构影响抑制区能够具有1-10个氨基酸残基,优选为1-8个,更优选为1-3个。
具有上述组织的本发明的双齿肽结合物的文库能够通过本领域中所公知的多种方法而获得。在该文库中双齿肽结合物具有随机序列,这意味着在靶结合区I和/或靶结合区II的任何位置上均无顺序偏好(sequence preference)或指定(或固定)的氨基酸残基。
例如双齿肽结合物的文库能够根据在固相载体(例如聚苯乙烯或聚丙烯酰胺树脂)上实施的均分合成法(Lam et al.(1991)Nature354:82;WO 92/00091)而构建。
根据本发明的优选实施例,双齿肽结合物的文库以细胞表面展示(cell surface display)方式(例如噬菌体展示、细菌展示或酵母展示)构建。优选地,双齿肽结合物的文库能够通过基于质粒、细菌噬菌体、噬菌粒、酵母、细菌、mRNA或核糖体的展示方式生成。
噬菌体展示是以与噬菌体表面上的外壳蛋白融合的蛋白质形态展示各种多肽的技术(Scott,J.K.and Smith,G.P.(1990)Science 249:386;Sambrook,J.et al.,Molecular Cloning.A Laboratory Manual,3rd ed.Cold Spring Harbor Press(2001);Clackson and Lowman,Phage Display,Oxford University Press(2004))。在丝状噬菌体(例如M13)的基因III或基因VIII融合所要表达的基因而展示随机肽。
噬菌体展示中能够利用噬菌粒。噬菌粒是具有细菌的复制起点(例如ColE1)及细菌噬菌体的基因间(intergenic)区的一副本的质粒载体。克隆在该噬菌粒的DNA片段如质粒一样增殖。
以噬菌体展示的方式构建双齿肽结合物的文库时,本发明的优选实施例包含如下步骤:(i)制造表达载体文库的步骤,该文库包含由对噬菌体外壳蛋白质(例如如M13的丝状噬菌体的基因III或基因VIII的外壳蛋白质)进行编码的基因和对双齿肽结合物进行编码的基因融合的融合基因;以及与上述融合基因操作性地结合的转录调节序列(例如lac启动子);(ii)将上述表达载体的文库导入至适合的宿主细胞的步骤;(iii)培养上述宿主细胞,形成重组噬菌体或噬菌粒病毒粒子,使得融合蛋白质展示在表面上的步骤;(iv)使生物学靶分子与上述病毒粒子接触,而使粒子与靶分子结合的步骤;以及(v)分离不与靶分子结合的粒子的步骤。
利用噬菌体展示来构建肽文库,在美国专利第5,723,286号、第5,432,018号、第5,580,717号、第5,427,908号、第5,498,530号、第5,770,434号、第5,734,018号、第5,698,426号、第5,763,192号及第5,723,323号中公开了对这些文库进行淘选的方法。
包含双齿肽结合物基因的表达载体的制造方法能够根据本领域中公知的方法而实施。例如能够在公知的噬菌粒或吞噬载体(例如pIGT2、fUSE5、fAFF1、fd-CAT1、m663、fdtetDOG、pHEN1、pComb3、pComb8、pCANTAB 5E(Pharmacia)、LamdaSurfZap、pIF4、PM48、PM52、PM54、fdH及p8V5)插入双齿肽结合物基因而制造表达载体。
虽然大部分噬菌体展示方式利用丝状噬菌体来实施,但λ噬菌体展示(WO 95/34683;美国专利第5,627,024号)、T4噬菌体展示(Renet al.(1998)Gene 215:439;Zhu(1997)CAN 33:534)及T7噬菌体展示(美国专利第5,766,905号)也能利用于双齿肽结合物的文库构建。
