








专利摘要
本发明涉及一种基于能量及谐波的语音端点检测方法,包括如下步骤:将数字化声音信号进行预处理,保存在一段缓存中;每输入一帧信号就移位更新缓存并调整能量阈值,根据能量初步判出语音起点Tstart,然后从当前缓存中搜索具有浊音谐波特征的信号;如果发现浊音,则搜索语音的精确起点,反之则继续根据能量搜索语音起点;搜索到语音精确起点后,根据信号能量寻找语音终点。本发明的优点是:能够根据噪声强度调节精度,所以对输入信号的信噪比有一定自适应能力;由于谐波检测可以过滤突发噪声,所以能量检测较宽泛,不会漏掉能量较弱的语音;随时根据噪声调节阈值,所以能迅速适应噪声的强度和类型变化,特别能适应电信系统中的信道噪声突变。
权利要求
1、一种基于能量及谐波的语音端点检测方法,其特征在于,包括如下步骤:
1)对输入的数字化声音信号分帧并进行加窗、预加重,每帧信号包含F个采样点,其中F为整数;
2)采用一段缓存,保存最前面的L帧信号,其中L为大于25的整数且L帧的时间长度大于200毫秒;
3)通过缓存中信号的能量大小对语音起点进行初步检测;包括:
31)利用缓存中前r帧信号估计噪声能量,其中7<r<13且r为整数;用符号Ei表示第i帧信号能量,计算前r帧信号能量均值
32)根据噪声能量,设定能量阈值Thd,计算方法为:Thd=E+σ/α=E+E·d/α,其中α是灵敏度系数,0<α<1;
33)能量阈值Thd确定后,进行能量检测;如果缓存中有tstart_energy毫秒连续信号的能量均值大于Thd,则标记这段连续信号的第1帧为Tstart,并触发谐波检测,其中tstart_energy是常数,单位为毫秒,范围为80<tstart_energy<150;如果缓存中没有满足上述条件的信号段,则输入一帧新信号,更新缓存和阈值Thd,并在更新后的缓存中搜索语音起点;
4)在能量检测初步判出语音起点Tstart后,从当前缓存中搜索具有浊音谐波特征的信号,如果搜索到了浊音,则认为缓存中存在语音,进入步骤5)对语音起点进行进一步的精细搜索;如果没有搜索到浊音,则删除Tstart标记,并回到步骤3);
5)在当前缓存中精确搜索语音起点;包括:从Tstart顺次向前搜索满足如下条件的一帧信号:从这一帧开始,信号能量逐帧递增,则这帧信号的前一帧就判为语音起点。
2、按权利要求1所述的基于能量及谐波的语音端点检测方法,其特征在于,所述步骤5)完成后,根据缓存中信号的能量检测语音终点,检测过程是:如果缓存中有一段长度为tend_energy毫秒的连续信号,其中tend_energy是常数,单位为毫秒,范围为60<tend_energy<120,其每帧能量都大于终点能量阈值Thdend,则更新缓存;不断更新缓存和阈值Thdend,直到在缓存中搜索不到这样的信号段,则把缓存中的第一帧信号判为语音终点。
3、按权利要求1所述的基于能量及谐波的语音端点检测方法,其特征在于,所述步骤3)和步骤4)中,所述更新能量阈值的过程包括:计算缓存中前r帧信号的能量均值
a)若
b)若不满足条件a),但满足
c)若不满足条件a)和b),但满足
d)如果上述条件都不满足,说明这r帧信号不是平稳噪声,所以不进行噪声更新;
在更新了E和d后,用公式Thd=E+E·d/α计算出新阈值。
