









专利摘要
本发明公开了一种基于共同语义空间的个性化音乐生成方法,包括以下步骤:S1、将文字映射到共同语义空间表示;S2、将共同语义空间表示转化为乐曲;S3、将文字蕴含的风格和意境隐含到语义空间表示中,并体现在生成的乐曲中。还公开了实现所述方法的装置。本发明的有益效果是:本发明生成乐曲时可以考虑全部的文字描述以及已经生成的音符;生成的乐曲会融入文字描述体现的风格和意境;可以针对某种类型的乐曲进行强化;良好的数据可移植性和可扩展性。
权利要求
1.一种基于共同语义空间的个性化音乐生成方法,其特征在于:包括以下步骤:
S1、将文字映射到共同语义空间表示;
S2、将共同语义空间表示转化为乐曲;
S3、将文字蕴含的风格和意境隐含到语义空间表示中,并体现在生成的乐曲中;
所述的共同语义空间是指将文字和音乐映射到在同一个语义空间中;
具体包括以下步骤:
A、输入输出格式如下:
文字对应的输入格式:
音符对应的输出格式:
其中:
K
在encoder阶段使用bidirectional recurrent neural network构建,下面是生成正向隐层
其中:
反向隐层
拼接正向和反向隐层向量获得
C、对于decoder:
在Decoder阶段,生成隐层状态设为s
其中:
生成下一个音符条件概率的公式如下:
y
D、代价函数:
使用交叉熵代价函数:
2.根据权利要求1所述的一种基于共同语义空间的个性化音乐生成方法,其特征在于:所述的步骤S1和S2均通过基于RNN的编码器来实现。
3.实现如权利要求l或2所述的一种基于共同语义空间的个性化音乐生成方法的装置,其特征在于,包括将文字映射到共同语义空间表示的影射模块和用于将共同语义空间表示转化为乐曲的转化模块。
说明书
技术领域
本发明涉及一种基于共同语义空间的个性化音乐生成方法及装置。
背景技术
音乐生成是让计算机自动创作音乐的技术。音乐创作一直被认为是一种高难度,依赖人类突发灵感的高级思维活动。另一方面,音乐创作又需要遵循严格的规律,如节拍性、强弱性等。这意味着创造音乐是一项既要循规蹈矩,又要寻求新意的艰苦劳动,仅有对音高、节拍等具有敏锐感觉,且思维活跃度极高的少数人能够胜任。幸运的是,这种在严格框架下进行有限创新的工作,计算机具有天然优势,它可以充分保证生成作品的合规性,同时在合规下探索各种可能的创新。让计算机自动生成音乐,可极大减少人类进行音乐创作的工作量,且有望产生挣脱传统思路束缚新颖音乐。即便用机器生成的音乐还不能与人类的音乐家相比,但机器作品可以为人类提供候选或初级作品,使作曲家创作更加容易;同时,计算机生成的音乐还可以为作曲家提供灵感和刺激,激发他们不断创造新的音乐,防止因长期创作带来的风格惰性和思维困顿,帮助作曲家永褒创作青春。因此,自动音乐生成具有非常广阔的应用前景。
音乐生成一般可以有以下两种方式:
1、经典的概率模型
该方法用语言模型或者HMM模型训练字符化的乐谱,然后生成一段乐谱,能取得比较不错的效果。
2、神经网络(NN)模型
该方法学习字符化的乐谱利用神经网络,相当于学习一个序列,然后用模型生成一个序列,这种方法一个时刻只能生成一个音符,不过可以获得一些令人满意的音乐片段。
目前的音乐生成方法无法细致指定生成音乐的风格。要生成不同风格的音乐,或者人为挑选不同风格的训练数据进行与风格相关(style-dependent)的模型训练,或者引入一个表示风格的指示变量,表示想要生成的风格方式。虽然这些是可行的,但这些方法无法对风格进行细致指定。比如,同样是田园风格,反应农耕生活和反应狩猎生活的音乐可能差距较大。再如,如果我们想反应复杂风格,既有田园风格,也有魔幻风格,则传统的方法无法实现。除了风格,音乐还包括意境、情景、叙事等复杂属性。这些复杂属性到相交叉组合,意味着对音乐的描述极为复杂,更别提依这些描述来生成音乐了。
本发明关注音乐生成任务,提出一种新的方法,可通过文字描述来指定生成音乐的风格和属性。例如,通过输入“牛和羊在青青的草地上吃草,旁边有小溪流过”来指定生成音乐所表述的内容,音乐生成器即可生成与这一田园风格相适应的音乐。
发明内容
本发明的目的在于克服现有技术的缺点,提供一种基于共同语义空间的个性化音乐生成方法及装置。该方法首先将已知的文字-乐曲对映射到共同的语义空间中,并同时将文字所表述的风格、意境等也体现在该语义空间表示中,然后学习在这种特定的风格、意境下的语义空间表示到乐曲的转换关系,这样,学习到的映射和转换关系就可以根据新的文字创作能体现出风格和意境的乐曲。对于给定的一段新文字,创作过程为先将其映射到该共同语义空间,然后再用学习到的转换方法来生产贴合该文字内容以及风格的乐曲。
