









专利摘要
本发明提供一种基于发音模型的语音质量评测方法,包括1.1)确定发音质量音素集;1.2)对训练数据划分发音质量等级;1.3)依据发音质量等级训练发音模型;2.1)提取待评测发音段的语音特征;2.2)构建基于所述发音模型的解码网络,进行Viterbi解码;2.3)对每个音素计算基于发音模型的置信度;2.4)根据所述置信度得出所述待评测发音段的发音质量。本发明不仅对不同的音素进行建模,还将发音质量的优劣加以区分。基于发音模型的语音质量评测方法中搭建的解码网络,可以充分利用发音质量的差异,从而获得更为准确的音素分割点,基于发音模型的置信度计算更接近理想的音素后验概率值,因此这种基于发音模型的语音质量评测方法具有更好的评估性能。
说明书
技术领域技术领域
本发明属于发音质量评估技术领域,具体地说,本发明涉及一种基于发音模型的语音质量评测方法。
技术背景背景技术
在自然条件下使用发音质量评估系统,不同于在理想实验环境下的使用,这时发音质量评估系统的性能会有很大的降低。而且对于真实的口语,在语音中会参杂很多非语音,譬如非正常停顿、咳嗽声以及很多的环境噪声,这都给发音质量评估系统达到原有的评估精度造成了困难。另外,用户说的词汇如果不在发音质量评估系统预先设定的领域范围内或者用户的发音带有一定的方言特色,也较容易造成评估误差。总之,对于商业化的发音质量评估系统,用户的期望是尽可能的准确评估发音质量,与此同时还要求比较快的评估速度。因此,目前各种语音质量评测方法都是围绕这两点来展开的。
语音质量评测方法可以对连续语音进行音素段的切分,然后在特定音素段内对目标发音进行假设检验,通过预先训练的阈值对待评估发音段的准确性进行评价,从而判断出用户的发音水平。
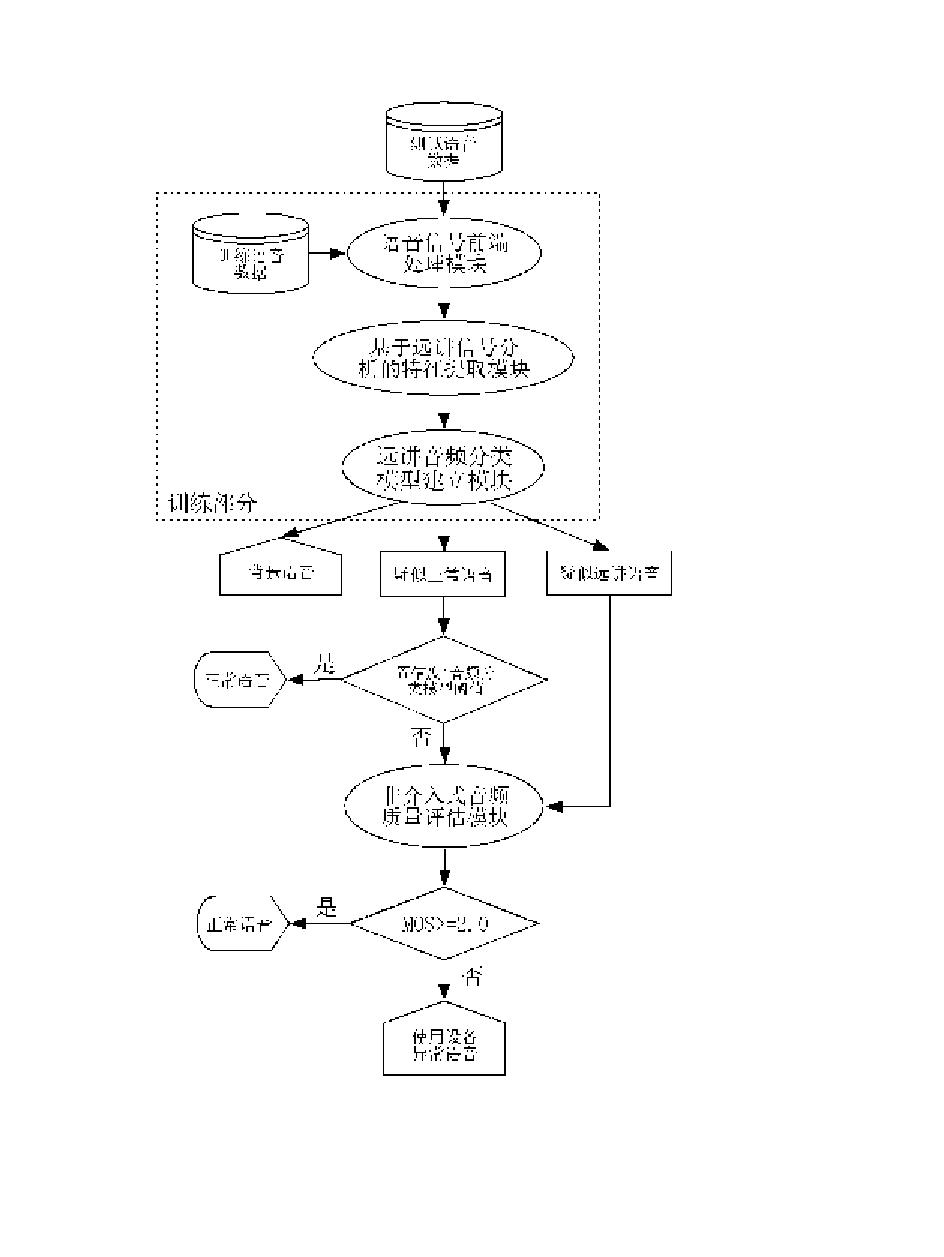
目前,采用声学模型和语音识别的框架进行音素切分和置信度计算来进行语音质量评测是一种应用较广的做法。例如,图1为一种现有的语音质量评测方法的示意图。如图1所示,输入语音首先利用声学模型对目标词序列作强制对齐。在这个过程中,可以获得对应于输入语音的音素分割点以及状态分割点。