4、按权利要求1所述的基于能量及谐波的语音端点检测方法,其特征在于,所述终点能量阈值Thdend由噪声能量均值E和归一化均方差d确定,表示为:Thdend=E+E·d;缓存更新一次,同样用前r帧信号的能量均值
5、按权利要求1所述的基于能量及谐波的语音端点检测方法,其特征在于,所述步骤33)中,每输入一帧新信号就更新一次缓存,并随之更新阈值Thd,直到找到Tstart为止;更新缓存的过程是:抛弃缓存中第1帧内容,把缓存第2至第L帧的内容向前移动一帧,把新一帧信号存入缓存第L帧。
说明书
技术领域技术领域
本发明涉及自动语音识别领域,特别涉及一种语音端点检测方法。
技术背景背景技术
自动语音识别系统的输入信号通常是带有噪声的语音,为防止不含语音的信号段进入识别器,以保证系统性能并减少计算开销,需要在信号中检测出用户语音的起点和终点,这个过程称为端点检测。
常用端点检测算法可分为基于规则和基于模型两类。基于规则的方法一般利用信号的能量、过零率、倒谱、长时谱估计等特征计算出距离,并通过距离与阈值的比较和逻辑运算,确定语音是否存在。基于模型的方法一般针对噪声和语音的统计特性分别建立模型,然后根据似然度做出判决。
自动语音识别系统的应用环境较复杂,因此,端点检测必须具有广泛可靠的适应性,这包括:适应各种强度和种类的缓变噪声、迅速适应噪声的强度和种类变化、不受短暂强噪声影响,并且在各种情况下保持稳定的正确率、运算效率和时延。但是,在噪声复杂的环境中,不仅噪声本身没有固定的特征,而且语音特征也常被噪声掩盖。基于模型的方法往往只适用于特定环境,而基于单一特征设定规则的方法既容易受到信噪比限制,又对噪声类型变化比较敏感。因此,很多人通过把多个特征相结合,提高端点检测的可靠性。例如Sahar E.Bou-Ghazale等人在2002年提出的利用能量叠加关系及倒谱特征进行端点检测的方法,该方法可在平稳噪声环境中稳定工作,但该方法对噪声能量突变很敏感,而且由于语音的倒谱特征会受噪声影响,因而不能用于低信噪比的情况。又如Arnaud Martin在2003年提出的把信号能量与浊音特征结合起来的端点检测方法,该方法的缺点是在难以跟踪噪声能量的突变,另外,它需要先检测信号的基频才能确定浊音,所以容易受到基音倍频的干扰,同时,该算法使用了频域上的梳状滤波器,因而在复杂噪声环境中也较难搜索浊音。
发明内容发明内容
本发明的目的是提供一种把信号能量和语音的浊音谐波特征相组合的端点检测方法,该方法适用于大多数语音和噪声环境,不仅能在多种噪声类型和强度下稳定工作,而且能够迅速适应噪声类型和强度的突然变化。
为实现上述发明目的,本发明提供的基于能量及谐波的语音端点检测方法包括如下步骤:
1)对输入的数字化声音信号分帧并进行加窗、预加重等预处理,每帧信号包含F个采样点,长度约为25毫秒,相邻帧间交叠约15毫秒;
2)采用一段缓存,保存最前面的L帧(L>25,L帧的时间长度大于200毫秒)信号;
3)通过缓存中信号的能量大小对语音起点进行初步检测;包括:
31)利用缓存中前r帧信号估计噪声能量,其中7<r<13;用符号Ei表示第i帧信号能量,计算前r帧信号能量均值
32)根据噪声能量,设定能量阈值Thd,计算方法为:Thd=E+σ/α=E+E·d/α,其中α是灵敏度系数,0<α<1;
