

IPC分类号 : C12N15/31,C12N15/52,C12N15/53,C12N15/54,C12N9/00,C12N15/63,C12N1/15,C12N1/19,C12N1/21,C12N5/10,C12P21/04,C12P21/02,C12P17/00,C12P17/10,C12P17/12,C12P19/02








专利摘要
本发明涉及诺卡噻唑菌素的生物合成基因簇及其应用,具体地提供了一类由诺卡氏菌产生的具有良好抗菌活性的抗生素-诺卡噻唑菌素(Nocathiacins)的生物合成基因簇的克隆、测序、分析、功能研究及其应用。整个基因簇共包含37个基因:8个与大环骨架生物合成相关的基因,4个与吲哚酸侧链合成相关的基因,6个与糖基合成相关的基因,5个P450氧化还原后修饰酶基因,2个甲基转移酶基因,2个抗性基因,3个调节基因,3个未知功能的基因以及4个与转录翻译有关的基因。通过对上述生物合成基因的异源表达可产生一系列新型硫肽类抗生素。本发明所提供的基因及其蛋白可以用来寻找和发现用于医药、工业或农业的化合物或基因、蛋白。
说明书
技术领域技术领域
本发明属于微生物基因资源和基因工程领域,具体涉及硫肽类抗生素诺卡噻唑菌素(Nocathiacins)的生物合成基因簇的克隆,序列分析,基因功能研究及其应用。
技术背景技术背景
诺卡噻唑菌素(Nocathiacins)是一类富含元素硫,氨基酸残基被高度修饰的环肽类抗生素,它们作为硫肽家族中十分重要的成员,最初是在筛选对有新青霉素抗性的金黄色葡萄球菌(Methicillin-Resistant Staphylococcus aureus,MRSA)和有多种耐药性的粪肠球菌(Multi-Drug Resistant Enterococcus faecium,MREF)的生长有抑制作用的抗生素的过程中,从土壤样品中发现的[J.Antibiot.1998,51,715]。1998年,Tokushima研究中心率先从拟无枝酸菌(Amycolatopsis sp.MJ347-81F4)中分离纯化到了MJ347-81F4-A(Nocathiacin Ⅰ)和B,并完成了它们的发酵、活性测试和结构测定,但没有确定其绝对构型。2003年,Bristol-Myers Squibb药物研究所又从诺卡氏菌(Nocardia sp.WW-12651)中发现了Nocathiacin Ⅰ、Ⅱ、Ⅲ,并对其进行了发酵、分离纯化和活性测试,还利用NMR、X-ray等方法首次确定了其绝对构型(图1)[J.Antibiot..2003,56,226,232;Clough,B.;J.Org.Chem.2002,67,8699]。
诺卡噻唑菌素与硫肽家族其他抗生素一样也拥有一个以三取代的吡啶为核心,由多个噻唑及脱水氨基酸所构成的环肽中心。其中Nocathiacin Ⅰ在结构上与该家族的另一成员糖硫己糖二酐α极其相似,不同之处在于多了一个2,3-脱氢丙氨酰胺的边链,吲哚酸单元与大环相连部分的酯键替代了原来的硫酯键。
研究表明诺卡噻唑菌素可以很好地抑制革兰氏阳性菌的生长,特别是对多种耐药性的条件致病菌具有极强的杀伤作用。其中Nocathiacin Ⅰ对MRSA的MIC值为0.003μg/mL,对有青霉素抗性的肺炎链球菌(penicillin-resistant Streptococcus pneumoniae,PRSP)的MIC值达到0.001μg/mL,比万古霉素高出10-20倍。同时,它还对近期出现的有万古霉素(Vancomycin)抗性的粪肠球菌(vancomycin-resistant Enterococci faeccium,VREF)具有良好的抗性,MIC值为0.015μg/mL。而且与万古霉素相比,诺卡噻唑菌素对感染MRSA的小鼠具有更加显著的疗效,Nocathiacin Ⅰ、Ⅱ、Ⅲ的PD50值分别为0.8、0.62、0.89mg/kg,万古霉素在同样条件下仅为1.3mg/kg。Nocathiacin Ⅰ和Ⅱ作为硫肽家族抗菌活性最好的两个化合物,在较低pH下还比其他成员具有更好的水溶性,可能是因为分子中含有一个二甲基氨基己糖的缘故[Med.Chem.Lett.2004.14.171-175]。
近期发现这类抗生素的作用机制与硫链丝菌肽类似,也是与50S亚基的23S rRNA-L11蛋白复合物结合,通过阻止或促进L11构象的变化,影响aa-tRNA.Ef-Tu.GTP复合物的识别及延伸因子的GTPase活性,从而抑制细菌体内蛋白质的合成来发挥活性作用的[J.Am.Chem.Soc.2008,130,12102-12110]。目前其具体的构效关系还不是很清楚,但据推测它们相似的环肽中心可能是其具有优越活性的关键结构。
诺卡噻唑菌素作为新一代抗感染药物的先导化合物,自发现之日起就引起了科学家们的浓厚兴趣。考虑到它们的溶解度尚未达到静脉注射药剂的要求,不少化学家对其进行了化学半合成改造。Bristol-Myers Squibb药物研究所通过在Nocathiacin Ⅰ上添加了一些极性水溶性基团,来提高它们的生物利用度:如在吡啶环的羟基上或在吲哚酸侧链的氮上烷氧化[Bioorganic & Medicinal Chemistry Letters.2004,14,3743-3746];通过Michael加成在2,3-脱氢丙氨酰胺边链上添加氨或硫醇[Tetrahedron Letters.2004,5,1059-1063];或者用化学法或酶法去掉2,3-脱氢丙氨酰胺,得到Nocathiacin Ⅳ,再进一步烷氧化或添加烃基胺[J.Org.Chem.2002,67,8789]。但这些方法往往很难在提高水溶性的同时保持原始结构良好的抗菌活性。而这类抗生素的化学结构极其复杂,二十多年来人们只完成了部分模块和酸性水解产物的合成[Tetrahedron Lett.1984,25,2127;J.Org.Chem.1996,61,4623;J.Org.Lett.2003,5,4421;Tetrahedron Lett.1991,32,4263;Angewandte Chemie.2005,117,3802-3806;Chem.Commun.2008,591-593]。直到近几年有机合成大师Moody和Nicolaou等人才完成了启动噻星A、淀硫霉素D、硫链丝菌肽、盐屋霉素A、GE2270A/T的全合成,诺卡噻唑菌素的全合成还没有人报道[Angew.Chem.Int.Ed.2007,46,7930-7954]。并且由于该类抗生素复杂的多环结构,众多的手性中心,使得单纯利用全合成的方法进行改造步骤繁多,实际生产成本过高。
而近年来随着基因组学和蛋白质组学的深入研究以及新型生物技术的快速发展,使我们利用微生物作为“细胞工厂”,通过遗传控制来大量合成具有良好生物活性和新型作用机制的天然产物及其类似物成为可能。这也为我们在微生物体内获得所需要的新型硫肽类抗生素提供了一条新的思路。