将载体文库导入至适当的宿主细胞的方法能根据多种转化方法而实施,最优选地,根据电穿孔(electroporation)法而实施(参照美国专利第5,186,800号、第5,422,272号、第5,750,373号)。适合于本发明的宿主细胞是如E.coli的革兰氏阴性菌细胞,适合的E.coli宿主细胞包含JM101、E.coli K12 strain 294、E.coli strain W3110以及E.coli XL-1Blue(Stratagene),但不限于此。宿主细胞优选在转化之前准备为感受态细胞(Sambrook,J.et al.,Molecular Cloning.ALaboratory Manual,3rd ed.Cold Spring Harbor Press(2001))。对于转化的细胞的淘选一般在包含抗生素(例如四环素及氨苄青霉素)的培养基中培养该细胞而实施。在存在辅助噬菌体的情况下追加培养经过淘选的转化细胞而生成重组噬菌体或噬菌体病毒粒子。适合用作上述辅助噬菌体的包含Ex辅助噬菌体、M13-KO7、M13-VCS以及R408,但不限于此。
与生物学靶分子结合的病毒粒子的淘选通常能够通过生物淘选过程而实施(Sambrook,J.et al.,Molecular Cloning.A Laboratory Manual,3rd ed.Cold Spring Harbor Press(2001);Clackson and Lowman,Phage Display,Oxford University Press(2004))。
本发明的双齿肽结合物的具体例子记载于序列目录第20序列-第38序列及第40序列-第41序列。
根据本发明的另一实施方式,本发明提供一种对上述双齿肽结合物进行编码的核酸分子。
根据本发明的还一实施方式,本发明提供一种包含对双齿肽结合物进行编码的核酸分子的双齿肽结合物的表达载体。
根据本发明的再一实施方式,本发明提供一种包含双齿肽结合物的表达用载体的转化体。
本说明书中的术语“核酸分子”具有总括DNA(gDNA及cDNA)及RNA分子的意思,作为核酸分子的基本结构单位的核苷酸不仅包含天然的核苷酸,还包含由糖基或碱基区变形的类似物(analogue)(Scheit,Nucleotide Analogs,John Wiley,New York(1980);Uhlman及Peyman,Chemical Reviews,90:543-584(1990))。
根据本发明的优选实施例,本发明的载体除了对双齿肽结合物进行编码的核酸分子以外还包含能够对上述核酸分子进行转录的强效启动子(例如tac启动子、lac启动子、lacUV5启动子、lpp启动子、pLλ启动子、pRλ启动子、rac5启动子、amp启动子、recA启动子、SP6启动子、trp启动子及T7启动子等)、用于开始翻译的核糖体结合位点及转录/翻译终结序列。
根据本发明的优选实施例,本发明的载体还能够在对双齿肽结合物进行编码的核酸分子的5‘-方向侧包含信号序列(例如pelB)。而且,根据本发明的优选实施例,本发明的载体还能够包含用于确认双齿肽结合物在噬菌体表面上是否表达好的标记序列(例如myc tag)。
根据本发明的优选实施例,本发明的载体包含对噬菌体外壳蛋白质,优选为如M13的丝状噬菌体的基因III或基因VIII的外壳蛋白质进行编码的基因。根据本发明的优选实施例,本发明的载体包含细菌的复制起点(例如ColE1)和/或细菌噬菌体的复制起点。另一方面,本发明的载体作为选择标志能够包含通常利用于本领域中的抗生素抗性基因,例如能够包含对氨苄青霉素、庆大霉素、羧苄青霉素、氯霉素、链霉素、卡那霉素、遗传霉素、新霉素以及四环素的抗性基因。