33)能量阈值Thd确定后,进行能量检测;如果缓存中有tstart_energy毫秒连续信号的能量均值大于Thd,则标记这段连续信号的第1帧为Tstart,并触发谐波检测,其中tstart_energy是常数,单位为毫秒,范围为80<tstart_energy<150;如果缓存中没有满足上述条件的信号段,则输入一帧新信号,更新缓存和阈值Thd,并在更新后的缓存中搜索语音起点;每输入一帧新信号就更新一次缓存,并随之更新阈值Thd,直到找到Tstart为止;更新缓存的过程是:抛弃缓存中第1帧内容,把缓存第2至第L帧的内容向前移动一帧,把新一帧信号存入缓存第L帧;
4)在能量检测初步判出语音起点Tstart后,从当前缓存中搜索具有浊音谐波特征的信号,如果搜索到了浊音,则认为缓存中存在语音,进入步骤5)对语音起点进行进一步的精细搜索;如果没有搜索到浊音,则删除Tstart标记,并回到步骤3);
5)在当前缓存中精确搜索语音起点;包括:从Tstart顺次向前搜索满足如下条件的一帧信号:从这一帧开始,信号能量逐帧递增,则这帧信号的前一帧就判为语音起点。
上述技术方案中,所述步骤5)完成后,根据缓存中信号的能量检测语音终点,检测过程是:如果缓存中有一段长度为tend_energy毫秒的连续信号(其中tend_energy是常数,单位为毫秒,范围为60<tend_energy<120),其每帧能量都大于终点能量阈值Thdend,则更新缓存;不断更新缓存和阈值Thdend,直到在缓存中搜索不到这样的信号段,则把缓存中的第一帧信号判为语音终点。
上述技术方案中,所述步骤3)和步骤4)中,所述更新能量阈值的过程包括:计算缓存中前r帧信号的能量均值
a)若
b)若不满足条件a),但满足
这个更新策略有助于尽快适应阶跃变化的噪声;
c)若不满足条件a)和b),但满足
d)如果上述条件都不满足,说明这r帧信号不是平稳噪声,所以不进行噪声更新。
在更新了E和d后,用公式Thd=E+E·d/α计算出新阈值。
上述技术方案中,所述终点能量阈值Thdend由噪声能量均值E和归一化均方差d确定,表示为:Thdend=E+E·d;缓存更新一次,同样用前r帧信号的能量均值
本发明的优点是:首先,在能量检测初始化时引入了灵敏度系数,能够自动根据噪声强度调节精度;其次,由于本方法中能量检测位于浊音谐波检测的前端,而且两者是“与”的逻辑关系,所以能量阈值设得比较低,既滤掉大部分噪声,又不会将语音误判为噪声,这就可以防止把语音起点能量较弱的部分切掉;另外,由于采用了一段缓存,每输入一帧信号就进行噪声更新,而且在阈值更新策略上允许噪声能量的突变,所以本方法可以迅速适应噪声变化,因而对噪声的适应性较强。本发明对系统输入信号的强度大小有一定的自适应能力,并且对说话人的年龄、性别和说话习惯都没有限制。本发明的特别优势还在于,对于电信系统中的信道噪声阶跃变化有较强的适应性。
附图说明附图说明
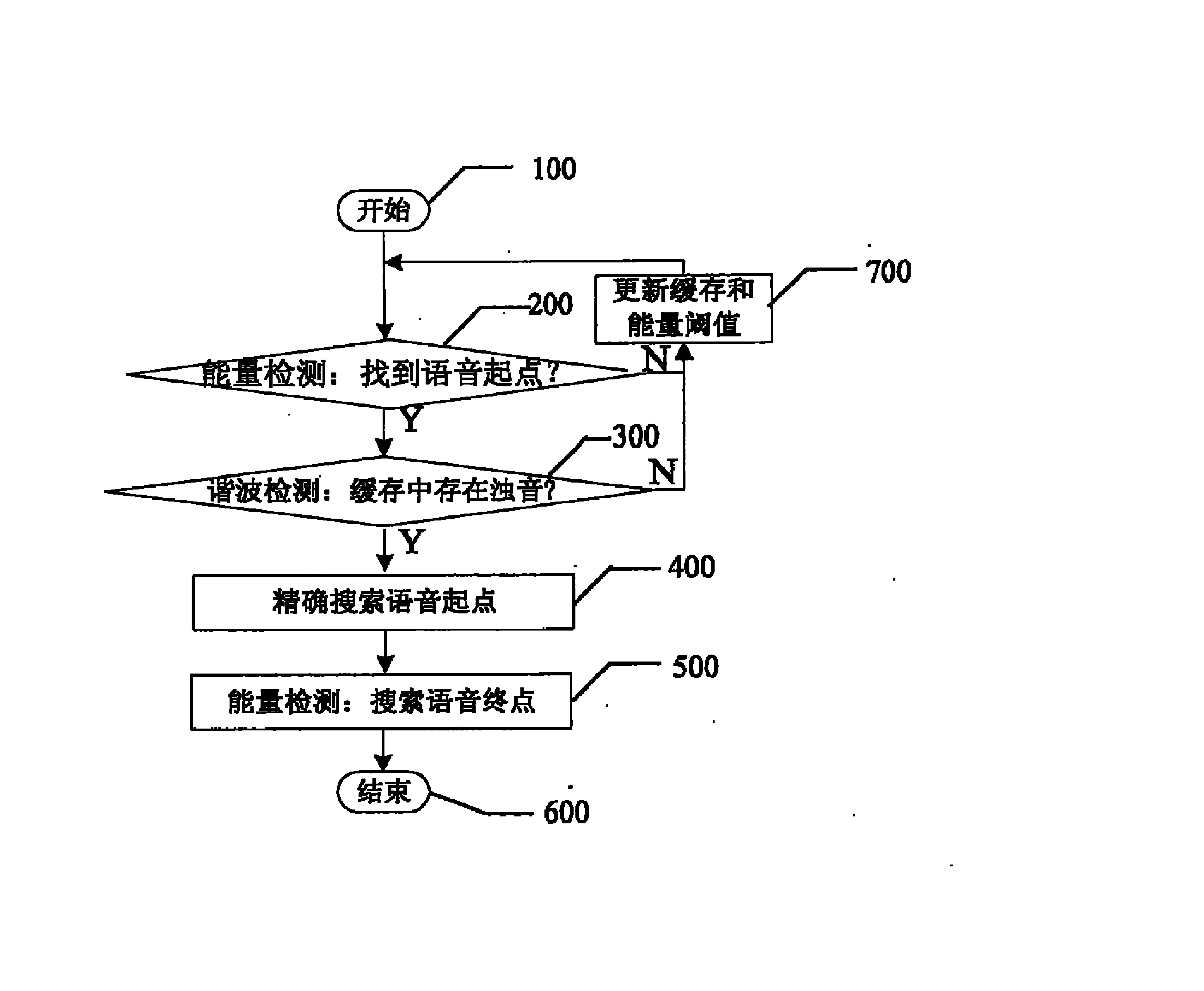
图1是本发明的原理流程图;
图2是一段受到噪声干扰的语音时域图和语谱图;
图3是谐波检测流程图;
图4是连续4帧的谐波判决示意图。