因此我们以微生物来源的诺卡噻唑菌素为目标分子,从克隆诺卡噻唑菌素的生物合成基因簇出发,采用微生物学、分子生物学、生物化学以及有机化学相结合的方法来研究其生物合成,阐明其生物合成途径及调节机制,在此基础上运用代谢工程的原理,合理修饰诺卡噻唑菌素的生物合成途径,探索生物利用度更好、并能通过微生物发酵大量生产的新型药物。
发明内容发明内容
本发明涉及一类由诺卡氏菌产生的具有良好抗菌活性的抗生素-诺卡噻唑菌素(Nocathiacins)的生物合成基因簇的克隆、测序、分析、功能研究及其应用。
本发明中整个基因簇共包含37个基因的核苷酸序列或互补序列(序列1)(SEQ ID NO:1),其中有8个基因noc28,noc20,noc21,noc22,noc23,noc9,noc24和noc30负责Nocathiacin Ⅰ大环骨架的生物合成;4个基因noc25,noc26,noc27和noc29负责吲哚酸侧链的生物合成;6个基因noc6,noc10,noc11,noc12,noc13和noc14负责4-N,N-二甲基-2,4,6-脱氧己糖的生物合成;5个细胞色素P450氧化还原酶基因noc7,noc15,noc16,noc18,noc19,负责Nocathiacin Ⅰ的氧化还原后修饰;2个甲基转移酶基因noc8,noc36,分别负责Nocathiacin Ⅰ的甲基化后修饰和自身的抗性;2个抗性基因noc17,noc37;3个调节基因noc5,noc33,noc34;4个与转录翻译有关的基因noc1,noc2,noc3,noc4;以及3个未知功能的基因noc31,noc32,noc35。
本发明还提供了一个编码诺卡噻唑菌素前体肽的核苷酸序列,由序列2中的氨基酸序列组成,命名为noc28,其基因的核苷酸序列位于序列1中第38432-38581碱基处。
本发明还提供了一个编码诺卡噻唑菌素噻唑环形成的环化酶的核苷酸序列,由序列3中的氨基酸序列组成,命名为noc23,其基因的核苷酸序列位于序列1中第30980-32875碱基处。
本发明还提供了一个编码诺卡噻唑菌素噻唑环形成的NADH脱氢酶的核苷酸序列,由序列4中的氨基酸序列组成,命名为noc22,其基因的核苷酸序列位于序列1中第29544-30767碱基处。
本发明还提供了一个编码诺卡噻唑菌素大环骨架形成的脱水酶的核苷酸序列,由序列5中的氨基酸序列组成,命名为noc21,其基因的核苷酸序列位于序列1中第26965-29523碱基处。
本发明还提供了一个编码诺卡噻唑菌素大环骨架形成的脱水酶的核苷酸序列,由序列6中的氨基酸序列组成,命名为noc20,其基因的核苷酸序列位于序列1中第25968-26960碱基处。
本发明还提供了一个编码自由基SAM硫胺合成酶的核苷酸序列,由序列7中的氨基酸序列组成,命名为noc27,其基因的核苷酸序列位于序列1中第36848-37948碱基处。
本发明还提供了一个编码酰基-CoA合成酶的核苷酸序列,由序列8中的氨基酸序列组成,命名为noc25,其基因的核苷酸序列位于序列1中第34680-35912碱基处。
本发明还提供了一个编码酰基转移酶的核苷酸序列,由序列9中的氨基酸序列组成,命名为noc26,其基因的核苷酸序列位于序列1中第35933-36820碱基处。
本发明还提供了一个编码SAM依赖的氧化酶或甲基转移酶的核苷酸序列,由序列10中的氨基酸序列组成,命名为noc29,其基因的核苷酸序列位于序列1中第38714-39976碱基处。
本发明还提供了一个编码N-双甲基转移酶的核苷酸序列,由序列11中的氨基酸序列组成,命名为noc10,其基因的核苷酸序列位于序列1中第14990-15703碱基处。
本发明还提供了一个编码NDP-己糖3位C上的甲基转移酶的核苷酸序列,由序列12中的氨基酸序列组成,命名为noc11,其基因的核苷酸序列位于序列1中第15728-16972碱基处。
本发明还提供了一个编码NDP-己糖-3-酮还原酶的核苷酸序列,由序列13中的氨基酸序列组成,命名为noc12,其基因的核苷酸序列位于序列1中第16984-17970碱基处。
本发明还提供了一个编码dTDP-4-酮-6-脱氧葡萄糖2,3-脱水酶的核苷酸序列,由序列14中的氨基酸序列组成,命名为noc13,其基因的核苷酸序列位于序列1中第17988-19418碱基处。
本发明还提供了一个编码NDP-6-脱氧-D-葡萄糖4位C上的氨基转移酶的核苷酸序列,由序列15中的氨基酸序列组成,命名为noc14,其基因的核苷酸序列位于序列1中第19424-20560碱基处。
本发明还提供了一个编码糖基转移酶的氨基转移酶的核苷酸序列,由序列16中的氨基酸序列组成,命名为noc6,其基因的核苷酸序列位于序列1中第11505-12683碱基处。
本发明还提供了一个编码细胞色素P450氧化还原酶的核苷酸序列,由序列17中的氨基酸序列组成,命名为noc7,其基因的核苷酸序列位于序列1中第12704-13912碱基处。
本发明还提供了一个编码细胞色素P450氧化还原酶的核苷酸序列,由序列18中的氨基酸序列组成,命名为noc15,其基因的核苷酸序列位于序列1中第20591-21703碱基处。
本发明还提供了一个编码细胞色素P450氧化还原酶的核苷酸序列,由序列19中的氨基酸序列组成,命名为noc16,其基因的核苷酸序列位于序列1中第21696-22934碱基处。
本发明还提供了一个编码细胞色素P450氧化还原酶的核苷酸序列,由序列20中的氨基酸序列组成,命名为noc18,其基因的核苷酸序列位于序列1中第23507-24649碱基处。
本发明还提供了一个编码细胞色素P450氧化还原酶的核苷酸序列,由序列21中的氨基酸序列组成,命名为noc19,其基因的核苷酸序列位于序列1中第24646-25947碱基处。
本发明还提供了一个编码甲基转移酶的核苷酸序列,由序列22中的氨基酸序列组成,命名为noc8,其基因的核苷酸序列位于序列1中第13909-14532碱基处。
本发明还提供了一个编码甲基转移酶的核苷酸序列,由序列23中的氨基酸序列组成,命名为noc36,其基因的核苷酸序列位于序列1中第43983-44768碱基处。
本发明还提供了一个编码博来霉素抗性蛋白的核苷酸序列,由序列24中的氨基酸序列组成,命名为noc17,其基因的核苷酸序列位于序列1中第22956-23480碱基处。
本发明还提供了一个编码磷酸盐ABC transporter的核苷酸序列,由序列25中的氨基酸序列组成,命名为noc37,其基因的核苷酸序列位于序列1中第44914-45423碱基处。
本发明还提供了一个编码SARP家族的转录调节蛋白的核苷酸序列,由序列26中的氨基酸序列组成,命名为noc5,其基因的核苷酸序列位于序列1中第10404-11387碱基处。