本发明的转化体优选为如E.coli的革兰氏阴性菌细胞,适合的E.coli宿主细胞包含JM101、E.coli K12 strain 294、E.coli strainW3110及E.coli XL-1Blue(Stratagene),但不限于此。将本发明的载体运送到宿主细胞内的方法能够通过CaCl2法(Cohen,S.N.et al.,Proc.Natl.Acac.Sci.USA,9:2110-2114(1973))、Hanahan方法(Cohen,S.N.et al.,Proc.Natl.Acac.Sci.USA,9:2110-2114(1973);以及Hanahan,D.,J.Mol.Biol.,166:557-580(1983))及电穿孔法(美国专利第5,186,800号、第5,422,272号、第5,750,373号)等而实施。
本发明的双齿肽结合物提供一种表现出极低水平(例如nM水平)的KD值(解离常数),而对生物学靶分子表现出十分高的亲和力的肽。如以下实施例所述,与以单齿(monopodal)方式制造的结合物进行比较时,双齿肽结合物表现出高达约102-105倍(优选为约103-104倍)的高亲和力。
本发明的双齿肽结合物不仅具有医药用途,同时还能用于生物体内物质检测、体内分子成像、体外细胞成像以及药物传递用靶向,并且用作保护分子也非常有效。
归纳本发明的特征及优点为如下:
(i)本发明提供一种具有新型组织的双齿肽结合物。
(ii)本发明的双齿肽结合物中结合在结构稳定化区的两个末端的末梢的(distal)两个靶结合区相互配合地(cooperatively)、协同地(synergetically)与靶结合。
(iii)因此,本发明的双齿肽结合物表现出极低水平(例如nM水平)的KD值(解离常数),对靶分子表现出十分高的亲和力。
(iv)本发明的双齿肽结合物不仅具有医药用途,还能用于生物体内物质检测、体内分子成像、体外细胞成像以及药物传递用靶向,并且用作保护分子也非常有效。
附图说明【附图说明】
图1a表示包含作为结构稳定化区的β-发夹(hairpin)的双齿肽结合物(bipodal-peptide binder)的示意图。
图1b表示包含作为结构稳定化区的通过连接物连接的β-折叠的双齿肽结合物(bipodal-peptide binder)的示意图。
图1c表示包含作为结构稳定化区的通过连接物连接的亮氨酸拉链的双齿肽结合物(bipodal-peptide binder)的示意图。
图1d表示包含作为结构稳定化区的通过连接物连接的富亮氨酸基序(leucine-rich motif)的双齿肽结合物(bipodal-peptide binder)的示意图。
图2表示用于克隆双齿肽结合物文库的策略。在pIGT2噬菌粒载体图中,pelB信号序列、myc tag是用于确认靶基因在噬菌体表面上是否表达好的标记序列。将lac启动子用作了启动子。
图3表示纤维连接蛋白ED-B生物淘选过程中对于输入的噬菌体(Input phage)的ED-B、链霉亲和素以及BSA的生物淘选结果。
图4表示纤维连接蛋白ED-B生物淘选过程中对于在双齿肽结合物文库的生物淘选的第三步骤中回收的60种重组噬菌体的ED-B及BSA的ELISA结果。
图5a表示与纤维连接蛋白ED-B蛋白质结合的特定双齿肽结合物的亲和力的测定结果。
图5b表示与VEGF结合的特定双齿肽结合物的亲和力的测定结果。
图5c表示与VCAM1结合的特定双齿肽结合物的亲和力的测定结果。
图5d表示与nAchR(Nicotinic acetylcholine receptor)结合的特定双齿肽结合物的亲和力的测定结果。
图5e表示与HAS(Human Serum Albumin)结合的特定双齿肽结合物的亲和力的测定结果。
图6a表示为了检测纤维连接蛋白ED-B的特异性,将具有双齿肽结合物的重组噬菌体针对各种蛋白质进行ELISA而测定吸光度的结果。从左侧条开始是关于链霉亲和素、ED-B、乙酰胆碱α1、BSA、VCAM、TNF-α、凝血酶、肌红蛋白、溶菌酶及内脏脂肪素的结果。
图6b表示为了检测VEGF的特异性,将具有双齿肽结合物的重组噬菌体针对各种蛋白质进行ELISA而测定吸光度的结果。