具体实施方式具体实施方式
本发明的原理如下:
首先通过自适应能量检测初步判定语音起点Tstart,然后进入谐波检测步骤,若发现缓存中存在浊音的谐波结构,则判定缓存中存在浊音,并在Tstart附近精确搜索语音起始点;如果没有找到谐波结构,则继续用能量检测搜索语音起点。在找到语音起点之后,通过自适应能量检测搜索语音终点。
因为语音与噪声在能量上是叠加的关系,所以当噪声能量变化比较缓慢时,语音的出现会使信号能量突然增加。能量检测能够不断跟踪缓变噪声,找到能量突增的区域,将其标为语音可能出现的位置。但是,突发噪声也会使信号能量改变,可能导致能量检测误判,所以本发明用谐波检测做进一步判断,去除这些错误。
谐波是浊音的显著特征,它在语谱图中表现为以基频为间距的均匀亮横纹。因为语音由清音和浊音结合构成,而浊音的能量和持续时间又远大于清音,所以,任何有意义的语音段都必须含有较长的浊音。由于浊音能量主要集中在基频和谐波,所以即使噪声很强,含噪浊音仍会保持部分清晰谐波(如图2所示)。如果在较长信号段(>200毫秒)中都没有浊音的谐波结构,则可认为当前信号不含语音。
下面结合附图及优选实施例对本发明作进一步描述。
实施例:
本发明提供的基于能量及谐波的语音端点检测方法包括3个基本步骤:能量检测、谐波检测、语音终点检测。输入信号是数字化声音信号,分为等长(每帧信号包含F个采样点,时间长度为25毫秒左右)且相互交叠约15毫秒的帧,并使用L帧缓存(L>25,L帧信号的时间长度大于200毫秒)。下面具体说明本发明各步骤工作流程。
如图1所示,本发明包括如下步骤:
步骤100:设定L帧缓存,把前L帧输入信号存入缓存中,开始进行端点检测。每输入一帧信号,缓存自动移位更新。
步骤200:根据能量初步检测语音起点。即,根据噪声情况设定一个信号能量阈值Thd,通过缓存中信号的能量判断当前缓存中是否存在语音信号,如果判断为是,则初步确定语音起点Tstart,进入步骤300;如果判断为否,则进入步骤700。本步骤的具体实施过程如下:
对缓存中的L帧数字化声音信号每帧信号分别做预处理(根据系统实际情况,可以包括加窗、预加重等),设每帧长度为F点,先补零到N点(其中N≥F,N=2x,x为整数且x≥8),进行N点离散傅里叶变换,得到离散谱
利用输入信号的前r帧(一般取7<r<13)完成能量检测的初始化。由于用户总是先打开系统才开始说话,所以可认为这r帧信号只含噪声,计算它们的能量均值
能量阈值Thd的计算方法为:Thd=E+σ/α=E+E·d/α。其中α是灵敏度系数(0<α<1),α越大,能量检测的灵敏度越高,即越容易把噪声误检为语音;反之,α越小,越容易把语音误判为噪声。α的确定方法为:若E≥Ex,则α=αmax;若E<Ex,则α=αmin。其中,αmin<αmax。αmin、αmax和Ex都可根据识别器输入信号能量范围事先设定,与使用环境无关。这样,当环境噪声能量大时,自动提高检测灵敏度,防止漏检语音;当环境噪声小时,降低灵敏度,防止过多虚警。另外,要根据语音识别器的输入范围设定Thd的取值区间,并把取值限制在范围内。