然后,计算出目标文本在待评估语音下的音素后验概率作为置信度,最后通过分数预测器获得机器自动评估的发音质量分数。在现有方法中,解码和置信度计算均使用了声学模型。声学模型是对标准发音声学空间中各个音素单元的建模,因此它没有对不同的发音质量进行描述,所以当遇到发音水平比较差的用户时,采用声学模型不能获得较为准确的音素分割点和音素后验概率值,从而很不利于发音质量评估系统的在线使用和实际推广。
发明内容发明内容
本发明的目的在于克服现有技术的不足,在未明显增加计算量的情况下,以提高系统稳健性为主要目标,提出一种基于发音模型的语音质量评测方法。该方法充分利用发音质量评估和语音识别的差别,对不同的发音质量等级进行区分性建模,构建出一个比声学空间更为广阔的发音空间,从而在解码时获得更准确的音素分割点,在置信度计算时获得更精确的音素后验概率,从而提高评估性能。
为实现上述发明目的,本发明提供的基于发音模型的语音质量评测方法,该方法包括发音模型的构建步骤和语音质量评测步骤;
其中发音模型构建步骤包括下列子步骤:
1.1)确定发音质量音素集;
1.2)对训练数据划分发音质量等级;
1.3)依据发音质量等级训练发音模型;
语音质量评测步骤包括下列子步骤:
2.1)提取待评测发音段的语音特征;
2.2)构建基于所述发音模型的解码网络,进行Viterbi解码;
2.3)对每个音素计算基于发音模型的置信度;
2.4)根据所述置信度得出所述待评测发音段的发音质量。
所述步骤1.1)中对每个音素分为三个不同的发音质量等级。
所述步骤1.2)中训练数据的发音质量等级划分包括如下步骤:准备训练数据的原始语音和音素标注文本;采用Viterbi解码算法,将原始语音和音素标注进行强制对齐,计算每个音素的后验概率;按照音素后验概率值的大小划分发音质量等级。
所述步骤1.3)中,所述发音模型采用传统隐马尔可夫模型的框架构建。
所述步骤2.2)中搭建基于发音模型的解码网络包括如下步骤:利用发音字典将目标文本转换成音素串序列;对每个音素将其各个发音质量并联;将音素串序列转换成各个音素质量并联子网络的串联宏网络即获得基于发音模型的解码网络。