图6c表示为了检测VCAM1的特异性,将具有双齿肽结合物的重组噬菌体针对各种蛋白质进行ELISA而测定吸光度的结果。
图6d表示为了检测nAchR片段肽的特异性,将具有双齿肽结合物的重组噬菌体针对各种蛋白质进行ELISA而测定吸光度的结果。
图6e表示为了检测HSA的特异性,将具有双齿肽结合物的重组噬菌体针对各种蛋白质进行ELISA而测定吸光度的结果。
图6f表示为了检测MyD88的特异性,将具有双齿肽结合物的重组噬菌体针对各种蛋白质进行ELISA而测定吸光度的结果。
图7表示用于证明双齿肽结合物的共同作用效果的亲和力的测定结果。
图8表示在双齿肽结合物中将结构稳定化区的色氨酸拉链替代为各种β-发夹基序而测定双齿肽结合物的亲和力的结果。
图9表示在双齿肽结合物中将结构稳定化区的色氨酸拉链替代为亮氨酸拉链而测定双齿肽结合物的亲和力的结果。
图10表示对作为癌症生物标记物的纤维连接蛋白ED-B显现特异性的双齿肽结合物的癌症靶向结果。随着时间的经过能够观察到双齿肽结合物蓄积在癌细胞上。当分离各器官而测定荧光时,也能观察到双齿肽结合物大量蓄积在癌细胞上。
图11表示对存在于细胞内的抑制MyD88活性的特异性双齿肽结合物的效果进行了证明的结果。
具体实施方式【具体实施方式】
下面,通过实施例对本发明进行更详细的说明。这些实施例只是为了更具体地说明本发明而提出的,根据本发明的原理,很显然对于本领域的普通技术人员来说,本发明的技术领域不由这些实施例决定。
【实施例】
【实验材料与实验方法】
【实施例1:文库的制造】
【双齿肽结合物基因制造及向噬菌粒载体的插入】
合成了2个寡核苷酸Beta-F1(5′-TTCTATGCGGCCCAGCTGGCC(NNK)6GGATCTTGGACATGGGAAAACGGAAAA-3′)及Beta-B1(5′-AACAGTTTCTGCGGCCGCTCCTCC TCC(MNN)6TCCCTTCCATGTCCATTTTCCGTT-3′)(N为A、T、G或C;K为G或T;M为C或A)。为了制造双链,混合Beta-F1 4μM、Beta-B14μM、2.5mM dNTP混合液4μl、ExTaq DNA聚合酶1μl(Takara公司,首尔,韩国)及10×PCR缓冲液5μl后添加蒸馏水使其总量为50μl而制造了25种混合液。使该混合液进行PCR反应(在94℃条件下进行5分钟,60周期:在30℃条件下进行30秒,在72℃条件下进行30秒,以及在72℃条件下进行7分钟)而制造成双链后,利用PCR纯化试剂盒(GeneAll公司,首尔,韩国)进行纯化而得到双齿肽结合物基因。为了将待插入于双齿肽结合物的基因与pIGT2噬菌粒载体(Igtherapy,春川,韩国)连接,用限制酶对插入基因与pIGT2噬菌粒载体进行处理。对约11μg的插入DNA用SfiI(New England Biolabs(NEB,Ipswich)及NotI(NEB,Ipswich)分别进行4小时的反应之后利用PCR纯化试剂盒进行纯化。而且,对约40μg的pIGT2噬菌粒载体用SfiI及NotI分别进行4个小时的反应之后,投入CIAP(Calf Intestinal Alkaline Phosphatase)(NEB,Ipswich)而进行1小时的反应之后利用PCR纯化试剂盒进行纯化。用UV-可见光分光光度计(Ultrospec 2100pro,Amersham Bioscience)对其进行定量后,利用T4 DNA连接酶(Bioneer公司,大田,韩国)使2.9μg的插入基因与pIGT2噬菌粒载体12μg,在18℃条件下连接15小时后,用乙醇进行沉淀,用TE缓冲液100μl溶解DNA。
【准备感受态细胞】