能量阈值Thd确定后,进行能量检测。其流程为:如果当前缓存中有tstart_energy毫秒(其中tstart_energy是常数,80<tstart_energy<150)连续信号的能量均值大于阈值Thd,则标记其中第1帧为Tstart,触发谐波检测(即进入步骤300);反之,如果缓存中没有满足此条件的信号段,则抛弃缓存中第1帧内容,把缓存第2至第L帧的内容向前移动一帧,把新一帧信号存入缓存第L帧,并利用更新后的缓存中前r帧信号更新能量阈值(即进入步骤700)。每输入一帧新信号就更新一次缓存和阈值,直到找到Tstart为止;
步骤300:对缓存中的信号进行谐波检测,判断缓存中是否存在浊音,如果判断为是,进入步骤400;如果判断为否,则进入步骤700。本步骤的具体实施过程将在下文中详述。
步骤400:在缓存中精确搜索语音起点。其主要操作是:从Tstart顺次向前搜索满足如下条件的一帧信号:从这一帧开始,信号能量逐帧递增,则这帧信号的前一帧就判为语音起点。
步骤700:根据检测结果及当前缓存更新阈值。更新阈值是本发明跟踪噪声、适应环境变化的主要途径。其具体做法是:每输入一帧信号,缓存就移动更新一帧。计算缓存中前r帧信号的能量均值
1.如果当前缓存的前r帧是平稳噪声,且与原有噪声性质相似,则其均值和归一化均方差变化不大,对应更新策略为:若(
2.若不满足上述条件,但满足
3.若不满足条件1和2,但满足
4.其它情况下,当前r帧包含非平稳噪声,不进行噪声更新。如果这r帧中恰好包含两段平稳噪声的切换点,且两段噪声能量相差较大,随着缓存的逐步更新,前r帧会逐渐更新为新的平稳噪声,并满足第2或第3种情况。这样,系统以最多r帧的延时,实现了对平稳噪声的跟踪。
根据更新后的均值和归一化均方差,可根据Thd=E+E·d/α计算出新阈值,并进入步骤200,在当前缓存中进行能量检测。
步骤500:在检测到语音起点后,根据缓存中信号的能量检测语音终点。检测过程是:如果缓存中有一段长度为tend_energy毫秒的连续信号(其中tend_energy是常数,范围为60<tend_energy<120),其每帧能量都大于终点能量阈值Thdend,则更新缓存和阈值;不断更新缓存和阈值Thdend,直到缓存中没有这样的信号段,把这时的缓存第一帧判为语音终点。
由于能量检测的计算量较小,所以通过能量判决语音终点可以保证系统效率。另外,本算法在语音段中仍不断更新噪声,当环境噪声减弱时,阈值也随之降低,这有助于防止终点判决的提前,减少识别错误。
能量阈值Thdend由噪声能量均值E和归一化均方差d确定,表示为:
Thdend=E+E·d。缓存每移动一帧,同样用能量均值
步骤600:输出语音起点和终点,语音端点检测过程结束。
下面详细叙述本实施例中步骤300的实施过程。
在能量检测初步判出语音起点Tstart后,本步骤利用浊音谐波的各种特征,在当前缓存中搜索具有浊音谐波的信号帧,并据此找到浊音,实现语音起点检测。
实用语音识别系统中,输入信号在各频带的信噪比不同,如果基频附近的噪声能量较强,尽管信号的谐波特征很明显,但其基音却较难检测,所以通过检测基音而检测浊音的方法很容易受到干扰。同样,如果在全频带检测语音的谐波,则信噪比低的频带也会影响浊音检测。因此,本发明根据信号具体情况,只搜索5条最清晰的谐波,或者只搜索基音和相邻3条谐波,从而自动避开信噪比低的频带,可以在噪声较强时稳定工作,并对噪声的变化不敏感。