所述步骤2.3)中对每个音素计算基于发音模型的置信度包括如下步骤:利用步骤2.2)中Viterbi解码获得的音素分割点信息,在指定音素段间搭建音素混淆网络;在音素混淆网络的每条路径上利用Viterbi算法获得声学似然值;计算音素后验概率作为发音质量评价的依据,取目标音素最优质量对应的路径上的声学似然值作为所述音素后验概率的分子,混淆网络的所有路径上的声学似然值的和作为所述音素后验概率的分母。
所述步骤2.4)中采用线性预测器得出所述待评测发音段的发音质量。
本发明的优点是,将不同的发音质量引入到模型训练和评测过程中。在现有技术中,发音质量评估系统的解码和置信度计算均采用声学模型进行,声学模型通常都是以音素为基本单元训练的,训练数据为标准发音,这样不同发音质量信息没有被利用。本发明充分利用了发音质量评估和语音识别的应用目标差异,对不同的发音质量等级进行区分性建模,构建出一个比声学空间更为广阔的发音空间,是对发音质量评估系统的应用空间更为精细的描述,从而在解码时获得更准确的音素分割点,在置信度计算时获得更精确的音素后验概率值。
附图说明附图说明
图1是现有技术的语音质量评测方法的示意图;
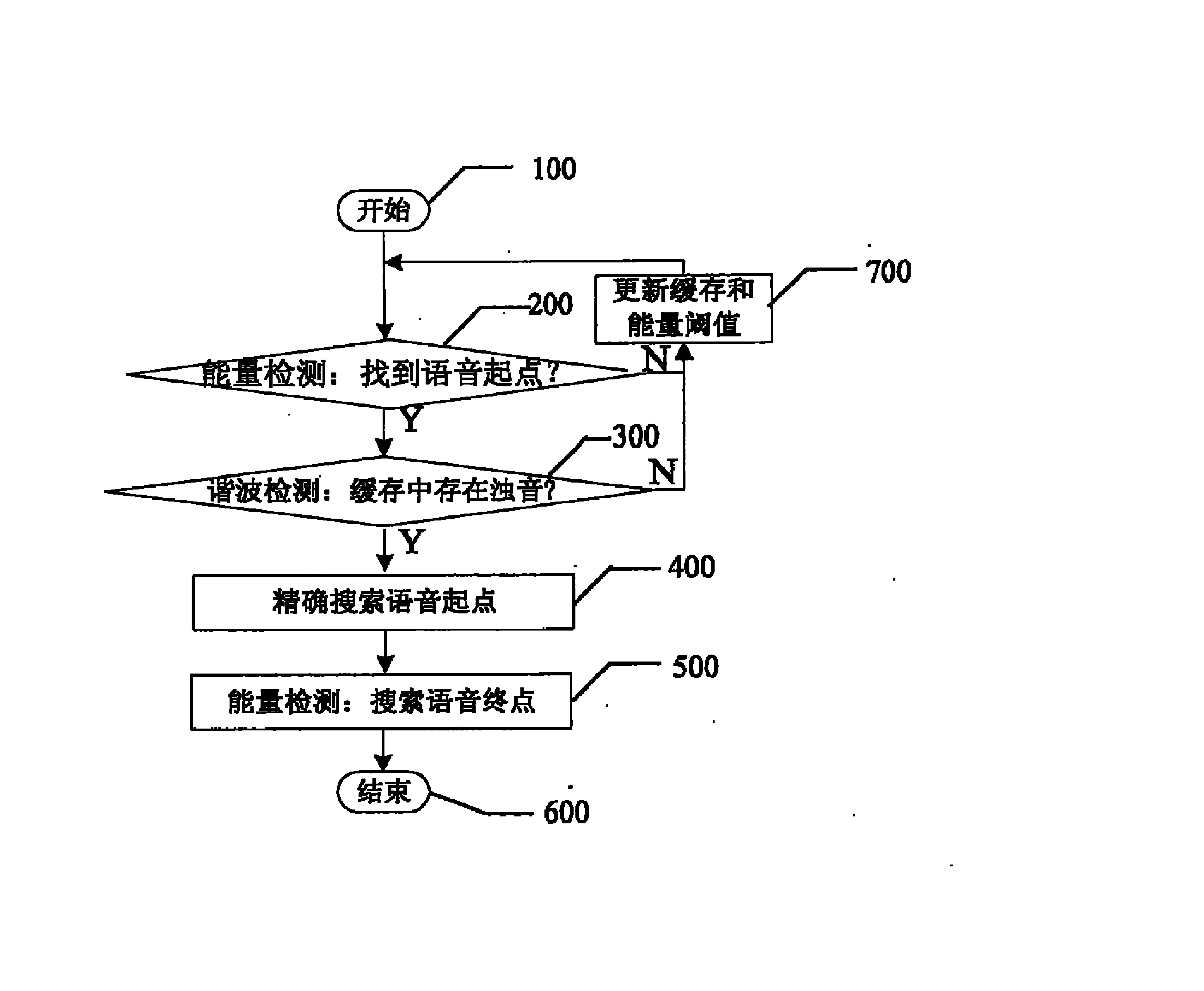
图2是本发明的基于发音模型的语音质量评测方法一个实施例的流程图;
图3是本发明的基于发音模型的语音质量评测方法中的解码网络状态图的搭建示意图;
图4是本发明的基于发音模型的语音质量评测方法中的音素混淆网络的搭建示意图;
图5是本发明的基于发音模型的语音质量评测方法的基于状态图的强制对齐示意图。
具体实施方式具体实施方式
下面结合附图及具体实施例对本发明的基于发音模型的语音质量评测方法做进一步地描述。
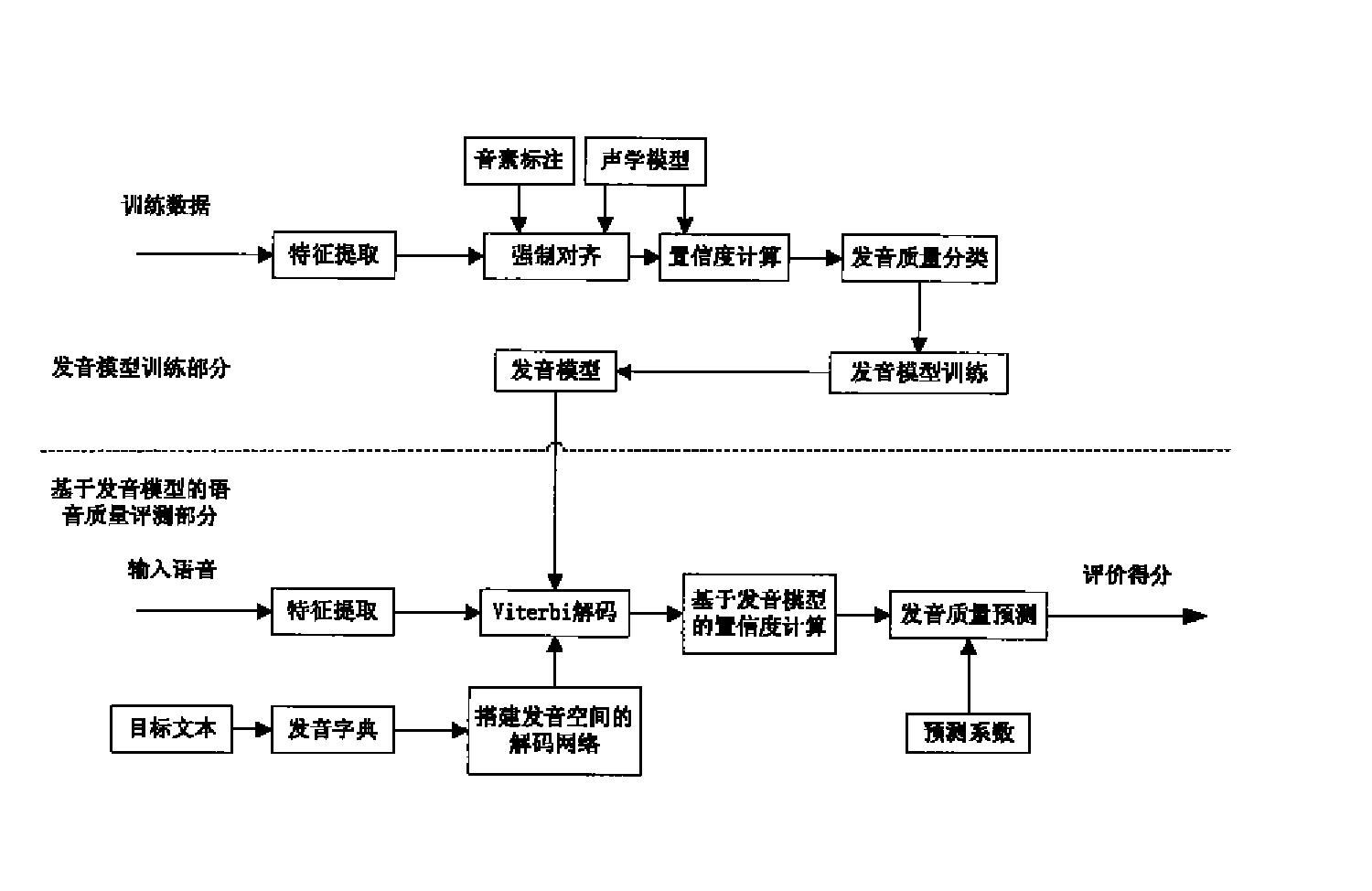
图2是本发明的基于发音模型的语音质量评测方法一个实施例的流程图。如图2所示,该实施例提供的基于发音模型的语音质量评测方法包括如下步骤:
1)构建发音模型
1.1)确定发音质量音素集。对每一个音素建模单元,本实施例将其发音质量分为三个等级,即好、中、差。以音素“zh”为例,三个等级的音素分别标记为“zh_1”、“zh_2”和“zh_3”,“zh_1”为发音质量最好的,即音素“zh”的标准发音。假设目标语言有n个音素,这样发音模型的音素集中就定为n*3个建模单元。