本发明还提供了一个编码热休克蛋白的核苷酸序列,由序列27中的氨基酸序列组成,命名为noc33,其基因的核苷酸序列位于序列1中第42031-42456碱基处。
本发明还提供了一个编码hsp18转录调节因子的核苷酸序列,由序列28中的氨基酸序列组成,命名为noc34,其基因的核苷酸序列位于序列1中第42565-43173碱基处。
本发明还提供了一个编码RNA聚合酶ECF-亚族的信号因子的核苷酸序列,由序列29中的氨基酸序列组成,命名为noc3,其基因的核苷酸序列位于序列1中第8731-9867碱基处。
本发明还提供了一个编码ATP酶的信号因子的核苷酸序列,由序列30中的氨基酸序列组成,命名为noc4,其基因的核苷酸序列位于序列1中第9968-10387碱基处。
本发明还提供了一个编码DGPFAETKE家族蛋白的核苷酸序列,由序列31中的氨基酸序列组成,命名为noc2,其基因的核苷酸序列位于序列1中第8282-8725碱基处。
本发明还提供了一个编码50S核糖体蛋白L18的核苷酸序列,由序列32中的氨基酸序列组成,命名为noc1,其基因的核苷酸序列位于序列1中第7731-8084碱基处。
本发明还提供了一个编码未知功能蛋白的核苷酸序列,由序列33中的氨基酸序列组成,命名为noc9,其基因的核苷酸序列位于序列1中第14529-14984碱基处。
本发明还提供了一个编码未知功能蛋白的核苷酸序列,由序列34中的氨基酸序列组成,命名为noc24,其基因的核苷酸序列位于序列1中第32902-34683碱基处。
本发明还提供了一个编码未知功能蛋白的核苷酸序列,由序列35中的氨基酸序列组成,命名为noc30,其基因的核苷酸序列位于序列1中第40174-40914碱基处。
本发明还提供了一个编码未知功能蛋白的核苷酸序列,由序列36中的氨基酸序列组成,命名为noc31,其基因的核苷酸序列位于序列1中第41001-41408碱基处。
本发明还提供了一个编码未知功能蛋白的核苷酸序列,由序列37中的氨基酸序列组成,命名为noc32,其基因的核苷酸序列位于序列1中第41492-41953碱基处。
本发明还提供了一个编码未知功能蛋白的核苷酸序列,由序列38中的氨基酸序列组成,命名为noc35,其基因的核苷酸序列位于序列1中第43228-43758碱基处。
在另一优选例中,所述基因簇包括由noc6至noc30构成的结构基因;或包括由noc1至noc37构成的结构基因、抗性基因和调控基因。
在另一优选例中,所述的基因簇的核苷酸序列如SEQ ID NO:1中第7731-45423位、SEQ ID NO:1中第11505-40916位、或SEQ ID NO:1中第1-44560位所示。
本发明还提供了本发明上述的诺卡噻唑菌素的生物合成基因簇的编码蛋白。较佳地,所述的编码蛋白的氨基酸序列如SEQ ID NO:2-38所示。
本发明还提供了含有上述的诺卡噻唑菌素的生物合成基因簇的表达载体。较佳地,所述的表达载体是粘粒。
本发明还提供了重组的含有上述的表达载体或染色体上整合有上述的诺卡噻唑菌素的生物合成基因簇的宿主细胞。较佳地,所述的宿主细胞是链霉菌。
本发明还提供了一种产生诺卡噻唑菌素的方法,包括步骤:培养上述的宿主细胞从而表达诺卡噻唑菌素,以及从培养液中分离诺卡噻唑菌素。
本发明还提供了上述的诺卡噻唑菌素的生物合成基因簇或其部分基因的用途,它们被用于在S.actuosus ATCC 25421相关基因缺失的突变株中进行异源互补,从而恢复产生诺肽菌素;或者将后修饰基因在S.actuosus ATCC 25421中进行异源表达产生,从而产生诺肽菌素的结构类似物。
序列1的互补序列可根据DNA碱基互补原则得到。序列1的核苷酸序列或部分核苷酸序列可以通过聚合酶链式反应(PCR)或用合适的限制性内切酶消化相应的DNA片段或利用其他合适的技术得到。本发明还提供了获得至少包含部分序列1中DNA片段的重组质粒的途径。
本发明还提供了诺卡噻唑菌素生物合成的微生物体途径,至少其中之一的基因包含有序列1中的核苷酸序列。
本发明所提供的核苷酸序列或部分核苷酸序列,可利用聚合酶链式反应(PCR)的方法或包含本发明序列的DNA作为探针以Southern杂交等方法从其他生物体中得到与诺卡噻唑菌素生物合成基因相似的基因。
包含本发明所提供的核苷酸序列或至少部分核苷酸序列的克隆DNA可用于从诺卡氏菌Nocardia sp.WW-12651基因组文库中定位更多的文库质粒。这些文库质粒至少包含本发明中的部分序列,也包含有Nocardia sp.WW-12651基因组中以前邻近区域未克隆的DNA。
本发明所提供的核苷酸序列或至少部分核苷酸序列可以被修饰或突变。这些途径包括插入、置换或缺失,聚合酶链式反应,错误介导聚合酶链式反应,位点特异性突变,不同序列的重新连接,序列的不同部分或与其他来源的同源序列进行定向进化(DNAshuffling),或通过紫外线或化学试剂诱变等。
包含本发明所提供的核苷酸序列或至少部分核苷酸序列的克隆基因可以通过合适的表达体系在外源宿主中表达以得到相应的酶或其他更高的生物活性或产量的代谢产物。这些外源宿主包括链霉菌、假单孢菌、大肠杆菌、芽孢杆菌、酵母、植物和动物等。
本发明所提供的氨基酸序列可以用来分离所需要的蛋白并可用于抗体的制备。
包含本发明所提供的氨基酸序列或至少部分序列的多肽可能在去除或替代某些氨基酸之后仍有生物活性甚至有新的生物学活性,或者提高了产量或优化了蛋白动力学特征或其他致力于得到的性质。
包含本发明所提供的核苷酸序列或至少部分核苷酸序列的基因或基因簇可以在异源宿主中表达并通过DNA芯片技术了解它们在宿主代谢链中的功能。
包含本发明所提供的核苷酸序列或至少部分核苷酸序列的基因或基因簇可以通过遗传重组来构建重组质粒以获得其生物合成途径,也可以通过插入、置换、缺失或失活进而获得新的生物合成途径。
包含本发明所提供的核苷酸序列或至少部分核苷酸序列的克隆基因或DNA片段可以通过中断诺卡噻唑菌素生物合成的一个或几个步骤而得到新的诺卡噻唑菌素结构类似物。包含DNA片段或基因可以用来提高诺卡噻唑菌素或其衍生物的产量,本发明提供了在基因工程微生物中提高产量的途径。
本发明所提供的核苷酸序列编码核糖体机制诺卡噻唑菌素生物合成的前体肽可以通过插入、置换或缺失,聚合酶链式反应,错误介导聚合酶链式反应,位点特异性突变,不同序列的重新连接,序列的不同部分或与其他来源的同源序列进行定向进化(DNAshuffling),紫外线或化学试剂诱变等方法来产生新的硫肽类抗生素或其他多肽类代谢产物。
包含本发明所提供的核苷酸序列编码的蛋白可以催化合成噻唑环、羟化吡啶环、吲哚酸等结构单元,并可以通过与其他天然产物的生物合成途径或部分生物合成途径重组,来获得包含有着这些结构单元并且具有更好生物活性的代谢产物。
包含本发明所提供的核苷酸序列编码的蛋白可以催化合成诺卡噻唑菌素的大环骨架和其结构类似物。
