






专利摘要
本发明涉及一种应用于语音识别系统的语音端点检测方法,包括如下步骤:1)对输入的语音数据进行分帧处理;2)对语音数据以帧为单位进行FFT运算,根据前N帧语音将整个语音频谱划分为信噪比高低不同的子带,计算出各子带的噪声门限;3)根据各子带的噪声门限对语音端点进行初步判别;4)根据共振峰值对语音端点进行精确判定。与现有技术相比,本发明的优点是:能够适用于各种不同自然环境的语音端点检测;能够适用于噪声较大时的语音端点检测;采用逐帧判别,且计算量小,可实际应用于各种实时语音识别系统中。
权利要求
1、一种应用于语音识别系统的语音端点检测方法,其特征在于,包括如下步骤:
1)输入已数字化的语音数据,对该语音数据进行分帧处理;
2)对语音数据以帧为单位进行FFT运算,根据前N帧语音将整个语音频谱划分为信噪比高低不同的子带,计算出各子带的噪声门限,其中N的取值范围为5~20;
3)根据各子带的噪声门限对语音端点进行初步判别,找出可能为语音端点的帧;
4)提取可能为语音端点的语音帧的共振峰值,结合共振峰值对语音端点进行判定。
2、按权利要求1所述的应用于语音识别系统的语音端点检测方法,其特征在于,所述步骤2)中子带划分的过程包括如下子步骤:
21)计算前N帧各谱线能量的平均值,将其作为当前噪声能量在各谱线的平均值;
22)根据各子带内部的谱线能量尽量接近,而不同子带之间谱线能量尽量不同的原则,把全频带粗分为两个频段;再根据同一原则,对两个频段分别进行划分,得到四个频段,即得到四个子带。
3、按权利要求1所述的应用于语音识别系统的语音端点检测方法,其特征在于,所述步骤2)中各子带噪声门限的计算过程包括如下子步骤:
23)计算前N帧中的各帧在各子带的能量;
24)计算前N帧各子带能量的均值;
25)分别计算每一子带中,前N帧中的各帧在该子带的能量与该子带的在前N帧的能量均值之间的差值;
26)在每一子带中,分别找出步骤25)中得出的该子带N个差值中的最大值,将其作为该子带的噪声门限。
4、按权利要求1所述的应用于语音识别系统的语音端点检测方法,其特征在于,所述步骤3)中语音端点初步判别过程的具体步骤如下:
31)计算当前帧各子带的能量;
32)计算当前帧各子带能量与噪声在同一子带平均能量的差值;
32)根据步骤32)得到的差值与噪声门限加权值的比较,初步判别可能的语音起点与语音终点。
5、按权利要求1所述的应用于语音识别系统的语音端点检测方法,其特征在于,所述步骤4)中结合共振峰值对语音端点进行判定的过程如下:
由步骤3)中得出可能为语音起点的帧,对该帧及其附近帧进行共振峰轨迹提取,若连续得到共振峰值不为0的帧,则可判定位于该帧前且在该帧附近的一帧为语音起点;由步骤3)中得出可能为语音终点的帧,对该帧及其附近帧进行共振峰轨迹提取,若连续得到共振峰值为0的帧,则可判定其中一帧为语音终点。
说明书
技术领域技术领域
本发明涉及自动语音识别领域,特别涉及一种语音端点检测方法。
技术背景背景技术
在语音识别系统中,输入的信号包括语音和背景噪声等,在输入信号中找到语音段,称为端点检测、起终点检测或“语音活动性检测”(Voice Activity Detection),简单的说就是要找出语音段的起点和终点。端点检测准确与否,会直接影响到语音识别系统的性能。这表现在精度和速度两方面:首先良好的端点检测有利于系统准确提取语音的特征,提高语音识别准确率;其次如果语音识别系统只在输入语音时才进行计算,去除掉噪声段的计算,则计算量会大大减小,速度将得到显著提高。
