

IPC分类号 : H04L12/00I,H04L29/06I,H04L9/10I,G06F9/00I,G06F21/00I


专利摘要
本发明涉及一种基于模糊神经网络的攻击知识的自动更新方法,属于网络信息安全技术领域。适用于基于模糊推理的误用入侵检测系统的攻击知识的自动更新。本发明将神经网络的学习机制引入到模糊推理中,使基于模糊推理的入侵检测系统具有学习能力,从而使攻击知识隶属函数在建立之后能够随环境变化自动进行更新,解决了目前手工调整存在的工作量大,不够准确等问题。
权利要求
1.一种基于模糊神经网络的攻击知识的自动更新方法,其特征在于:具体实现步骤如下:
步骤一、建立模糊攻击知识的神经网络模型
针对基于模糊产生式规则的攻击知识,采用六层前向网络建立对应的模糊神经网络模型,建立步骤如下:
第(1)步:建立神经网络模型的第一层,称之为输入层;
该第一层中每个神经元代表产生式规则前提条件中的一个模糊变量,定义为Xi,神经元个数等于前提条件中出现的模糊变量个数,该第一层神经元直接把输入变量Xi的值传递给下层的神经元,即:
F(Xi)=Xi (3)
其中,F为作用函数;
第(2)步:建立神经网络模型的第二层,称之为前提隶属函数层;
首先,该第二层神经元用于模拟产生式规则前提中出现的所有模糊集合的隶属函数,分为2种情况:①对于单调增加或者减少的隶属函数,用一个神经元模拟;②对于三角形或梯形的隶属函数,用两个神经元模拟,通过两个神经元输出值的代数运算来实现;
其次,第一层与第二层神经元按照如下规则建立连接:在产生式规则中,某变量与某模糊集合存在取值的关系,则在第一层中代表该变量的神经元与第二层中代表该模糊集合隶属函数的神经元之间建立连接;
第(3)步:建立神经网络模型的第三层,称之为前提层;
首先,该第三层神经元对应产生式规则命题中出现的所有模糊集合,并且神经元是线性的,即:
F(Si)=Si (4)
Si可通过公式5计算得到:
Si=∑Wijaj (5)
其中,Wij的取值为1或者-1,即对于单调增加或者减少的隶属函数,用一个神经元模拟,其对应Wij的值为1;对于三角形或梯形的隶属函数,用两个神经元模拟,其对应的Wij的取值为一个为1,另一个为-1;
其次,第二层与第三层神经元按照如下规则建立连接:第二层中代表隶属函数的神经元与第三层中代表与此隶属函数对应的模糊集合的神经元建立连接;
第(4)步:建立神经网络模型的第四层,称之为规则层;
首先,该第四层中每个神经元对应一条产生式规则,神经元是线性的,用于完成模糊“与”运算,即:
F(Si)=Si (6)
Si可通过公式7计算得到:
Si=min(a1,a2,…,an) (7)
其中,a1,a2,……,an为该神经元的所有输入;
其次,第三层与第四层神经元按照如下规则建立连接:在产生式规则中,如果某模糊集合出现在某规则的前提条件中,则第三层中代表该模糊集合的神经元与第四层中代表产生式规则的神经元建立相连;
第(5)步:建立神经网络模型的第五层,称之为结论层;
首先,该第五层每个神经元对应产生式规则结论中的一个模糊集合,该第五层神经元有两个功能:①自右向左传输,完成输出变量取值模糊集合隶属函数的模拟,模拟方法与第二层相同;②自左向右传输,完成模糊规则前提与结论的合成,再对合成后的模糊变量进行模糊“或”运算,即:
Si可通过公式9计算得到:
Si=min(aj,f(ak)) (9)
其中,aj为自左向右输入,ak为自右向左输入,f(·)为结论中输出变量取值模糊集合的隶属函数;
其次,第四层与第五层神经元按照如下规则建立连接:在产生式规则中,如果某模糊集合出现在某规则的结论中,则第五层中代表该模糊集合的神经元与第四层中代表产生式规则的神经元建立连接;