在LB琼脂平板上划线涂抹E.coli XL1-BLUE细胞(American Type Culture Collection公司,马纳萨斯,美国)。将在琼脂平板培养基生长的群落接种到5ml的LB培养基后,在37℃条件下以200rpm的速度进行混合而培养一天。将培养的10ml的各细胞接种到2l的LB培养基后,以相同的方式进行培养,直至吸光度在600nm的波长中达到0.3-0.4为止。将培养的烧瓶在冰上放置30分钟后,在4℃条件下以4,000×g进行离心分离20分钟,由此去除除了沉淀的细胞以外的所有上清液,并且用1l的经冷却的灭菌蒸馏水进行悬浮。以相同的方法重新对其进行离心分离去除上清液后,用1l的经冷却的灭菌蒸馏水重新进行悬浮,并以相同的方式用10%的甘油溶液40ml反复清洗而离心分离后,每一次分注200μl而在液态氮的条件下进行冷冻后,在-80℃条件下保管。
【电穿孔法】
将在噬菌粒载体12μg和双齿肽结合物中使2.9μg的插入DNA进行连接反应的100μl的反应溶液分注为25份进行电穿孔法。在冰上解冻感受态细胞,将200μl的感受态细胞与经过连接反应的4μl溶液混合后进行冷却而放入到准备好的0.2cm试管中,然后在冰上放置1分钟。在200Ω条件下,以25μF及2.5kV的条件,对电穿孔仪(BioRad,Hercules,CA)进行程序设定后,去除准备好的试管上的水分,并将其定位于电穿孔仪之后施加脉冲(时间常数为4.5-5msec)。而后立即将其放入到准备好的37℃的包含20mM葡萄糖的1ml的LB液体培养基,将得到的总共为25ml的细胞转移到100ml试管中。在37℃条件下,以200rpm混合而培养一小时后,为了测定文库的数量稀释10μl而涂抹在氨苄青霉素琼脂培养基上。将剩下的细胞放入到1l的LB,其中放入20mM葡萄糖及50μg/ml的氨苄青霉素,在30℃条件下培养一天。在4℃条件下,以4,000×g进行20分钟的离心分离,由此去除除了沉淀的各细胞以外的所有上清液,并且用40ml的LB重新进行悬浮后放入达到最终浓度20%以上的甘油,并在-80℃条件下保管。
【文库中重组噬菌体的生产和PEG的沉淀】
在-80℃条件下贮存的双齿肽结合物文库中生产重组噬菌体。在500ml烧瓶中放入添加了氨苄青霉素(50μg/ml)及20mM葡萄糖的100ml的LB液体培养基后,填加在-80℃条件下贮存的文库1ml,并在37℃条件下,以150rpm混合而培养一小时。其中放入1×1011pfu的Ex辅助噬菌体(Ig therapy,春川,韩国)以相同的条件重新培养一小时。以1,000×g进行10分钟的离心分离,由此去除上清液,向此放入包含氨苄青霉素(50μg/ml)及卡那霉素(25μg/ml)的LB液体培养基100ml之后培养一天,从而生产重组噬菌体。在以3,000×g对培养液进行10分钟的离心分离而得到的100ml上清液中混合25ml的PEG/NaCl,然后在冰上放置1小时后,在4℃条件下,以10,000×g进行20分钟的离心分离,由此谨慎地去除上清液,并用2ml的PBS(pH 7.4)重新对颗粒进行悬浮。
【实施例2:准备蛋白质】
如下地准备了将在实施例中用到的纤维连接蛋白(Fibronectin)ED-B、VEGF(vascular endothelial growth factor)、VCAM1(vascular cell adhesion molecule-1)、nAchR(Nicotinic acetylcholine receptor)、HSA(Human serum albumin)及MyD88。
【纤维连接蛋白ED-B基因制造及向表达载体的插入】