在端点检测方面,前人做了很多有意义的工作。大致思路一般是:
1.把信号分为在时间上连续或叠接的帧;
2.选择一组特征值,并对每一帧都计算这组特征值;
3.适当选择测度距离的方式,以判断两组特征值间差异的大小;
4.对一帧信号,比较其对应特征值与一个确定阈值间的距离,判断出当前帧是否为语音信号。
有效的特征系数有很多,如过零率、零能积、倒谱系数等。当信噪比较高时,这些算法性能都相当不错,但当信噪比很低时,由于噪声干扰较强,大部分特征系数变化不明显,影响了端点检测的准确率。因而,在信噪比较低时,能量就成为大多数系统所采用的特征参数。
1987年,Lynch等提出一种基于全带能量的端点检测方法。该方法通过分别跟踪语音和噪声在全频带的能量,可以在各种噪声条件下实现端点检测。它的延时很短,计算量也较小,但容易错过音节开头的清音,且性能随信噪比的降低而迅速下降。后来,Mark Marzinzik等人把信号分为高低两个频带(0~2000Hz和2000~4000Hz),分别跟踪其能量并形成包络,从而逐帧进行VAD判决。这种方法的准确率有了提高,并可用于较低信噪比的情况,但容易把噪声判为语音,且判出的语音和噪声帧往往交错间隔,不适用于语音识别系统。Jianqiang Wei等人同样注意到了信号在不同频带的信噪比差异,把信号按照临界带的规律分为16个子带,分别估计信噪比并加权计算总测度值,以此判断语音存在与否。这种算法由于分带较多,对信噪比的估计并不可靠,且因为采用大量经验阈值,所以调试复杂,适用的噪声类型也较少。总之,在较强的噪声环境下单纯用能量很难精确地检测出语音的端点。
在专利公开号为1427395的专利文件中,提出了一种采用子带能量并用子带能量为特征建立模型的端点检测方法,在该方法中,采用了大量实验中得到的门限值,由于噪声环境千变万化,经验的门限值往往是会影响系统的可靠性的。
发明内容发明内容
本发明的目的在于,克服现有技术中以子带能量为特征建立的模型只能采用经验门限值的缺陷,根据输入语音初始段噪声的大小实时统计噪声门限;同时采用子带能量和共振峰轨迹作为特征参数,结合两者优点,提供一种适用于各种自然环境的语音端点检测方法。
为达到上述发明目的,本发明提供的应用于语音识别系统的语音端点检测方法,包括如下步骤:
1)输入已数字化的语音数据,对该语音数据进行分帧处理;
2)对语音数据以帧为单位进行FFT运算,根据前N帧语音将整个语音频谱划分为信噪比高低不同的子带,计算出各子带的噪声门限,其中N的取值范围为5~20;
3)根据各子带的噪声门限对语音端点进行初步判别,找出可能为语音端点的帧;
4)提取可能为语音端点的语音帧的共振峰值,结合共振峰值对语音端点进行精确判定。
所述步骤2)中子带划分的过程包括如下子步骤:
21)计算前N帧各谱线能量的平均值,将其作为当前噪声能量在各谱线的平均值;
22)根据各子带内部的谱线能量尽量接近,而不同子带之间谱线能量尽量不同的原则,把全频带粗分为两个频段;再根据同一原则,对两个频段分别进行划分,得到四个频段,即得到四个子带。
所述步骤2)中各子带噪声门限的计算过程包括如下子步骤:
23)计算前N帧中的各帧在各子带的能量;
24)计算前N帧各子带能量的均值;
25)分别计算每一子带中,前N帧中的各帧在该子带的能量与该子带的在前N帧的能量均值之间的差值;
26)在每一子带中,分别找出步骤25)中得出的该子带N个差值中的最大值,将其作为该子带的噪声门限。
所述步骤3)中语音端点初步判别过程的具体步骤如下:
31)计算当前帧各子带的能量;