第(6)步:建立神经网络模型的第六层,称之为解模糊层,即输出层;
首先,输出层的神经元对应产生式规则结论中出现的模糊变量,输出层有两个功能:
①将训练结果反馈到网络中,即:
F(S)=S,S=y (10)
其中,y为系统的输出;
②将输出变量进行解模糊化处理,采用重心法解模糊:令hi和di分别表示隶属函数的中心点和宽度,中心点即平均值、宽度即方差,ai为该神经元的所有输入,则:
S可通过公式12计算得到:
S=∑Wiaj=∑(hidi)ai (12)
其中,S=∑Wiaj=∑(hidi)ai,该层的连接权值为hidi;
通过上述步骤,可完成模糊攻击知识的神经网络模型的建立;
步骤二、采集训练数据
定义产生式攻击规则前提中的变量为X1,X2,…,Xn,结论中的攻击类型为y,采集训练数据的具体操作步骤为:
第1步:在实际网络中模拟攻击y;
第2步:对攻击y产生的数据进行捕获并处理,提取变量X1,X2,…,Xn对应的具体数值,用x1,x2,…,xn表示;
第3步:将数据x1,x2,…,xn与攻击y组成一个向量(x1,x2,…,xn,y),该向量即为训练数据;
重复上述步骤,直到采集到满足人为设定的数量的训练数据为止;
步骤三、用训练数据训练神经网络模型,完成对隶属函数的参数的调整
利用步骤二得到的训练数据对步骤一中建立的神经网络模型进行训练,完成对隶属函数的参数的调整;训练分两步:正向传播和反向传播,具体训练算法如下:
第1步:将训练数据从输入层经隐含层传向输出层,此过程称为正向传播;
第2步:若输出层得到期望的输出,则结束;否则,执行第3步;
第3步:将误差信号按原连接路径反向计算,采用梯度下降法调整各层神经元的连接权值和阈值,此过程称为反向传播;
第4步:当第3步的权值和阈值等参数调整后,返回到第1步;
通过上述步骤,完成对隶属函数的权值和阈值等参数的自动修正。
说明书
技术领域
本发明涉及一种基于模糊神经网络的攻击知识的自动更新方法,属于网络信息安全技术领域。适用于基于模糊推理的误用入侵检测系统的攻击知识的自动更新。
背景技术
网络入侵检测系统从网络中收集可能含有攻击痕迹的日志数据,通过对数据进行分析来发现可能存在的攻击行为。从检测方法的角度可将入侵检测系统分为两类:异常检测和误用检测。误用检测系统需要事先建立攻击知识模板,再从日志数据中提炼出攻击证据,通过将攻击证据与攻击知识模板进行匹配,如果相符则认为是攻击;否则,不认为是攻击。
基于模糊推理的误用入侵检测系统将模糊推理技术引入到误用检测系统,其攻击知识模板是模糊的,攻击证据使用模糊证据,匹配过程采用模糊推理技术,推理结果给出的是攻击发生的可能性。
基于模糊推理的入侵检测系统常采用模糊产生式规则表示攻击知识,形式如下:
IF P THEN Q
其中,P是攻击规则的模糊前提,Q是一组模糊结论或操作。
基于模糊推理的误用入侵检测系统的攻击知识模板,在建立之后需要根据实际使用的环境的变化对其隶属函数进行调整,即:如果环境发生变化,对攻击知识的调整即是对隶属函数做相应调整,以提高误用检测系统的检测率。目前,针对隶属函数的调整常采用手工方法。手工调整存在工作量大,不够准确等问题。
本发明使用到的另外一项重要的已有技术是前向神经网络的相关知识。
前向神经网络由输入层、隐含层和输出层组成,隐含层可以有多层,如图1所示。节点分为两类,输入节点(输入层的所有节点)和计算单元(隐含层和输出层的节点)。输入节点对信号不进行运算,仅将信号传递给隐含层。而计算单元对信号进行运算。每个计算单元可有任意个输入,但各个输出的结果只有一个,大小相同,且输出的结果可作为其他任意多个节点的输入。整个网络某一层的输入只与它前一层的输出相联。当信号输入时,首先传到隐含层节点,经过计算单元的作用函数后,再把节点的输出信号传播到输出层节点,经过处理后给出输出结果。计算单元的作用函数通常选用公式1所示的S型函数。