包含本发明所提供的核苷酸序列编码的蛋白可以催化合成4-N,N-二甲基-2,4,6-脱氧己糖,并可以通过与其他天然产物的生物合成途径或部分生物合成途径重组,来获得新的糖基化产物。
本发明所提供的诺卡噻唑菌素的后修饰基因提供了通过遗传修饰得到类似物的途径,所包含的氧化还原反应也可有其他应用。
总之,本发明所提供的包含诺卡噻唑菌素生物合成相关的所有基因和蛋白信息可以帮助人们理解硫肽类抗生素的生物合成机制,为进一步遗传改造提供了材料和知识。本发明所提供的基因及其蛋白质也可以用来寻找和发现可用于医药、工业或农业的化合物或基因、蛋白。
附图说明附图说明
图1:诺卡噻唑菌素的化学结构。
图2:诺卡噻唑菌素生物合成基因簇的基因结构和限制性内切酶谱。(A)6个交叠的黏粒代表了诺卡氏菌Nocardia sp.WW-12651基因组45kb的DNA区域,S代表限制性内切酶SmaI,实体表示已被DNA测序的部分,黑色粗竖线表示标记的探针部分;(B)诺卡噻唑菌素生物合成基因簇的基因组成。
图3:提出的诺卡噻唑菌素大环骨架的生物合成途径。
图4:提出的诺卡噻唑菌素吲哚酸侧链的生物合成途径。
图5:提出的诺卡噻唑菌素4-N,N-二甲基-2,4,6-脱氧己糖的生物合成途径。
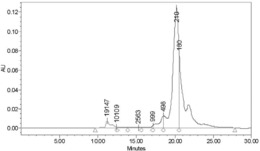
图6:发酵产物Nocathiacin Ⅰ的高效液相色谱-质谱(HPLC-MS)分析。
(A)高效液相色谱;(B)质谱
图7:与诺卡噻唑菌素大环骨架生物合成相关的部分基因对诺肽菌素基因簇中相似基因同框缺失突变株的异源互补。
(A)诺肽菌素产生菌Streptomyces actuosus ATCC25421野生型发酵产物的HPLC-MS检测
(B)诺肽菌素nosE同框缺失突变株发酵产物的HPLC-MS检测
(C)诺卡噻唑菌素noc21异源回补突变株发酵产物的HPLC-MS检测
(D)诺肽菌素nosD同框缺失突变株发酵产物的HPLC-MS检测
(E)诺卡噻唑菌素noc20异源回补突变株发酵产物的HPLC-MS检测
图8:与诺卡噻唑菌素吲哚酸侧链生物合成相关的部分基因对诺肽菌素基因簇中相似基因同框缺失突变株的异源互补。
(A)诺肽菌素产生菌Streptomyces actuosus ATCC25421野生型发酵产物的HPLC-MS检测
(B)诺肽菌素nosI同框缺失突变株发酵产物的HPLC-MS检测
(C)诺卡噻唑菌素noc25异源回补突变株发酵产物的HPLC-MS检测
(D)诺肽菌素nosL同框缺失突变株发酵产物的HPLC-MS检测
(E)诺卡噻唑菌素noc27异源回补突变株发酵产物的HPLC-MS检测
图9:诺卡噻唑菌素生物合成基因簇中部分P450氧化还原后修饰基因对诺肽菌素基因簇中相似基因同框缺失突变株的异源互补。
(A)诺肽菌素产生菌Streptomyces actuosus ATCC25421野生型发酵产物的HPLC-MS检测
(B)诺肽菌素nosC同框缺失突变株发酵产物的HPLC-MS检测
(C)诺卡噻唑菌素noc19异源回补突变株发酵产物的HPLC-MS检测
(D)诺肽菌素nosB同框缺失突变株发酵产物的HPLC-MS检测
(E)诺卡噻唑菌素noc7异源回补突变株发酵产物的HPLC-MS检测
图10:诺卡噻唑菌素生物合成基因簇中部分P450氧化还原后修饰基因在诺肽菌素产生菌Streptomyces actuosus ATCC25421中的异源表达。
(A)诺肽菌素产生菌Streptomyces actuosus ATCC25421野生型发酵产物的HPLC-MS检测
(B)诺卡噻唑菌素noc16异源表达突变株发酵产物的HPLC-MS检测
(C)诺卡噻唑菌素noc18异源表达突变株发酵产物的HPLC-MS检测
诺肽菌素结构类似物A的化学结构
诺肽菌素结构类似物B的化学结构。
图11:诺卡噻唑菌素生物合成基因簇中与丝氨酸边链剪切相关的基因对诺肽菌素基因簇中相似基因同框缺失突变株的异源互补。
(A)诺肽菌素产生菌Streptomyces actuosus ATCC25421野生型发酵产物的HPLC-MS检测
(B)诺肽菌素nosA同框缺失突变株发酵产物的HPLC-MS检测
(C)诺卡噻唑菌素noc9异源回补突变株发酵产物的HPLC-MS检测
符号说明
图1Nocathiacin Ⅰ:诺卡噻唑菌素Ⅰ;Nocathiacin Ⅱ:诺卡噻唑菌素Ⅱ;NocathiacinⅢ:诺卡噻唑菌素Ⅲ;MJ347-81F4-B:诺卡噻唑菌素Ⅰ的去甲基化产物。
图2(A)B3:黏粒pDY2-61-B3,D2:黏粒pDY2-61-D2,C2:黏粒pDY2-61-C2,A1:黏粒pDY2-61-A1,C4:黏粒pDY2-61-C4;字母S代表SmaI限制性酶切位点;(B)suger 4-N,N-二甲基-2,4,6-脱氧己糖生物合成基因cyclopeptide诺卡噻唑菌素大环骨架生物合成基因oxidation诺卡噻唑菌素P450氧化还原后修饰基因Indole acid诺卡噻唑菌素吲哚酸侧链生物合成基因resistance抗性基因regulation调节基因Unknown未知基因。
图3Noc20、21、22、23分别对应本说明书中描述的诺卡噻唑菌素基因簇中的基因noc20、21、22、23所编码的蛋白,LP表示诺卡噻唑菌素的信号肽。
图4Noc25、26、27、29分别对应本说明书中描述的诺卡噻唑菌素基因簇中的基因noc25、26、27、29所编码的蛋白,Ado·表示自由基。
图5Noc6、10、12、13、14分别对应本说明书中描述的诺卡噻唑菌素基因簇中的基因noc6、10、12、13、14所编码的蛋白。
图6(A)15min为Nocathiacin Ⅰ的保留时间(B)1437为Nocathiacin Ⅰ的分子离子峰。
具体实施方式具体实施方式:
以下结合附图对本发明进一步详细说明。
1.诺卡噻唑菌素生物合成基因簇中N,N-二甲基酶基因片段的克隆:
尽管有关硫肽类抗生素生物合成方面的研究早在上世纪70年代末就已开始,但是迄今为止关于它们在微生物体内代谢途径的研究都未能有效突破。早期的研究者主要完成了硫链丝菌肽(Thiostrepton)、诺肽菌素(Nosiheptide)、硫肽霉素Ⅰ(sulfomycin Ⅰ)、GE2270A、A10255G/B/E、诺卡噻唑菌素(Nocathiacins)等的氨基酸前体标记实验(C13、C14、H2、H3、N15等),并由此推测了它们部分主要结构可能的生物合成途径:如认为其中的噻唑或噻唑啉环来源于半胱氨酸和丝氨酸;而吲哚酸或喹哪酸结构则是由色氨酸经过多步转化得到的;还认为它们核心结构的氮杂六元环是通过[4+2]环加成反应形成的[J.Am.Chem.Soc.1979,101,5069;1988,110,5800;1993,115,7557;1993,115,7992;1995,117,7606;1996,118,11363;Biorg.Med.Chem.1996,4,1135;J.Antibiot.1992,45,1499;2001,54,1066;J.Chem.Soc.Chem.Commun.1993,1612;Acc.Chem.Res.1993,26,116;Tetrahedron Letters.2008,49,6265-6268.]。