32)计算当前帧各子带能量与噪声在同一子带平均能量的差值;
32)根据步骤32)得到的差值与噪声门限加权值的比较,初步判别可能的语音起点与语音终点。
所述步骤4)中结合共振峰值对语音端点进行精确判定的过程如下:
由步骤3)中得出可能为语音起点的帧,对该帧及其附近帧进行共振峰轨迹提取,若连续得到共振峰值不为0的帧,则可判定位于该帧前且在该帧附近的一帧为语音起点;由步骤3)中得出可能为语音终点的帧,对该帧及其附近帧进行共振峰轨迹提取,若连续得到共振峰值为0的帧,则可判定其中一帧为语音终点。
与现有技术相比,本发明中子带的划分和门限的确定都是根据实际输入的语音自适应确定,不存在经验值,因此能够适用于各种自然环境的语音端点检测。同时,由于噪声较大(信噪比小于5db)时,仅靠子带能量无法精确地检测出语音的端点,因此本发明加入语音的共振峰轨迹来作为细判的参数。根据浊音有明显共振峰轨迹的特点,将共振峰轨迹作为一组参数用于端点检测算法中,这样即使在噪声较大时,也能够准确地判断出语音的端点。但共振峰轨迹的提取较为复杂,计算量过大,因此本发明首先依靠能量值粗略地找出语音端点的可能位置,再用共振峰轨迹进行精确判断。由于本发明提供的端点检测方法是逐帧进行判别的,并且计算量小,因此本发明可实际应用于各种实时语音识别系统中。
附图说明附图说明
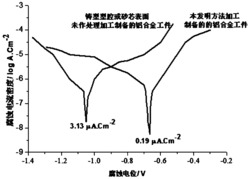
图1是噪声干扰下的一段语音及其语谱图;
图2是本发明提供的应用于语音识别系统的语音端点检测流程图;
图3是共振峰轨迹提取流程图;
图4是端点判定步骤的流程图。
具体实施方式具体实施方式
下面结合附图和优选实施例对本发明做进一步地描述。
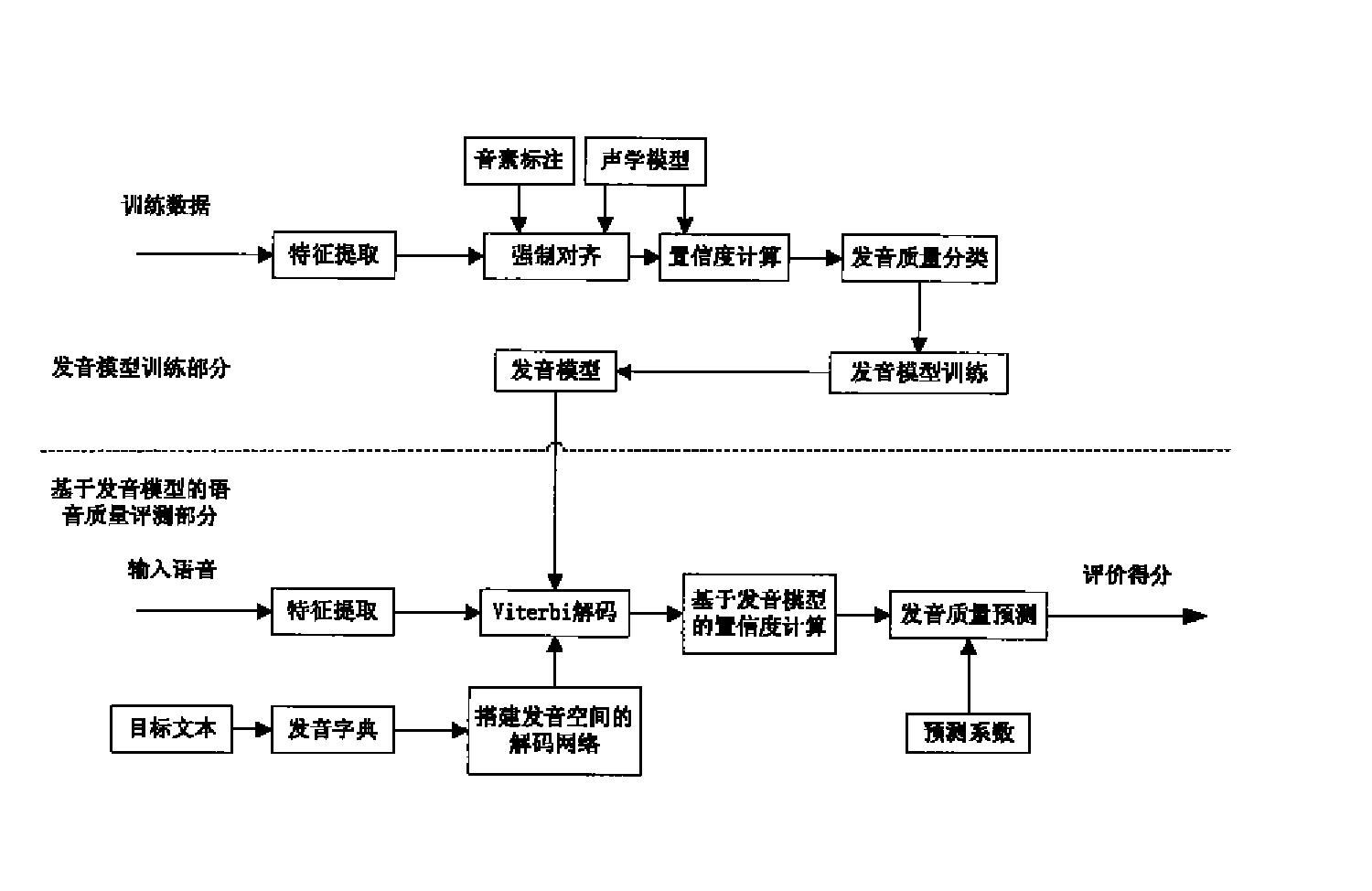
图2是本发明提供的应用于语音识别系统的语音端点检测方法的流程图,如图所示:
步骤101:输入已数字化的语音数据,对该语音数据进行分帧处理,一般来说帧长25ms,帧移10ms。然后分别进入步骤102和步骤105。其中步骤102和步骤105可同时进行,也可先进行步骤102,到端点检测需要利用共振峰轨迹时再进行步骤105。
步骤102:对语音数据以帧为单位进行FFT运算。
步骤103:根据前10帧语音划分子带。划分子带的原理及具体过程如下:
对于多数噪声,其能量在各频带的分布比例都基本保持稳定。本发明利用噪声的这个性质,把输入信号划分为信噪比高低不同的4个子带。
假定输入语音信号的前10帧中不含语音,在这段时间统计噪声特性,并以此为依据进行子带划分。假设做完FFT后得到的128点幅度谱为:|Xp(i)| i=0..127
信号在频段i的短时能量可表示为
Ep(i)=|Xp(i)|2 i=0..127 (1)
把各频段在前10帧的能量求平均,可以得到噪声能量在各频段的平均值,即
其中ε(i)表示噪声在第i个频段的平均能量,它基本反映出噪声在各频带的能量分布。
本算法用噪声的能量分布作为划分子带的依据。这是因为,噪声对各频段的干扰程度不同,如果它在某个频率范围的能量较弱,则语音的能量就容易占优势,以这个频段为依据做端点检测,效果相对较好。为把信噪比不同的频段分开,以避免信噪比高的频带受其他频带干扰,分带的依据是:各子带内部的谱线能量ε(i)尽量接近,而不同子带之间的ε(i)则尽量不同。这样的好处在于,不管噪声的能量如何分布,各子带的信噪比都不会相同,总能在其中找到信噪比较高的子带,获得较好的端点检测效果。
首先把编号为0~127的频段(对应于0~4000Hz)粗分成两个子带,再在其中各自细分出两个子带,最终用4个子带的能量进行端点检测。