1.2)对训练数据划分质量等级。人工标注发音质量劳动强度大,加之训练数据量很大,这样使得人工获取训练数据的音素发音质量等级有很大困难。本实施例按照音素后验概率大小的原则,采用机器自动划分的方式完成发音质量的划分,具体包含三个步骤:
1.2-1)准备训练数据的原始语音和音素标注文本;
1.2-2)提取语音特征,利用音素标注和声学模型,采用Viterbi解码算法,将原始语音和音素序列进行强制对齐。然后,在各个音素语音段内,计算音素后验概率值。
1.2-3)按照音素后验概率值的大小排序,从大到小划分发音质量等级,使得每个等级的数据个数均衡,采用相异的符号对不同音素的不同发音质量等级进行标记。
1.3)类似声学模型的训练过程,同样采用隐马尔科夫模型(HMM)的框架训练发音模型。
2)采用发音模型进行语音评测
2.1)提取语音特征;
2.2)利用目标文本和发音词典,构建发音空间的解码网络,进行Viterbi解码。
本步骤中解码网络状态图的构建方法如下:
图3是本发明的基于发音模型的语音质量评测方法中的解码网络状态图的搭建示意图。如图3所示,首先根据目标文本搭建起一个词串的搜索空间,即包含在目标文本中所有词的串联网络。然后,借助发音字典的信息,把词网展开成一个音素网络。在每个音素节点上,该音素对应的所有发音质量等级构成一个并联子网络。最后,每个音素再被发音模型中相对应的HMM所取代,每个HMM由三个状态组成。这样,最终的搜索空间就变成了一个状态图,状态图中的任意一条路径代表一个音素序列候选,该音素序列包含发音质量等级信息。通过比较不同路径上的累积概率值(似然概率与转移概率)来获得最优路径,从而获得音素分割点信息。
2.3)利用各个音素的时间分割点信息,计算每个音素基于发音模型的置信度。本步骤中可以采用基于音素混淆网络的音素后验概率、基于帧平均的音素后验概率或者传统的Goodness of Pronunciation概率作为置信度。图4是本发明的基于发音模型的语音质量评测方法中音素混淆网络的搭建示意图。