其中,c为S形函数的斜率系数;θ为阈值。
Si可通过公式2计算得到:
Si=∑Wijaj (2)
其中,Wij表示前一层第j个神经元和该层第i个神经元间的连接权值,aj是前层中第j个神经元的输出。
前向神经网络的反传学习过程原理图如图2所示。学习过程由正向传播和反向传播组成。在正向传播过程中,输入信号从输入层经隐含层单元逐层处理,并传向输出层,每一层神经元的状态只影响下一层神经元的状态。如果在输出层不能得到期望的输出,则转入反向传播,将输出信号的误差沿原来的连接通路返回。通过修正各层神经元的权值,使得误差信号最小。
发明内容
本发明的目的在于提出一种基于模糊神经网络的攻击知识的自动更新方法。由于模糊推理系统和神经网络具有相似的非线性映射能力,本发明将神经网络的学习机制引入到模糊推理中,使基于模糊推理的入侵检测系统具有学习能力,从而使攻击知识隶属函数在建立之后能够随环境变化自动进行更新。
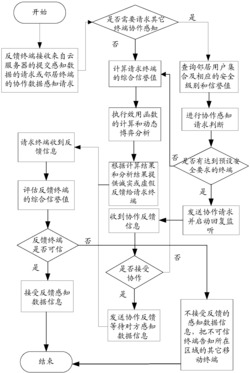
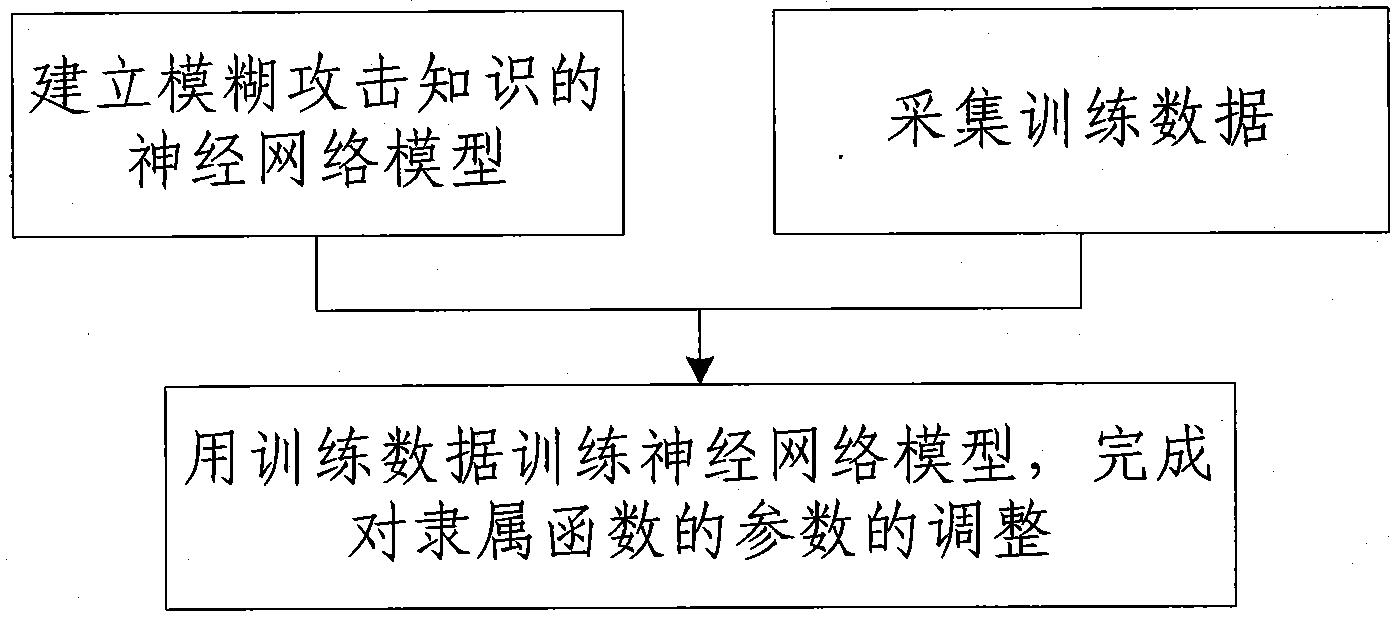
本发明的一种基于模糊神经网络的攻击知识的隶属函数自动更新方法整体框架设计流程如图3所示。其具体实现步骤如下:
步骤一、建立模糊攻击知识的神经网络模型
针对基于模糊产生式规则的攻击知识,采用六层前向网络建立对应的模糊神经网络模型,建立步骤如下:
第(1)步:建立神经网络模型的第一层,称之为输入层。
该层中每个神经元代表产生式规则前提条件中的一个模糊变量,定义为Xi,神经元个数等于前提条件中出现的模糊变量个数。该层神经元直接把输入变量Xi的值传递给下层的神经元,即:
F(Xi)=Xi (3)
其中,F为作用函数。
第(2)步:建立神经网络模型的第二层,称之为前提隶属函数层。
首先,该层神经元用于模拟产生式规则前提中出现的所有模糊集合的隶属函数。分为2种情况:①对于单调增加或者减少的隶属函数,用一个神经元模拟;②对于三角形或梯形的隶属函数,用两个神经元模拟,通过两个神经元输出值的代数运算来实现。前提隶属函数层神经元的作用函数如公式1所示。
其次,第一层与第二层神经元按照如下规则建立连接:在产生式规则中,某变量与某模糊集合存在取值的关系,则在第一层中代表该变量的神经元与第二层中代表该模糊集合隶属函数的神经元之间建立连接。
第(3)步:建立神经网络模型的第三层,称之为前提层。
首先,该层神经元对应产生式规则命题中出现的所有模糊集合,并且神经元是线性的,即:
F(Si)=Si (4)
Si可通过公式5计算得到:
Si=∑Wijaj(5)
其中,Wij的取值为1或者-1,即对于单调增加或者减少的隶属函数,用一个神经元模拟,其对应Wij的值为1;对于三角形或梯形的隶属函数,用两个神经元模拟,其对应的Wij的取值为一个为1,另一个为-1。
其次,第二层与第三层神经元按照如下规则建立连接:第二层中代表隶属函数的神经元与第三层中代表与此隶属函数对应的模糊集合的神经元建立连接。
第(4)步:建立神经网络模型的第四层,称之为规则层。
首先,该层中每个神经元对应一条产生式规则,神经元是线性的,用于完成模糊“与”运算,即:
F(Si)=Si (6)
Si可通过公式7计算得到:
Si=min(a1,a2,…,an) (7)
其中,a1,a2,……,an为该神经元的所有输入。