把编号为0~127的频带划分成两带的步骤是:首先假设k是其边界点,而εlow和εhigh分别为[0,k]和[k,127]内的各频带能量均值,即
则其方差分别为
在[1,126]的范围搜索k值,使Dlow+Dhigh达到最小,则k即为所求边界点。
对两个子带再分别进行同样的划分,可得到最终的子带划分结果。实际应用中,由于语音的基频多在60Hz以上,所以可以去掉编号为0和1的频段(对应0~62.5Hz),这样只保留了含有语音的频段,可减少噪声的影响。
子带划分结束后,进入步骤104。
步骤104:计算噪声门限。
本端点检测算法的基本判决依据是子带能量。划分子带之后,需从头对噪声各子带的能量及其波动变化进行统计。
设第t带的边界为Lt和Ht,(t=0..3)。第n帧噪声在子带t的能量为
前10帧的子带能量均值
各子带能量波动的均值,即标准差为
其中dt(n)表示第n帧噪声第t子带能量与其均值之间的距离
dt(n)=|Et(n)-Et|(n=0..9,t=0..3) (10)
波动的最大值dt,max为第t带在前10帧中波动的最大值。即
dt,max=max{dt(0),dt(1)......dt(9)} (t=0..3) (11)
将dt,max作为噪声门限。
步骤105:用峰值选取算法来提取共振峰轨迹,如图3所示,其具体步骤如下:
步骤202:对步骤101得出的一帧语音,计算出线性预测AR模型系数,然后递推求出LPC倒谱系数。
步骤203:对LPC倒谱系数作反FFT,即可求出声道频响对数特性{F(i)}i=1,2,...,M,M为FFT点数。
步骤204:选取步骤203中所求得的频响特性峰值点为当前帧语音的共振峰频率:
Fi=i1,如果F(i1)>F(i1+1)且F(i1)>F(i1-1)且FL<i1<FH
其中[FL,FH]是根据语音学知识事先设定的F1的范围。
若无满足以上条件的峰值点,则Fi=0;
步骤205:得到共振峰轨迹,作为端点检测的特征参数。
以上是步骤105进行共振峰轨迹提取的具体过程。
步骤106:综合步骤104和步骤105得出的数据,进行端点检测判决。噪声的固有特性就是不断波动变化。但对大多数环境噪声来说,各子带的能量波动范围有限。语音信号的到来会在原有能量的基础上增加整个信号的能量,所以,当输入信号的能量分布与噪声能量分布相类似,而总能量又接近噪声能量时,可认为信号中不含有语音。反之,如果某个子带的能量远远大于噪声能量的均值,则信号中很可能含有语音。
如图4所示,进行端点检测判决的具体步骤如下:
步骤301:设置一个端点检测标记Flag,其初始值为0。计算当前帧各子带的能量,记为St(t=0..3)。
步骤302:计算当前帧子带能量St与噪声该子带平均能量的差距值Dt
Dt=St-Et(t=0..3) (12)
步骤303:判断标记Flag是否为1。若判断为是,直接进入步骤307;若判断为否步骤,进入步骤304。
步骤304:判断是否有连续5帧满足:Dt>10dt,max,t∈{0,...3}或Dt1>5dt1,max且Dt2>5dt2,max,t1,t2∈{0,...3}?若判断为是,进入步骤305;若判断为否,回到步骤301,检测下一帧数据。
因为语音只会增加信号能量,所以(12)式中不取绝对值。若Dt<σt,则可肯定该子带是噪声,同理,若任何一个子带满足
Dt>10dt,max (13)
则信号中含有语音的可能性很大。若有两个子带的能量满足Dt>5dt,max,即