本发明的目的通过以下技术方案来实现:一种基于共同语义空间的个性化音乐生成方法,包括以下步骤:
S1、将文字映射到共同语义空间表示(编码过程);
S2、将共同语义空间表示转化为乐曲(解码过程);
S3、将文字蕴含的风格和意境隐含到语义空间表示中,并体现在生成的乐曲中。由于在编码过程中,会考虑全部的文字描述,这就使得语义空间表示可以学习文字之间的相互关系以及这些文字共同所体现的风格和意境,而在解码的时候,除了文字描述,还会考虑该乐曲的已生成部分,使得整个乐曲除了能够与文字描述贴合之外,还能保证自身内容的完整性以及风格的整齐划一感。
优选的,所述的步骤S1和S2均可通过基于RNN的编码器来实现,但不限于该方法。
共同语义空间是指将文字和音乐映射到在同一个语义空间中,使得对于文字和音乐两个不同的体系,该语义空间不仅能够分别勾勒出单个体系内语义级别上纵横交错的隐含关系,还能够体现两个体系在语义级别上的联动性和一致性。对于本发明文字到音乐的生成,需要分别文字和音乐和共同语义空间的对应关系,只是操作的方向不同。对于文字,该方法主要通过一个编码器来学习如何将其映射到语义空间中,也就是学习其语义空间表示,而对于音乐,该方法主要学习如何从其文字的语义空间表示来转化成音乐。
基于RNN的编码-解码结构
本发明主要描述了用基于RNN的编码-解码结构来进行文字到音乐的生成,但实际并不仅限于该方法,其他一些序列到序列的模型也适用。编码时,从左到右依次将文字描述中的文字映射到共同语义空间中,在映射每一个文字的时候,不仅考虑之前的文字,还考虑之前文字的语义表示。解码时也是从左到右挨个生成乐符,首先根据文字描述的语义表示以及已生成部分乐曲的乐符序列及其语义表示来得到当前生成乐符的语义表示,再将该语义表示转化成相应的乐符。
下面以LSTM机制为例来描述基于RNN模型的编码阶段的文字到语义以及解码阶段的语义到乐符的转换过程。
1、输入输出格式如下:
文字对应的输入格式:
音符对应的输出格式:
其中:
Kx和Ky分别是文字和音符的字符个数,Tx和Ty分别是一段文字和对应音符的长度。
2、对于encoder:
首先,该模型在encoder阶段使用bidirectional recurrent neural network(lstm)
构建,下面是生成正向隐层 的步骤:
其中:
是文字字符对应的词向量矩阵。 和 是权重矩阵, 是偏置向量,m是词向量的维度,n是隐层数。
反向隐层 可以通过相似的计算获得。
我们可以拼接正向和反向隐层向量获得 如下所示:
3、对于decoder:
在Decoder阶段,生成隐层状态设为st的步骤,如下:
其中:
是音符字符对应的词向量矩阵。Wo,WC,Wi,Wf∈Rn×m,Uo,UC,Ut,Uf∈Rn×n和Co,CC,Ci,Cf∈Rn×2n是权重矩阵, 是偏置向量,m是词向量的维度,n是隐层数。
生成下一个音符条件概率的公式如下:
yt=argmaxy p(y|st,c,yt-1)(16)
4、代价函数:
使用交叉熵代价函数:
训练与生成
训练语料的格式为一首歌的每一个字对对应一个或者多个音符,这样,训练和生成过程就相当于一个翻译过程。在训练过程中,把整首歌作为输入在编码器阶段生成一个表征向量再由表征向量和上一个音符在解码器阶段生成对应的音乐(即一串音符),再根据生成的音符和本来正确的音符,设计一个损失函数,在训练阶段不断更新参数。在生成过程中,我们可以输入若干句话或者关键词,生成一段符合文字风格或者意境的音乐。
实现所述的一种基于共同语义空间的个性化音乐生成方法的装置,包括将文字映射到共同语义空间表示的影射模块和用于将共同语义空间表示转化为乐曲的转化模块。
本发明具有以下优点:
本发明生成乐曲时可以考虑全部的文字描述以及已经生成的音符;生成的乐曲会融入文字描述体现的风格和意境;可以针对某种类型的乐曲进行强化;良好的数据可移植性和可扩展性。
附图说明
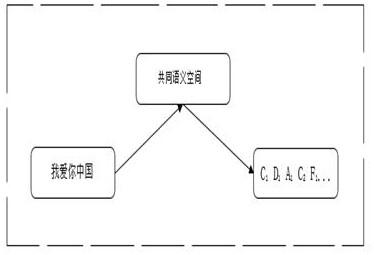
图1为本发明的文字和音乐在共同语义空间的转换过程示意图。
图2为本发明的基于RNN的编码-解码模型示意图。
图3为本发明的训练示意图。