如图4所示,以目标音素“zh”为例加以说明,在2.2)的解码结果中,该音素段的上文是“a1_1”,下文是“uo1_2”。因为“zh”是声母,因此本实施例选择所有声母的所有质量等级作为“zh”的易混淆音素,再利用解码结果的上下文进行三音子扩展,最后将所有扩展后的三音子并联,构成该音素段的混淆网络。在音素混淆网络的每条路径上,对语音帧和HMM状态作强制对齐处理,从而获得该语音段在该路径下的声学似然值。选取目标音素最优质量对应的路径上的声学似然值作为后验概率的分子,混淆网络的所有路径上的声学似然值之和作为后验概率的分母,如此获得基于混淆网络的音素后验概率作为每个音素基于发音模型的置信度。
该强制对齐过程也是一个简单的解码过程,只是这时的候选项是同一音素的所有状态序列,最佳状态序列作为最佳路径被解出来。图5是本发明的基于发音模型的语音质量评测方法中的基于状态图的强制对齐示意图。在图5中,虚线代表候选状态序列,而黑实线代表解出来的最优路径即最佳状态序列。如图5所示,当某一状态序列对观察序列(本实施例中的观察序列为特征向量)出现的似然概率P(X|S)最大时,认为该状态序列为最佳状态序列。
2.4)预测发音质量分数,本步骤是采用线性预测器完成的。
音素的置信度得分被用来衡量该音素发音质量的好坏。在评价语音质量评测方法的性能时,采用与专家评估作对比的方式进行,即对同一批语音数据机器评估和专家评估发音质量同时进行,以专家评估的结果作为标准,机器评估结果与其一致认为机器评估正确,否则认为机器评估错误,这样统计出一个打分正确率。比较打分正确率的变化即可获知不同评测方法性能的优劣。从音素的置信度得分到机器评估结果之间存在着影射关系的问题,在此采用了阈值分类的方法。按照打分正确率最高的原则,在开发集上训练出各个音素的置信度阈值;在测试过程中,当置信度高于该音素的置信度阈值时认为发音准确,反之则认为该发音存在缺陷。
使用香港普通话水平考试现场录制的三个数据集对本发明的基于发音模型的语音质量评测方法进行测试,分别为PSK1、PSK2和PSK3。PSK1中有182个女生和107个男生的数据,PSK2中有122个女生和79个男生的数据,PSK3中有64个女生和44个男生的数据。