(其中dt,max,dt1,max,dt2,max由(11)获得),则信号中含有语音的可能性也很大。由于噪声可能出现不规则的小脉冲,带来能量的骤增和骤减。所以,当有连续5帧信号满足(13)式,或有连续5帧信号满足(14)式时,信号可能处于语音段。
步骤305:判断是否有连续5帧满足Ft>0?若判断为是,进入步骤306;若判断为否,回到步骤301,检测下一帧数据。这一步骤是根据共振峰轨迹判断,如果此时连续5帧的共振峰值不为0,则可判定语音信号的起点位置。
步骤306:将当前位置前推10帧作为语音信号的起点位置。将标记Flag的值修改为1。
步骤307:判断是否有连续20帧满足:Dt>dt,max,t=0,...3或Dt1>3dt1,max,t1∈{0,...3}且Ft=0,t=0,...3?若判断为是,进入步骤308;若判断为否,回到步骤301,检测下一帧数据。由于语音段的尾部能量常相对较小,为保证不把语音段的结尾截掉,如果当前一帧信号处在语音段中,则只要当前帧有两个子带的能量满足Dt>dt,max,或有一个子带满足Dt>3dt,max就认为有可能是语音结尾,然后根据共振峰轨迹判断如果连续20帧共振峰值为0则判定当前位置为语音结束。
步骤308:将当前位置作为语音终点。
以上是步骤106进行端点检测判决的具体过程。
步骤107:语音端点检测过程结束,输出结果。
本实施例是以输入信号的前10帧作为划分子带、确定噪声门限的依据。容易理解,本发明可以采用前N帧作为划分子带、确定噪声门限的依据,其中N为正整数。在实际应用中,可以根据情况灵活改变N的大小,但N的取值最好应在5~20之内。
本发明提出了一种基于子带能量和共振峰轨迹的语音端点检测算法,其子带的划分和门限的确定都是根据实际输入的语音自动确定的,不存在经验值,在大部分情况下,基于子带能量能够较准确的检测出语音的端点,然而在噪声相对较大(信噪比小于5db)时仅靠子带能量已经不能够准确的检测出语音的端点,因此本发明加入语音的共振峰轨迹来作为细判的参数,众所周知,浊音有着明显的共振峰轨迹,而清音和噪声则没有,即使在强噪声情况下,浊音的共振峰轨迹还是很明显的。因此可以根据这一特点将共振峰轨迹作为一组参数用于端点检测算法中,这样即使在噪声较大时,也能够准确地判断出语音的端点。图1所示是0db环境下录的一段语音,从中可精确的根据共振峰轨迹判断出语音的端点。但共振峰轨迹的提取较为复杂,计算量过大,因此本发明首先依靠能量值粗略地找出语音端点的可能位置,再用共振峰轨迹进行精确判断。
由于本发明提供的端点检测方法是逐帧进行判别的,并且计算量小,因此本发明可实际应用于各种实时语音识别系统中。
本发明可应用于各种语音识别系统中,以嵌入式语音命令识别系统为例:
输入信号:采样率8000Hz,帧长25ms,帧移10ms,至少保证前10帧(100ms)为噪声(在实际系统中,一般都能够满足这样的条件); 按照前述的算法进行端点检测,在实验中采用了1000句汉语(5人,每人200句)的测试集进行试验,在不同信噪比的噪声环境下得到了表1的实验结果,并且端点检测算法的延时小于200ms,
在表1中起始点和终止点的正确率按照前后5帧计算;从表1中可以看出如果信噪比大于5db,基本能够正确地检测出语音的端点,即使在信噪比小于0db时,仍然能够较准确地检测出语音的端点。
表1基于子带能量的端点检测算法性能
一种应用于语音识别系统的语音端点检测方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。







动态评分
0.0