图4为本发明的生成示意图。
具体实施方式
下面结合附图对本发明做进一步的描述:
一种基于共同语义空间的个性化音乐生成方法,包括以下步骤:
S1、将文字映射到共同语义空间表示(编码过程);
S2、将共同语义空间表示转化为乐曲(解码过程);
S3、将文字蕴含的风格和意境隐含到语义空间表示中,并体现在生成的乐曲中。由于在编码过程中,会考虑全部的文字描述,这就使得语义空间表示可以学习文字之间的相互关系以及这些文字共同所体现的风格和意境,而在解码的时候,除了文字描述,还会考虑该乐曲的已生成部分,使得整个乐曲除了能够与文字描述贴合之外,还能保证自身内容的完整性以及风格的整齐划一感。
优选的,所述的步骤S1和S2均可通过基于RNN的编码器来实现,但不限于该方法。
共同语义空间是指将文字和音乐映射到在同一个语义空间中,使得对于文字和音乐两个不同的体系,该语义空间不仅能够分别勾勒出单个体系内语义级别上纵横交错的隐含关系,还能够体现两个体系在语义级别上的联动性和一致性。对于本发明文字到音乐的生成,需要分别文字和音乐和共同语义空间的对应关系,只是操作的方向不同。对于文字,该方法主要通过一个编码器来学习如何将其映射到语义空间中,也就是学习其语义空间表示,而对于音乐,该方法主要学习如何从其文字的语义空间表示来转化成音乐。
比如“我爱你中国”这一句歌词对应的音符为“C1 D1 A1 C2 F1 E1 D1 F1 C1”,如图1所示,虚线框所示就是歌词和音符的共同语义空间。
基于RNN的编码-解码结构
本发明主要描述了用基于RNN的编码-解码结构来进行文字到音乐的生成,但实际并不仅限于该方法,其他一些序列到序列的模型也适用。编码时,从左到右依次将文字描述中的文字映射到共同语义空间中,在映射每一个文字的时候,不仅考虑之前的文字,还考虑之前文字的语义表示。解码时也是从左到右挨个生成乐符,首先根据文字描述的语义表示以及已生成部分乐曲的乐符序列及其语义表示来得到当前生成乐符的语义表示,再将该语义表示转化成相应的乐符。比如“我爱你中国”这一句歌词对应的音符为“C1 D1 A1 C2 F1 E1 D1 F1 C1”,其对应的基于RNN的编码-解码结构如图2所示。
下面以LSTM机制为例来描述基于RNN模型的编码阶段的文字到语义以及解码阶段的语义到乐符的转换过程。
5、输入输出格式如下:
文字对应的输入格式:
音符对应的输出格式:
其中:
Kx和Ky分别是文字和音符的字符个数,Tx和Ty分别是一段文字和对应音符的长度。
6、对于encoder:
首先,该模型在encoder阶段使用bidirectional recurrent neural network(lstm)构建,下面是生成正向隐层 的步骤:
其中:
是文字字符对应的词向量矩阵。 和 是权重矩阵, 是偏置向量,m是词向量的维度,n是隐层数。
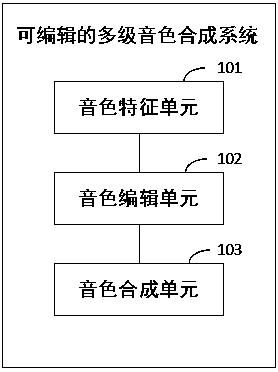
反向隐层 可以通过相似的计算获得。
我们可以拼接正向和反向隐层向量获得 如下所示:
7、对于decoder:
在Decoder阶段,生成隐层状态设为st的步骤,如下:
其中:
是音符字符对应的词向量矩阵。Wo,WC,Wi,Wf∈Rn×m,Uo,UC,Ut,Uf∈Rn×n和Co,CC,Ci,Cf∈Rn×2n是权重矩阵, 是偏置向量,m是词向量的维度,n是隐层数。
生成下一个音符条件概率的公式如下:
yt=argmaxy p(y|st,c,yt-1)(16)
8、代价函数:
使用交叉熵代价函数:
训练与生成
如图3、图4所示,训练语料的格式为一首歌的每一个字对对应一个或者多个音符,这样,训练和生成过程就相当于一个翻译过程。在训练过程中,把整首歌作为输入在编码器阶段生成一个表征向量再由表征向量和上一个音符在解码器阶段生成对应的音乐(即一串音符),再根据生成的音符和本来正确的音符,设计一个损失函数,在训练阶段不断更新参数。在生成过程中,我们可以输入若干句话或者关键词,生成一段符合文字风格或者意境的音乐。
实现所述的一种基于共同语义空间的个性化音乐生成方法的装置,包括将文字映射到共同语义空间表示的影射模块和用于将共同语义空间表示转化为乐曲的转化模块。
一种基于共同语义空间的个性化音乐生成方法及装置专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。













动态评分
0.0