因为谐波和基音集中了浊音的主要能量,而谐波频率是基音频率的整数倍,所以纯净浊音在频域上存在均匀分布的能量极值,且其间隔等于基音频率。浊音信号即使受到录音设备和噪声的干扰,一般也至少在频域保持4~5个等距能量极值,这就是本实施例中谐波检测的主要依据。如图3所示,本实施例中的步骤300(即谐波检测步骤)包括以下子步骤:
步骤301:开始对缓存中的L帧数字化声音信号进行检测,搜索具有浊音谐波特征的信号。
步骤302:在缓存中取出还未进行谐波检测的一帧信号(设其为缓存中第i帧),根据系统具体情况进行加窗和预加重等预处理,补零到N点,(其中N≥F,N=2x,x为整数且x≥8),然后进行N点离散傅里叶变换,得到离散谱
步骤303:把频带能量的最小值记为εmin,在εbin(其中1<bin<N/2)中,如果εbin同时满足εbin>εbin-1,εbin>εbin+1,且εbin>M·εmin,则标记εbin为能量极值,它有可能对应于谐波或基音,也可能对应于偶然的噪声干扰或语音频谱的小波动。其中M是经验常数,5<M<20。设满足该要求的频带共有u个,按频率从低到高的顺序,记录其位置(即εbin的下标bin)Ik(k=1..u)。之所以要求εbin>M·εmin,是因为当信号中存在谐波时,信号能量分布不平坦,εmin与谐波频带能量相差较大,εbin只有满足此条件,才可能对应于谐波或基音。
步骤304:对可能的基音,搜索最接近于此基音的极值分布,即极值与基音相匹配,其目的是确定当前一帧信号可能对应于哪些浊音。人类的基音范围是60~450Hz,若用pitchα表示基音对应的频带编号,则[60/R]≤pitchα≤[450/R]。其中,[]表示取小于该值的最大整数,R为每个频带的宽度,即频域分辨率(见步骤302)。因为基音和谐波的能量优势在低频较明显,所以只对60~2000Hz范围内的极值进行匹配,对应于[60/R]≤Ik≤[2000/R]。
因此,搜索的过程是:基音pitchα遍历[60/R]到[450/R]内所有整数,分别在编号为[60/R]到[2000/R]范围内的能量极值点中搜索与pitchα及其谐波位置接近的点。由于浊音通常在频域上表现出至少4~5个均匀分布的能量极值点,所以,若现存极值点中存在5个以pitchα为间距的点,其频带编号Fm满足Fm≈m·pitchα,其中
为此,对当前选定的一个测试基音pitchα,从Ik(k=1..u)中搜索与m·pitchα最接近的值Im′,Im′满足|Im′-m·pitchα|≤|Im″-m·pitchα|(1≤m′≤u,1≤m″≤u,m″≠m′)。把所有对应于m·pitchα(其中
步骤305:如果集合{P0,P1,P2,P3....}中存在5个连续元素Pt,Pt+1,Pt+2,Pt+3,Pt+4(其中
为测度5个元素间距是否相等,对集合{P0,P1,P2,P3....}中的任意5个连续元素,计算其间距D1=Pt+1-Pt,D2=Pt+2-Pt+1,D3=Pt+3-Pt+2,D4=Pt+4-Pt+3(其中
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。







动态评分
0.0