标记实验同样也显示这类抗生素大多具有相似的氨基酸前体,这在一定意义上说明它们在微生物体内可能是采用相似的生物合成途径得到的。而微生物体内典型的聚肽类天然产物的生物合成途径大体上可以分为两类:核糖体途径和非核糖体途径。Floss小组曾根据氯霉素抑制实验的结果推测这类抗生素可能是采用非核糖体途径合成的。随后研究者们尝试了大量的方法来克隆这类抗生素的生物合成基因簇,如突变株互补、反向遗传学、抗性基因为探针、编码核糖体途径前体肽的基因片段为探针、非核糖体途径生物合成基因的保守序列为引物、转座子随机中断等方法,但是都没有成功。这就提示我们需要寻找一条全新的途径来克隆这类抗生素的生物合成基因簇。
根据糖肽类抗生素的糖基和母体骨架的生物合成基因大都连锁分布在染色体的同一区域上这一特点,本发明人决定从克隆Nocathiacin Ⅰ中脱氧氨基糖的生物合成基因出发,来克隆整个分子的生物合成基因簇。我们首先根据大量微生物来源的天然产物脱氧糖基的生物合成途径[Antimicrobial Agents And Chemotherapy,1999,43,1565-1573;Chemistry& Biology,2004,11,959-969;Molecular Microbiology,2000,37,752-762.]推测了Nocathiacin Ⅰ中4-N,N-二甲基-2,4,6-脱氧己糖可能的生物合成途径,并选取可能存在于该途径催化后期的N,N-二甲基转移酶的保守序列,设计了简并性的PCR引物Dimeth-For1:5′-GCTGAC GTCGCCTGCGGSAC(C/G)GG(A/T/C/G)(G/A/T)(A/T/C/G)(A/T/C/G)CA-3和Dimeth-Rev2:5′-CGCG AACGT(G/C)TC(G/C)GG(A/G)AA CCACCA(A/T/G/C)GG(A/T/G/C)TC-3′,然后以Nocardia sp.WW-12651的总DNA为模板进行PCR扩增,得到约0.3kb的PCR产物,克隆入pSP72载体,经测序分析发现与已知的N,N-二甲基转移酶基因具有很高的同源性。
2.诺卡噻唑菌素生物合成基因簇的克隆,序列分析及功能分析:
将上述克隆到的N,N-二甲基酶基因片段用地高辛标记为探针,对构建好的Nocardiasp.WW-12651的基因组文库进行筛选,共得到6个插入片段互相重叠的黏粒,分别为:cDY446-2-47-A1、B3、C2、C4、D2、D4,涵盖了染色体约50kb的DNA区域(图2A和2B)(制法见实施例2)。选取限制性酶切物理图谱中最左端和最右端的黏粒cDY446-2-47-B3、C2进行亚克隆测序,通过生物信息分析发现,测定的45.560kb的DNA区域,GC含量为73.3%,共包含了44个开放式读码框(open reading frame,ORF),其中与诺卡噻唑菌素生物合成相关的有37个。各个基因的功能分析见表1。
表1诺卡噻唑菌素生物合成基因簇中各基因及编码蛋白的功能分析
注:1.noc1至noc5为诺卡噻唑菌素生物合成的调控基因和抗性基因;noc6至noc30为结构基因;noc31至noc37为调控基因和抗性基因。
2.orf(-7)至orf(-1)为甲氧基丙二酸的生物合成基因(不属于诺卡噻唑菌素基因簇)。
3.诺卡噻唑菌素生物合成基因簇边界确定
根据基因编码蛋白的功能分析,我们初步判定诺卡噻唑菌素的生物合成基因簇为从基因noc1到noc37,共37个开放式读码框。其中1个基因(noc28)负责编码诺卡噻唑菌素的前体肽,7个基因(noc28,noc20,noc21,noc22,noc23,noc9,noc24和noc30)负责对noc28编码的前体肽进行修饰,形成整个大环骨架;4个基因(noc25,noc26,noc27和noc29)负责以色氨酸为前体,合成吲哚酸侧链;6个基因(noc6,noc10,noc11,noc12,noc13和noc14)负责4-N,N-二甲基-2,4,6-脱氧己糖的生物合成;5个细胞色素P450氧化还原酶基因(noc7,noc15,noc16,noc18,noc19)负责Nocathiacin Ⅰ的氧化还原后修饰;2个甲基转移酶基因(noc8,noc36)分别负责Nocathiacin Ⅰ的甲基化后修饰和自身的抗性;此外还有2个抗性基因(noc17,noc37);3个调节基因(noc5,noc33,noc34);4个与转录翻译有关的基因(noc1,noc2,noc3,noc4);以及3个未知功能的基因(noc31,noc32,noc35)。因为orf(-1)-orf(-8)为与甲氧基丙二酸生物合成相关的基因,而基因noc1-noc3则分别编码50S核糖体L18蛋白、DGPFAETKE家族蛋白及ECF亚家族RNA聚合酶信号因子,这些基因可能与诺卡噻唑菌素前体肽的转录法翻译有关。所以诺卡噻唑菌素生物合成基因簇的右侧边界应该在orf(-1)-noc1之间。该序列右侧的基因noc31-37为一些调节基因及抗性基因,可能与诺卡噻唑菌素产生菌自身的抗性和调控相关,所以诺卡噻唑菌素生物合成基因簇左侧边界应该位于noc37处。通过包含诺卡噻唑菌素生物合成基因簇的质粒的异源表达可进一步从体内证实诺卡噻唑菌素生物合成基因簇的边界。
4.诺卡噻唑菌素大环骨架的生物合成
诺卡噻唑菌素的生物合成基因簇中共有8个基因与其大环骨架的生物合成相关。其中noc28,编码诺卡噻唑菌素的前体肽,其C端结构肽序列SCTTCECSCSCSS与诺卡噻唑菌素大环骨架的氨基酸前体顺序完全吻合,而N端富含疏水氨基酸的信号肽部分,则主要负责前体肽的识别,并介导其在胞内转运的。这也从基因水平上证实了诺卡噻唑菌素的大环骨架应该是按照核糖体机制来合成的。该过程类似于细胞肽和蛋白质的合成,首先在核糖体中经转录翻译逐步形成诺卡噻唑菌素的聚肽链前体。接着该前体从核糖体上水解释放,再由noc23编码的环化脱水酶催化其中半胱氨酸上的巯基进攻临位丝氨酸上的羰基,形成5元N杂环,接着脱去一分子水,形成噻唑啉。然后由noc22编码的NADH依赖的氧化还原酶作用脱去一分子氢,将噻唑啉转变为噻唑。接下来在noc20或noc21编码的脱水酶的催化下,脱去丝氨酸残基上的羟基,形成2,3-脱氢丙氨酸,进一步通过分子内Diels-Alder反应形成羟化脱氢哌啶六元环。然后再在noc30编码的未知蛋白及一系列脱水酶和氧化还原酶的作用下经多步反应形成羟化吡啶环肽中心,从而构建了诺卡噻唑菌素中最大的一个环肽结构。整个过程如图3所示。