从韩国生命工程研究院中接收了部分人体纤维连接蛋白ED-B(ID=KU017225)基因。通过合成引物EDB_F1(5′-TTCATAACATATGCCAGAGGTGCCCCAA-3′)及EDB_B1(5′-ATTGGATCCTTACGTTTGTTGTGTCAGTGTAGTAGGGGCACTCTCGCCGCCATTAATGAGAGTGATAACGCTGATATCATAGTCAATGCCCGGCTCCAGCCCTGTG-3′),制造了混合EDB-F1 20pmol、EDB-B1 20pmol、2.5mM dNTP混合液4μl、ExTaq DNA聚合酶1μl(10U)及10×PCR缓冲液5μl后添加蒸馏水使其总量为50μl的混合液。对该混合液进行PCR反应(在94℃条件下5分钟,30周期:在55℃条件下30秒,在72℃条件下1分钟以及在94℃条件下30秒)而制造EDB插入基因后,利用PCR纯化试剂盒进行纯化。为了将EDB插入基因与pET28b原核表达载体(Novagen)进行连接,用限制酶对EDB插入基因及pET28b原核表达载体进行处理。用BamHI(NEB,Ipswich)及NdeI(NEB,Ipswich)对约2μg的插入DNA分别进行4小时的反应后,利用PCR纯化试剂盒进行纯化。而且,使约2μg的pIGT2噬菌粒载体分别与BamHI和NdeI反应3小时后,放入CIAP反应一小时后,利用PCR纯化试剂盒进行纯化。对其添加载体与插入基因至载体与插入基因的摩尔比约为1∶3,利用T4DNA连接酶(Bioneer公司,大田,韩国),在18℃条件下连接10小时,并转化到XL-1感受态细胞后,涂抹在包含卡那霉素的琼脂培养基上。将生长在琼脂平板培养基的群落接种到5ml的LB培养基后,在37℃条件下,以200rpm的速度混合而培养一天后,利用质粒提取试剂盒(GeneAll公司,首尔,韩国)对质粒进行纯化,通过测序确认克隆是否成功。
【VEGF121基因制造及向表达载体的插入】
从细胞因子库(全州,韩国)中接收了部分人体VEGF(ID=G157)基因。通过合成引物VEGF_F1(5′-ATAGAATTCGCACCCATGGCAGAA-3′)及VEGF_B1(5′-ATTAAGCTTTCACCGCCTCGGCTTGTCACAATTTTCTTGTCTTGC-3′),制造了混合VEGF-F1 20pmol、VEGF-B1 20pmol、2.5mM dNTP混合液4μl、ExTaq DNA聚合酶1μl(10U)及10×PCR缓冲液5μl后添加蒸馏水使其总量为50μl的混合液。对该混合液进行PCR反应(在94℃条件下5分钟,30周期:在55℃条件下30秒,在72℃条件下1分钟以及在94℃条件下30秒)而制造VEGF插入基因后,利用PCR纯化试剂盒进行纯化。为了将VEGF插入基因与pET32a原核表达载体(Novagen)进行连接,用限制酶对VEGF插入基因及pET32a原核表达载体进行处理。用EcoRI(NEB,Ipswich)与HindIII(NEB,Ipswich)对约2μg的插入DNA分别进行4小时的反应后,利用PCR纯化试剂盒进行纯化。对其添加载体与插入基因至载体与插入基因的摩尔比约为1∶3,利用T4DNA连接酶(Bioneer公司,大田,韩国),在18℃条件下连接10小时,并转化到XL-1感受态细胞后,涂抹在包含氨苄青霉素的琼脂培养基上。将生长在琼脂平板培养基的群落接种到5ml的LB培养基后,在37℃条件下,以200rpm的速度混合而培养一天后,利用质粒提取试剂盒(GeneAll公司,首尔,韩国)对质粒进行纯化,通过测序确认克隆是否成功。
【VCAM1基因制造及向表达载体的插入】
从韩国生命工程研究院中接收了人体VCAM1基因。为了将VCAM1插入基因与pET32a原核表达载体进行连接,用限制酶对VCAM1插入基因及pET32a原核表达载体进行处理。对其添加载体与插入基因至载体与插入基因的摩尔比约为1∶3,利用T4DNA连接酶(Bioneer公司,大田,韩国),在18℃条件下连接10小时,并转化到XL-1感受态细胞后,涂抹在包含氨苄青霉素(ampicillin)的琼脂培养基上。将生长在琼脂平板培养基的群落接种在5ml的LB培养基后,在37℃条件下,以200rpm的速度混合而培养一天后,利用质粒提取试剂盒(GeneAll公司,首尔,韩国)对质粒进行纯化,通过测序确认克隆是否成功。
【纤维连接蛋白ED-B的表达及纯化】