其次,第三层与第四层神经元按照如下规则建立连接:在产生式规则中,如果某模糊集合出现在某规则的前提条件中,则第三层中代表该模糊集合的神经元与第四层中代表产生式规则的神经元建立相连。
第(5)步:建立神经网络模型的第五层,称之为结论层。
首先,该层每个神经元对应产生式规则结论中的一个模糊集合。该层神经元有两个功能:①自右向左传输,完成输出变量取值模糊集合隶属函数的模拟,模拟方法与第二层相同;②自左向右传输,完成模糊规则前提与结论的合成,再对合成后的模糊变量进行模糊“或”运算,即:
Si可通过公式9计算得到:
Si=min(aj,f(ak)) (9)
其中,aj为自左向右输入,ak为自右向左输入,f(·)为结论中输出变量取值模糊集合的隶属函数。
其次,第四层与第五层神经元按照如下规则建立连接:在产生式规则中,如果某模糊集合出现在某规则的结论中,则第五层中代表该模糊集合的神经元与第四层中代表产生式规则的神经元建立连接。
第(6)步:建立神经网络模型的第六层,称之为解模糊层,即输出层。
首先,输出层的神经元对应产生式规则结论中出现的模糊变量。输出层有两个功能:
①将训练结果反馈到网络中,即:
F(S)=S,S=y (10)
其中,y为系统的输出。
②将输出变量进行解模糊化处理。采用重心法解模糊:令hi和di分别表示隶属函数的中心点(平均值)和宽度(方差),则:
S可通过公式12计算得到:
S=∑Wiaj=∑(hidi)ai (12)
其中,S=∑Wiaj=∑(hidi)ai。该层的连接权值为hidi。
通过上述步骤,可完成模糊攻击知识的神经网络模型的建立。
步骤二、采集训练数据
定义产生式攻击规则前提中的变量为X1,X2,…,Xn,结论中的攻击类型为y,采集训练数据的具体操作步骤为:
第1步:在实际网络中模拟攻击y;
第2步:对攻击y产生的数据进行捕获并处理,提取变量X1,X2,…,Xn对应的具体数值,用x1,x2,…,xn表示;
第3步:将数据x1,x2,…,xn与攻击y组成一个向量(x1,x2,…,xn,y),该向量即为训练数据。
重复上述步骤,直到采集到满足人为设定的数量的训练数据为止。
步骤三、用训练数据训练神经网络模型,完成对隶属函数的参数的调整
利用步骤二得到的训练数据对步骤一中建立的神经网络模型进行训练,完成对隶属函数的参数的调整。训练分两步:正向传播和反向传播。具体训练算法如下:
第1步:将训练数据从输入层经隐含层传向输出层,此过程称为正向传播;
第2步:若输出层得到期望的输出,则结束;否则,执行第3步;
第3步:将误差信号按原连接路径反向计算,采用梯度下降法调整各层神经元的连接权值和阈值。此过程称为反向传播。具体计算方法如下:
①定义误差函数为:
其中y(t)为网络期望输出, (t)为实际输出。
②计算所有隐藏节点的 其具体步骤如下:
定义w为节点中可调节的参数(权值和阈值的调整方法相同,此处w表示权值或阈值),则训练规则为:
其中,η为学习速率;S为节点输入;F为节点输出。
根据公式13、14、15、16,下面从输出节点开始分层给出各层的 计算方法,以及各层参数的调整公式。
a.第六层:根据公式15和16以及公式12,隶属函数的中心点和宽度的修正量分别为:
因此:
向前传递的误差量为:
公式中字母上标括号中的数值,指所在的网络层数。
b.第五层:在从左向右传递的模式中,没有参数需要调整,仅需要计算和传递误差信号。误差量为:
根据公式10:
根据公式21:
因此误差信号:
c.第四层:与第五层相同,仅对误差信号进行计算。根据公式8和公式9:
因此,误差量 如果有多个输出,则误差量为:
规则节点的误差为后件的误差之和。