5.甲基吲哚酸结构单元的生物合成
甲基吲哚酸结构单元的生物合成途径如图4所示。首先以色氨酸为前体,经noc27编码的radical S-adenosylmethionine(AdoMet)类型的蛋白的催化发生一系列分子内重排,再水解脱羧形成3-甲基吲哚-2-甲酸结构。接着通过noc25编码的酰基-CoA合成酶活化吲哚酸的羧基,将其转变成CoA-硫酯键。然后在noc26编码的酰基转移酶的作用下,形成吲哚酸侧链与诺卡噻唑菌素大环骨架间的硫酯键连接。进一步由noc29编码的甲基转移酶转移甲硫氨酸上的甲基到吲哚酸4位的碳上,再由基因簇中的氧化还原酶作用在4位碳上上一个羟基,最后在一系列相关酶的作用下实现吲哚酸侧链与大环骨架间的酯键连接。其中吲哚酸4位的甲基化可能发生在侧链与大环骨架硫酯键连接前或者是连接后。
6.4-N,N-二甲基-2,4,6-脱氧己糖单元的生物合成
诺卡噻唑菌素的生物合成基因簇中共有6个基因与其糖基的生物合成相关。首先一分子磷酸化的D-葡萄糖在dNDP-D-葡萄糖合成酶的作用下被活化,接着由dNDP-D-葡萄糖-4,6-脱水酶催化脱水在4位形成酮基,再由noc13编码的2,3-脱水酶作用脱去另一分子水形成3,4-酮-6-脱氧己糖中间体,然后在noc12编码的3-酮-还原酶的催化下3位被还原成羟基,经3,5异构酶的作用发生差向异构化后,又在noc11编码的甲基转移酶的作用下在3位上一个甲基,再由noc14编码的氨基转移酶催化在4位上一个氨基,然后在noc10编码的N,N-二甲基转移酶的作用下在氨基上加两个甲基,最后由noc6编码的糖基转移酶转移该糖基到诺卡噻唑菌素的大环骨架上,整个过程如图5所示。
7.诺卡噻唑菌素的后修饰过程
诺卡噻唑菌素的生物合成基因簇中共有5个细胞色素P450氧化还原酶基因noc7,noc15,noc16,noc18,noc19,可能与诺卡噻唑菌素生物合成途径中的一系列氧化还原后修饰相关。其中noc7和noc19分别催化诺卡噻唑菌素谷氨酸γ位的羟化和吡啶环上的羟化(图9),noc16和noc18分别催化吲哚酸N上的羟化和3位甲基上的羟化(图10)。在该基因簇中还存在一个未知蛋白noc9,是负责丝氨酸边链的剪切形成酰胺结构的(图11)。
8.诺卡噻唑菌素生物合成基因簇的应用
在克隆、分析诺卡噻唑菌素生物合成基因簇的基础上,我们还发展了一套快速克隆其他硫肽类抗生素生物合成基因簇的通用方法。如利用其中与噻唑环形成相关的环化脱水酶Noc23的氨基酸保守序列,设计PCR引物克隆了硫链丝菌肽、诺肽菌素、盐屋霉素等的生物合成基因簇,同时还利用与诺卡噻唑菌素大环骨架生物合成相关的基因序列通过基因组扫描的方法克隆了硫代菌素的生物合成基因簇。
在此基础上,我们进一步分析比较了这些基因簇和生物合成途径的相似性。如诺卡噻唑菌素与诺肽菌素(nosiheptide)的生物合成基因簇(CN200910053427.7)中一共有15个功能相似的基因(表2),其中包含了8个与大环骨架生物合成相关的基因,4个与吲哚酸侧链合成相关的基因,2个P450氧化还原酶基因以及1个调节基因,并且这些基因的排列顺序和转录方向也基本相似。我们首先通过在诺肽菌素产生菌的体系中对部分功能相似基因的同框缺失初步证实了这些基因与诺肽菌素生物合成的相关性和其可能的功能,在此基础上我们又将诺卡噻唑菌素基因簇中的相似基因导入到这些同框缺失突变株中进行异源互补,经发酵和LC-MS检测,恢复产生了诺肽菌素,进一步证实了这些相似基因与大环骨架、吲哚酸侧链合成及氧化还原后修饰的相关性。如nos B同框缺失突变株的发酵产物鉴定证实Nos B负责诺丝七台谷氨酸γ位的羟化,noc7异源互补突变株的发酵产物鉴定证实其与nos B功能一致。同样方法我们也证实了noc19负责催化吡啶环上的羟化的,noc9负责催化丝氨酸边链的剪切形成酰胺。同时我们还通过2个P450氧化还原酶基因noc16和noc18在诺肽菌素产生菌体系中的异源表达,初步证实了它们可能的功能分别是负责吲哚酸N上的羟化和3位甲基上的羟化。
表2诺卡噻唑菌素与诺肽菌素生物合成基因簇中功能相似基因的同源性比较
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件如Sambrook等人,分子克隆:实验室手册(New York:Cold Spring Harbor LaboratoryPress,1989)或链霉菌手册(Practical Streptomyces Genetics)中所述的条件,或按照制造厂商所建议的条件。除非另外说明,否则百分比和份数按重量计。
实施例1
诺卡噻唑菌素产生菌诺卡氏菌Nocardia sp.WW-12651总DNA的提取:
将100μL Nocardia sp.WW-12651(ATCC 202029)菌丝悬液接种到3mL TSB液体培养基中,30℃,250rpm,振荡培养约36hr,达到对数生长期后期。取3mL接种到50mL TSB中(含5mM MgCl2,0.5%甘氨酸),30℃,250rpm,振荡培养约25hr后达到稳定生长期前期,呈乳白色浑浊,并有大量菌丝悬浮物。将菌液于4℃,3500rpm,离心15min收集菌丝,用裂解缓冲液洗涤两次,得到菌丝约2.5mL。向2.5mL菌丝中加入10mL裂解缓冲液(含溶菌酶5mg/mL),涡旋至均一,再加入无色肽酶(Achromopeptidase)至3mg/ml,混匀。37℃水浴30min。加入0.1mL蛋白酶K(20mg/mL,用裂解缓冲液新鲜配制)、1mL 10%的SDS,混匀后迅速放入70℃水浴,15min,至基本澄清,置冰上冷却。加入2.5mL 5M的KAc溶液,冰上冷却15min。加入15mL Tris饱和的酚,轻轻混匀,再加入15mL氯仿,轻轻混匀,20000rpm,4℃,离心20min。用破口的枪头将水相吸出置于新的离心管中,加入等体积的氯仿∶异戊醇=24∶1混合液抽提,轻轻混匀,12000rpm,4℃,离心10min。再用破口的枪头将水相吸出置于新的离心管中,加入2倍体积的无水乙醇,混匀,有大团的DNA出现。将其钩出,置于新的离心管中,加入5mL70%的乙醇洗涤,将液体倾出,用枪吸干。再加入5mL TE溶解(添加无DNase活性的RNase A至终浓度为50μg/mL),37℃水浴0.5hr。用等体积的饱和酚抽提两次,再用等体积的氯仿∶异戊醇=24∶1的混合液抽提两次,向水相中加入0.1倍体积3M的NaAc溶液,2倍体积的无水乙醇,轻轻混匀,有絮状DNA出现。用70%乙醇洗涤DNA沉淀,吸出液体。再加1mL无水乙醇洗涤,吸出液体,超净台中吹干,溶于适当体积的TE(pH 8.0)中。若难以溶解,可在55℃水浴2hr,最后保存于4℃。
实施例2