对纤维连接蛋白ED-B进行克隆的pET28b原核表达载体转化到BL21细胞后,将其涂抹在包含卡那霉素的琼脂培养基上。将生长在琼脂平板培养基的群落接种到包含卡那霉素(25μg/ml)的5ml的LB培养基后,在37℃条件下,以200rpm的速度混合而培养一天后,转移到包含卡那霉素(25μg/ml)的50ml的LB培养基中培养3小时。将培养的E.coli接种到包含卡那霉素(25μg/ml)的2l的LB而培养至OD=0.6-0.8。之后放入1mM异丙基-β-D-硫代吡喃半乳糖苷(IPTG),在37℃条件下,以200rpm的速度混合而培养8小时。以4,000×g进行20分钟的离心分离,由此去除除了沉淀的细胞以外的所有上清液,并用裂解缓冲液(50mM的磷酸钠(pH 8.0)、300mM的NaCl及5mM的咪唑)进行悬浮。在-80℃条件下保管一天后,利用超声波破碎仪溶解E.coli后,以15,000×g进行一小时的离心分离,由此使上清液与Ni-NTA亲和树脂(Elpisbio公司,大田,韩国)结合。用裂解缓冲液清洗树脂后,利用洗脱缓冲液(50mM的磷酸钠(pH8.0)、300mM的NaCl及300mM的咪唑)洗脱而获得N-末端His-tagED-B蛋白质。利用Superdex75色谱柱(GE Healthcare,United Kingdom)及PBS(pH 7.4)缓冲液通过凝胶过滤法(gel filtration)获得高纯度ED-B蛋白质。为了进行生物淘选,将生物素与ED-B蛋白质连接。在常温下,在存在0.1M磷酸钠的条件下,使6mg的生物素标记试剂(Sulfo-NHS-SS-Biotin)(PIERCE,Illinois,USA)及1.5mg的ED-B蛋白质反应2小时,为了去除未反应的生物素标记试剂,利用Superdex75色谱柱(GE Healthcare,United Kingdom)及PBS(pH 7.4)缓冲液通过凝胶过滤法(gel filtration)对生物素-EDB蛋白质进行纯化。
【VEGF121与VCAM1-Trx的表达及纯化】
将对VEGF121与VCAM1进行克隆的pET32a原核表达载体分别转化到AD494细胞之后涂抹在包含氨苄青霉素的琼脂培养基上。将在琼脂平板培养基生长的群落接种到包含氨苄青霉素(25μg/ml)的5ml的LB培养基后,在37℃条件下,以200rpm的速度混合而培养一天后,转移到包含氨苄青霉素(25μg/ml)的50ml的LB培养基中培养3小时。将培养的E.coli接种到包含氨苄青霉素(25μg/ml)的2l的LB而培养至OD=0.6-0.8。之后放入1mM异丙基-β-D-硫代吡喃半乳糖苷(IPTG),在37℃条件下,以200rpm的速度混合而培养8小时。以4,000×g进行20分钟的离心分离,由此去除除了沉淀的细胞以外的所有上清液,并用裂解缓冲液(50mM的磷酸钠(pH 8.0)、300mM的NaCl及5mM的咪唑)进行悬浮。在-80℃条件下保管一天后,利用超声波破碎仪溶解E.coli后,以15,000×g进行一小时的离心分离,由此将上清液与Ni-NTA亲和树脂(Elpisbio公司,大田,韩国)结合。用裂解缓冲液清洗树脂后,利用洗脱缓冲液(50mM的磷酸钠(pH 8.0)、300mM的NaCl及300mM的咪唑)洗脱而获得Trx-VEGF121蛋白质。利用Superdex75色谱柱(GE Healthcare,英国)及PBS(pH 7.4)缓冲液,并通过凝胶过滤法(gel filtration)获得高纯度VEGF-Trx及VCAM1-Trx蛋白质。为了获得纯粹的VEGF,用凝血酶切断VEGF与Trx之间而获得了VEGF121。