被试均是香港本地的大学毕业生,普通话水平普遍不太好。每位被试朗读的目标语音都是事先指定的50个单字和25个双字词,针对不同的数据集,事先指定的目标语音内容各不相同。在每个数据集中随机取出60%作为训练分数影射阈值的开发集,剩下的40%作为测试集。本试验通过比较打分正确率的高低来评价发音质量评估系统的性能优劣。对所有语音数据均以语言学专家的音素打分结果作为评价发音质量评估系统性能的依据。当机器自动评估获得的音素打分与语言学专家的打分结果一致时,机器打分正确;否则,机器打分错误。打分正确率越高,机器评估的准确性越好。
使用两种不同的语音评测方法进行性能比较。一种如图1所示,定义为现有方法;另一种为如图2所示,是本发明的基于发音模型的语音质量评测方法,定义为基于发音模型的方法。现有方法使用传统的声学模型,该声学模型包含217个音素,每个音素采用上下文相关三音子的隐马尔可夫模型描述,隐马尔可夫模型中每个状态的输出概率分布采用16个高斯分量的混合高斯模型来建模,共有5456个共享状态。而在基于发音模型的方法中,将声学模型替换成发音模型。该发音模型不仅描述了不同音素的声学特征分布情况,而且把发音质量的概念引入其中,将不同的发音质量等级区分建模,它包含217*3个音素质量等级单元,同样采用上下文相关的三音子结构和隐马尔可夫模型,共有5541个共享状态。
表1是本发明的基于发音模型的语音质量评测方法与现有技术的性能对比测试表。两种方法的性能对比测试结果如表1所示。
表1
从表中可以看出,本发明所使用的基于发音模型的语音质量评测方法的性能要好于现有方法,在PSK1、PSK2和PSK3上分别相对提高8.17%、8.72%和7.91%。
本发明对不同的发音质量等级进行区分性建模,构建出一个比声学空间更为广阔的发音空间,是对发音质量评估系统应用空间更为精细的描述。利用这种发音模型,在解码时获得更准确的音素分割点,在置信度计算时获得更精确的音素后验概率值,从而使语音质量评测的性能获得大幅度提升。
一种基于发音模型的语音质量评测方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。














动态评分
0.0