诺卡噻唑菌素产生菌诺卡氏菌Nocardia sp.WW-12651基因组文库的构建:
首先通过一系列的稀释实验来确定Sau3AI的用量,在此基础上大量酶切得到的DNA片段略大于40kb,脱磷。载体pOJ446(Gene 1992,116:43-49;US 7,109,019)先用HpaI从两个cos序列中间切开并脱磷,然后再从多克隆位点处用BamHI切开,获得两条连接臂,与制备好的长约40kb的DNA片段连接过夜。从-80℃取出包装试剂盒(Promega PackageneExtract)放到冰上,待其恰好融化,立即加入5uL上述连接液,轻弹混匀,注意不要产生气泡,室温(约22℃)放置3hr。加入445uL Phage缓冲液,上下颠倒混匀。再加入25uL氯仿,上下颠倒混匀,使其缓慢划过整个液体以终止反应,用离心机轻甩,使氯仿沉于底部,保存于4℃。将试剂盒所带的E.coli LE392菌种在LB平板上划线接种进行培养。挑单菌落到3mL LB中(添加30μL 1M的MgSO4溶液和30μL 20%的麦芽糖溶液),37℃,250rpm,振荡培养过夜。再转接500μL菌液到50mL的LB中(添加500μL的MgSO4溶液和500μL 20%的麦芽糖溶液),37℃,250rpm,振荡培养至OD600=0.6-0.8。取2.5μL包装液,加入97.5μL phage缓冲液和100μL E.Coli LE392(OD600=0.67),轻轻混匀,22℃水浴0.5hr。再加入100μL的LB混匀,37℃,水浴75min,涂布到LB平板上(含Am 100μg/mL),37℃培养过夜,至有菌落长出。
平板长有超过50000个克隆,用LB刮下,加入甘油(终浓度18%)和Apramycin(终浓度50ug/ml),按每管200uL分装,于-80℃保存。随机从平板中调取10个克隆,接种于LB培养基中培养,按大肠杆菌质粒的碱法小量制备抽提重组黏粒。HaeⅢ酶切鉴定,并用0.7%的琼脂糖凝胶电泳检测。根据电泳图谱加合各DNA片段的长度,估算每个黏粒插入片段的大小约为35-40kb,并以此计算文库的效价约为30000cfu/μg DNA。因为大多数放线菌染色体DNA的大小约为8Mb,对于插入片段为20kb的文库而言,其效价为2000~5000cfu/μg DNA就足以代表整个基因组。根据以上实验,我们建立的文库效价达到30000cfu/μg DNA,插入片段约为40kb左右,这表明我们建立的文库具有良好的质量,能够满足文库筛选的需要。
实施例3
诺卡噻唑菌素产生菌诺卡氏菌Nocardia sp.WW-12651的发酵、产物分离纯化与鉴定:
首先将300μL-80℃冻存的Nocardia sp.WW-12651菌丝悬液,接种到25mL的种子培养基中(可溶性淀粉2%、葡萄糖0.5%、N-Z Case 0.3%、酵母提取物0.2%、鱼肉提取物0.5%、碳酸钙0.3%),32℃,250rpm培养3天。从中取2mL转接到50mL的发酵培养基中(葡萄糖2%、HY-酵母4121%、营养大豆1%),30℃,250rpm培养4-5天。然后将发酵液合并,转移到离心管中,3800rpm,离心15min,弃去菌丝沉淀。上层清液用等体积的乙酸乙酯萃取两次,合并有机相。用无水MgSO4或无水Na2SO4干燥,过滤,37℃减压浓缩至干。将样品溶于氯仿∶甲醇=9∶1的混合溶剂中,初步用TLC板检测发酵液的提取物中是否有Nocathiacins存在(在长波紫外线下Nocathiacin Ⅰ、Ⅱ、Ⅲ会发出黄绿色荧光,TLC展开剂氯仿∶甲醇∶甲酸=90∶10∶0.1),进一步可以用S.ceolicolor M110进行生物活性检测(Nocathiacins可以抑制S.ceolicolor M110的生长,形成抑菌圈)。
在此基础上将2L发酵液的乙酸乙酯粗提物,溶于氯仿/甲醇的混合溶剂中,100-200目硅胶拌样后,用300-400目的硅胶进行柱层析,洗脱条件:己烷/氯仿=1∶1,100ml;氯仿100ml;氯仿/甲醇=99∶1,100ml;氯仿/甲醇=98∶2,300ml;氯仿/甲醇=97∶3,200ml;氯仿/甲醇=95∶5,300ml;氯仿/甲醇=90∶10,200ml。其中在氯仿/甲醇=95∶5的组分中,检测到了黄绿色荧光的点。收集该组分,30℃减压浓缩至干,进行HPLC半制备柱分离纯化。
检测波长:UV=220nm;
柱子:Agilent ZORAX SB-C185μm 4.6×250mm,PN 880975-902,SN USCL024998,LN B07051;
流动相条件:v=1mL/min;A=H2O(0.1%TFA);B=CH3CN;
收集HPLC保留时间为15min的组分,进行HPLC-MS(ESI)鉴定,为Nocathiacin Ⅰ,对应的[M+H]+分子离子峰为m/z=1437.3。同时我们还用类似方法从Nocardia sp.WW-12651的发酵液中分离纯化到了NocathiacinⅡ、Ⅲ、MJ347-81F4-B等组分,并进行了HPLC-MS(ESI)鉴定,对应的[M+H]+分子离子峰依次为m/z=1421.3(图6)、1266.2、1368.3。
实施例4
PCR克隆诺卡噻唑菌素的生物合成基因:
PCR体系包含:DMSO(8%,v/v),MgCl2(1.5mM),dNTP(0.2mM),兼并性引物(0.2μM),Taq DNA聚合酶(2u)及适量模板Nocardia sp.WW-12651总DNA。首先95℃,5min,1轮;然后94℃,1min,63℃,1min,72℃,1min,10轮;94℃,1min,55℃,1min,72℃,1min,20轮;最后72℃,10min,1轮。PCR结束后,1.5%琼脂糖电泳检查结果。低熔点胶回收预期大小的DNA片段,与载体pSP72的EcoRⅤ消化,CIAP脱磷的2.4kbDNA片段连接,转化大肠杆菌DH5α感受态细胞,涂布在含有适当抗生素的LB平板上,37℃培养至转化子长出。挑取单菌落到液体LB中培养过夜,抽提质粒,BglⅡ和EcoRⅤ双酶切鉴定是否含有预期大小的DNA插入片段。并将插入有预期大小DNA片段的质粒进行测序。
实施例5
核酸分子杂交:
1)DIG DNA标记:将待标记的DNA用无菌水稀释至总体积15μL,沸水浴中加热变性10分钟,立即置于冰盐浴中冷却。接着加入核苷酸混合物(Hexanucleotide Mix)(10×)2μL、dNTP标记混合物(Labeling Mix)2μL、Klenow enzyme labeling grade 1μL(Promega),混合均匀后,37℃水浴约16小时。加入0.8μL0.8M EDTA(pH8.0)以终止反应,加入2.5μL4M LiCl,混合均匀,再加入75μL预冷的无水乙醇沉淀标记后的DNA,置于-80℃沉降40分钟。4℃,12000rpm离心20分钟收集DNA,用预冷的70%乙醇洗涤DNA沉淀,真空干燥后重新溶于50μL TE((pH 8.0)中。