d.第三层:仅计算要传播的误差量。
如有多个输出,则误差量为:
e.第二层:前件隶属函数的修正。误差量为:
其中,Si是该层第i个神经元输入。
权值的修正量:
阈值的修正量:
第4步:当第3步的权值和阈值等参数调整后,返回到第1步。
通过上述步骤,完成对隶属函数的权值和阈值等参数的自动修正。
有益效果
本发明将神经网络的学习机制引入到模糊推理中,使基于模糊推理的入侵检测系统具有学习能力,从而使攻击知识隶属函数在建立之后能够随环境变化自动进行更新,解决了目前手工调整存在工作量大,不够准确等问题。
附图说明
图1为已有技术的前向神经网络结构示意图;
图2为已有技术的前向神经网络的反传学习过程原理图;
图3为本发明的一种基于模糊神经网络攻击知识隶属函数的自动更新方法整体框架设计流程图;
图4为本发明具体实施方式中ΔSEQ的隶属函数的图形表示;
图5为本发明具体实施方式中ΔT的隶属函数的图形表示;
图6为本发明具体实施方式中攻击发生可能性R的隶属函数的图形表示;
图7为本发明具体实施方式中模糊攻击知识的模糊神经网络模型图。
具体实施方式
下面结合附图和实施例对本发明内容做详细描述。
以一组针对SYN洪泛攻击(TCP SYN Flooding)检测的规则为例,说明采用神经网络对其隶属函数进行调整的过程。
TCP SYN Flooding攻击原理如下:
主机A向主机B发送一个带有SYN和FIN标志位置位的TCP包;主机B首先处理SYN标志,生成一个带有相应ACK标志位置位的包,并使状态转移到SYN-RCVD,然后处理FIN标志,使状态转移到CLOSE-WAIT,并向A回送ACK包;此时,主机A并不响应主机B回送的ACK包。主机B将固定在CLOSE-WAIT状态等待A的响应,直到定时器超时将状态重置为CLOSED状态。主机B维持这样的CLOSE-WAIT状态需要占有一定的内存资源,因此维持这样的CLOSE-WAIT状态的数量有限。入侵者向主机B发送大量上述具有SYN和FIN标志位置位的TCP包,造成主机B资源耗尽而不能响应正常的连接请求,长时间反复发送,造成某个网络端口长时间阻塞,从而产生拒绝服务攻击。
模糊检测规则如下:
Rule1:IFΔSEQ=S ANDΔT=S THEN R=H;
Rule2:IFΔSEQ=S ANDΔT=M THEN R=M;
Rule3:IFΔSEQ=S ANDΔT=L THEN R=M;
Rule4:IFΔSEQ=M ANDΔT=S THEN R=H;
Rule5:IFΔSEQ=M ANDΔT=M THEN R=L;
Rule6:IFΔSEQ=M ANDΔT=L THEN R=M;
Rule7:IFΔSEQ=L ANDΔT=S THEN R=M;
Rule8:IFΔSEQ=L ANDΔT=M THEN R=M;
Rule9:IFΔSEQ=L ANDΔT=L THEN R=L。
其中,ΔSEQ表示序列号的间隔值,ΔT表示两个连续TCP分片的时间间隔。ΔSEQ、ΔT为模糊变量,R表示TCP SYN Flooding攻击发生的可能性。对ΔSEQ的输入划分成3个模糊集合,分别为S(Small),M(Medium),L(Large),其隶属函数如图4,表达式如下。
S(Small):
M(Medium):
L(Large):
对ΔT的输入也划分成3个模糊集合,分别为S(Short),M(Medium),L(Long),其隶属函数如图5所示,表达式如下。
S(Short):
M(Medium):
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。






动态评分
0.0