另一方面,HAS是从Genetex公司(Irvine)购入使用。nAchR(Nicotinic acetylcholine receptor)的片段肽biotin-SGEWVIKEARGWKHWVFYSCCPTTPYLDITYH(32mer)是在anygen(韩国,光州)合成的。Human MyD88从Santa Cruz Biotechnology(sc-4540WB)(California)购得。
【实施例3:生物淘选方法】
【Biotin纤维连接蛋白(Fibronectin)ED-B蛋白质和Biotin-nAchR肽的生物淘选方法】
将2ml的链亲和素(10μg/ml)以每孔50μl的量放入到96孔ELISA板(Corning)的40个孔,在4℃条件下放置一晚,次日仅针对其中的20个孔用0.1%的PBST(tween-20)清洗3次之后,分别放入生物素ED-B和生物素nAchR(10μg/ml)并在常温下放置1小时。然后,用0.1%PBST清洗3次上述40个孔,通过使用用PBS稀释的2%的BSA在常温下封阻2小时后,倒掉全部溶液并用0.1%PBST清洗3次。对其混合包含双齿肽结合物重组噬菌体的溶液800μl及10%BSA200μl,为了去除结合于链亲和素及BSA的各噬菌体而放入到涂敷有链亲和素及BAS的20个孔,在27℃条件下放置1小时。回收上清液并转移至结合有ED-B和nAchR的20个孔,在27℃条件下放置45分钟。去除20个孔的全部溶液,并使用0.5%PBST清洗15次后,将1ml的0.2M甘氨酸/HCl(pH 2.2)以每孔50μl的量放入到各孔,由此洗脱噬菌体20分钟,将1ml溶液收集到管中并放入150μl的2MTris-base(pH 9.0)而对溶液进行中和。为了测定每次进行生物淘选时的输入的噬菌体及洗脱下来的噬菌体(Eluted phage)的数量,混合至OD=0.7的XL-1 BLUE细胞并涂抹至包含氨苄青霉素的琼脂培养基。为了反复进行淘选,与10ml的E.coli XL1-BLUE细胞混合而在37℃条件下,以200rpm的速度混合而培养1小时左右。混合氨苄青霉素(50μg/ml)及20mM葡萄糖后,添加2×1010pfu的Ex辅助噬菌体并在37℃条件下,以200rpm的速度混合而培养1小时。对培养液以1,000×g进行离心分离10分钟后,去除上清液并将沉淀的细胞用包含氨苄青霉素(50μg/ml)及卡那霉素(25μg/ml)的40ml的LB液体培养基重新进行悬浮,在30℃条件下,以200rpm的速度混合而培养一天。在4,000×g、20分钟及4℃条件下,对培养液进行离心分离。上清液中添加8ml的5x PEG/NaCl[20%PEG(w/v)及15%NaCl(w/v)]后,在4℃条件下放置1小时。离心分离后彻底去除PEG溶液,用1ml的PBS溶液溶解噬菌体肽颗粒后将其用于第2轮生物淘选。各个淘选步骤均使用上述方法,只有清洗过程按不同步骤分别增加25次及35次(0.5%PBST)。
【VEGF、VCAM1-Trx、Human serum albumin(HAS)以及MyD88的生物淘选方法】
将VEGF、VCAM1-trx、HAS以及MyD 88(5μg/ml)以每孔50μl的量放入到96孔ELISA板(Corning)的10个孔,并在4℃条件下放置一晚,次日使用2%BSA在常温下封阻2小时后,倒掉全部溶液并用0.1%PBST清洗3次。对其混合包含双齿肽结合物重组噬菌体的溶液800μl及10%BSA 200μl,并转移至结合有VEGF、VCAM1-Trx以及HAS的10个孔,并在常温下放置1小时。去除10个孔的全部溶液,使用0.1%PBST清洗10次后,将1ml的0.2M甘氨酸/HCl(pH2.2))以每孔50μl的量放入到各孔内,洗脱噬菌体20分钟,将1ml溶液收集到管中并放入150μl的2M Tris-base(pH 9.0)对溶液进行中和。为了测定每进
双齿肽结合物专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。









动态评分
0.0