2)DIG DNA探针标记后的质量检测:稀释标记的DNA探针至以下六个梯度,1、10-1、10-2、10-3、10-4、10-5。稀释标记的对照DNA分别至以下浓度1μg/mL,100ng/mL,10ng/mL,1ng/mL,0.1ng/mL,0.01ng/mL。分别取1μL上述浓度的DNA样品点在杂交用的尼龙膜上,根据7)所述步骤进行显色反应,对比标记的DNA探针和DIG标记的对照DNA的显色强度以决定标记的DNA探针浓度。
3)菌落杂交(文库筛选)的膜转移:从中取50μL,加450μL LB稀释得到10-1的稀释倍数,再倍比稀释得到10-2、10-3、10-4、10-5、10-6。从中分别取300μL涂一块规格为15cm×15cm的LB平板(含阿泊拉霉素50μg/mL)。37℃培养过夜,至有菌落长出。选取合适的稀释比例,使每块平板约1200-1500个克隆。用LB照选定的比例稀释文库,均匀涂布四块平板,37℃培养过夜。根据平板的大小剪取尼龙膜,小心地覆盖于平板表面不要产生气泡,做好位置标记,1分钟后取下尼龙膜置于干燥滤纸上,干燥10分钟直至菌落结合在尼龙膜上。原始的平板置于培养箱中4-5hr,使克隆重新生长作为原平板。将尼龙膜置于变性液(0.25M NaOH,1.5M NaCl)饱和的滤纸上15分钟(不要浸过膜),转移至中和液(1.0MTris.HCl,1.5M NaCl,pH 7.5)饱和的滤纸上5分钟。转移至2×SSC(20xSSC储备液(L-1):NaCl,175.3g,柠檬酸钠,88.2g,pH=7.0)饱和的滤纸上自然风干。取下尼龙膜置于烘箱中,120℃固定45分钟。常温下于3×SSC/0.1%SDS溶液中振荡洗涤3小时,以除去细胞碎片。
4)Southern杂交的膜转移:DNA样品在适当浓度的琼脂糖凝胶上电泳至适当距离,做好标记。浸泡于400mL 0.25M的HCl中脱嘌呤20min,使溴酚蓝变黄,用去离子水洗数次。室温下浸入碱性缓冲液中(NaOH 0.5M、NaCl 1M)15min,并轻轻振荡。更换碱性缓冲液后继续浸泡凝胶20min,并轻轻振荡,用去离子水洗三次。取一张每边都比凝胶大1mm的尼龙膜,用去离子水完全浸湿,做好标记。采用向上毛细管转移方法,用10×SSC的转移缓冲液转移8-24hr。用2×SSC略微洗膜,120℃烘烤30min。
5)预杂交和杂交:预热杂交液(20mL/100cm2)至杂交温度68℃,放入杂交尼龙膜,轻轻振荡并保温30分钟。将DIG标记的DNA探针在沸水浴中变性5分钟,立即置于冰盐浴中冷却。冷却后,将DNA探针与合适体积的DIG杂交液(2.5mL/100cm2)混合均匀。去除预杂交液并立即把DNA探针/DIG杂交液加入,轻轻振荡保持杂交温度64℃或68℃约16小时。
6)杂交后严紧洗脱:室温下用2×SSC/0.1%SDS漂洗两次,每次5分钟。68℃,用0.1×SSC/0.1%SDS振荡漂洗两次,每次15分钟。
7)显色反应和检测:严紧洗脱后的尼龙膜在洗涤缓冲液(0.1M马来酸,0.15M NaCl,pH=7.5,0.3%(v/v)Tween 20)中平衡1-5分钟,接着在封闭缓冲液(封闭试剂以10%的浓度溶于0.1M马来酸,0.15M NaCl,pH=7.5)中封闭30分钟,然后在抗体中浸泡30分钟。用洗涤缓冲液漂洗尼龙膜两次后,用检测缓冲液(0.1M Tris-HCl,0.1M NaCl,pH=9.5)中平衡2-5分钟,最后将尼龙膜置于10mL新配制的显色溶液中[NBT(nitroblue tetrazoliumchloride)溶于70%DMF,浓度为70mg/mL,BCIP(5-bromo-4-chloro-3-indolyl-phosphate)溶于水,浓度为50mg/mL。用时10mL显色溶液中加45μL NBT,35μL BCIP],置于黑暗中显色。显色合适后用去离子水漂洗以终止反应。
实施例6
异源互补突变菌株的获得及发酵产物分析:
首先在诺肽菌素产生菌Streptomyces actuosus ATCC25421的体系中构建目标基因同框缺失的突变株。所用载体为含温敏型复制子的质粒pKC1139(Gene 1992,116:43-49;US 7,109,019),将构建好的用于同框缺失的质粒,通过E.coli S17-1(US 5,268,276)和Streptomyces actuosus ATCC25421属间接合转移的方法(见下)导入到诺肽菌素的产生菌中,30℃培养4-5天,筛选具有Am抗性的接合子。然后将获得的接合子接种到TSB液体培养基(阿泊拉霉素(Am)50μg/ml)中30℃振荡培养2-3天。再涂布于含有阿泊拉霉素100μg/ml的MS平板上,在42℃整合使之发生单交换。将获得的单交换突变株在30℃进行10-20轮的松弛培养(不加阿泊拉霉素),再通过抗性筛选得到对阿泊拉霉素敏感的突变株。抽提总DNA,进行PCR筛选,获得发生双交换的突变株。并对获得的双交换突变株进行PCR测序在基因型上加以验证,确实发生了同框缺失,并且内部基因无突变。然后通过发酵和LC-MS检测,在表型上加以验证,不再产生诺肽菌素,就得到了目标基因同框缺失的突变株。
在此基础上,将诺卡噻唑菌素生物合成基因簇中功能相似的基因和来自于pLL6212(将红霉素启动子序列克隆入质粒7zf(购自Promega)所获得的衍生质粒)的红霉素启动子ErmE*克隆到整合型载体pSET152(Gene 1992,116:43-49)的相应位点中,得到用于异源互补的质粒。将构建好的用于异源互补的质粒通过属间接合转移的方法导入到诺肽菌素相应基因同框缺失的突变株中,经阿泊拉霉素抗性筛选,得到异源互补突变株。所得的突变株在基因型上进行验证后,进行发酵和LC-MS检测,恢复产生了诺肽菌素,说明这些基因的功能是一致的(图7、8、9和11)。
其中,图7说明了noc21和noc20分别回补了NosE和NosD的脱水酶功能。
图8说明了noc25回补了NosI的酰基-CoA合成酶功能,noc27回补了NosL的自由基SAM硫胺合成酶功能。
图9说明了noc19和noc7分别回补了NosC和NosB的P450氧化还原酶功能(noc7和noc19分别催化诺卡噻唑菌素谷氨酸γ位的羟化和吡啶环上的羟化)。
图11说明了noc9回补了NosA编码蛋白的丝氨酸边链剪切功能。
E.coli S17-1和诺肽菌素产生菌Streptomyces actuosus ATCC25421及同框缺失突变株属间接合转移的方法如下:
诺卡噻唑菌素的生物合成基因簇及其应用专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。














动态评分
0.0