









专利摘要
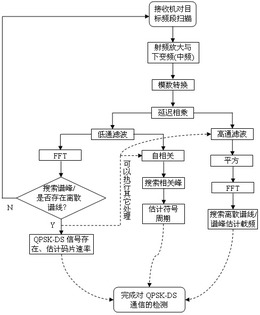
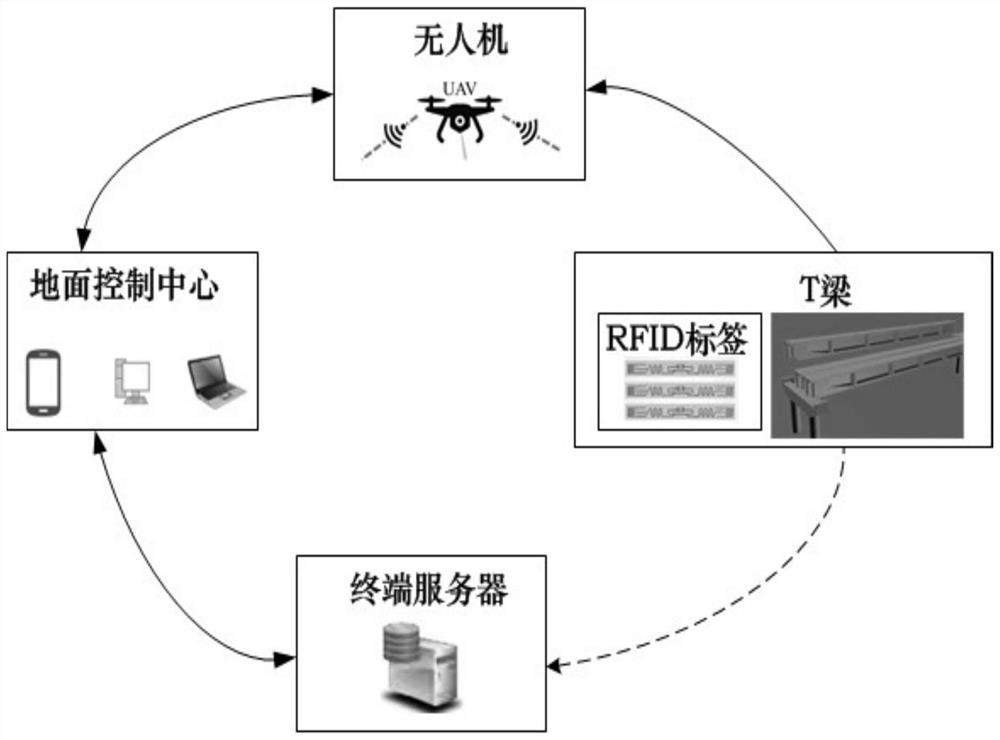
一种无人机混合路径规划方法,其特征在于:它包括如下步骤: 1、在现有ADA*算法的基础上改进得到EADA*算法; 在已有的ADA*算法基础上通过添加头排序算法思想实现头排序功能; 其实现具体的步骤如下: 1、在ADA*算法初始化阶段将ε的值设置为一个较大值,大于或等于2.0;创建空队列 OPEN、CLOSED、INCONS和WALLS;除了目标在路径中的代价为0,g(s)和v(s)的值在所有状态 下都被设置为无穷大; 2、开始状态以每次迭代的状态速度沿着当前次优解移动;在每一次的迭代中, 向 目标地点移动;寻路循环一直持续到机体到达最终目标状态即 ; 3、计算当前路径的代价并与前一次的迭代结果进行比较,如果依然存在与当前路径 相交的障碍物,总的代价将会增加; 4、在代价增多的情况下,增大膨胀系数inflation,清除WALLS障碍物列表,并重新计 算受代价变化影响的局部状态,如果没有观察到成本变化,则降低膨胀系数的值以改善当 前路径;不一致的状态移到OPEN列表中; 5、计算改进的当前路径,搜索从目标状态开始,找到Open列表中的第一个关键字,此 关键字小于开始状态的关键字;使用key()函数计算优先级关键字的第一个元素的关键 字,使用Eq更新键值;如果新的键值比旧的键值大,则状态会与新的键保存在OPEN列表中, 否则,g(s)=v(s)被设置,状态被移到CLOSED列表; 6、在优先级队列中最小化排序队列的次数,实现头排序的功能; 从OPEN队列中删除优先级键最小的状态;然后在给定的状态下,使用Key()函数来计算 新的键值,如果 将该状态重新插入到具有新键值的优先级队列的头部;同时边 缘代价变化也迫使ε值增加;优先级顺序保持不变;即使ε增加, 仍是最小的键值;因此, 不需要额外的排序;如果 的情况下,EDAD*算法将与ADA*算法相同的方式扩展状 态;如此即可得到EADA*算法; 2、图像预处理; 对无人机拍摄的图像进行预处理,具体的步骤如下: 2.1、从无人机的前置摄像头接收预处理的深度图像,对每一帧收到的图像进行灰度化 操作; 2.2、对灰度化之后的图像进行resize操作,将灰度化后的图像缩放,调整图像尺寸大 小,聚焦我们关注的视野区域;如此得到预处理之后的图像; 3、根据步骤2得到的预处理之后的图像,计算相对目标位置和当前速度; 3.1计算相对目的地的距离和方向: 公式1中S代表当前位置距目的地的相对距离位置, 代表当前的位置, 代表目 标地的位置;使用公式1计算相对目的地的距离和方向; 3.2、获得当前位置速度,在执行任务期间,RMP向本地规划提供当前传感器数据以及 UAV的位置和速度,如此获得当前位置的速度; 4、构建基于DRL的局部规划的神经网络; 使用基于DQN算法的DRL系统网络体系结构;该网络采用30 × 100状态表示、当前位置 和速度作为输入;第一层将32个8 × 8的核与输入图像进行步长为3卷积,指数线性单元 ELU值为0.8,并使用修正单元ReLU激活函数;第二卷积层获得4×4的步长为2的64个核和 0.8的ELU值,并再次被RelU激活函数激活;第三个卷积层卷积64个3 × 3步长的核,紧跟着 一个修正单元ReLU激活函数,而第四个层的输出被展平降维并与位置向量连接;组合的输 入被输入到两个全连接层,其中第一层包括256个隐藏单元,第二层包括128个隐藏单元; 动作空间决定了最后一个完全连接层中隐藏单元的数量;在本申请中,使用7个动作空 间;动作空间包括系统在特定环境中可以执行的所有动作的集合;它由七个可以用来避开 障碍物的独立动作组成;第一个是沿着当前方向移动,速度为1、2、3或4m/s,第二个涉及以1 m/s的速度沿当前方向向后移动;第三和四个动作涉及向右和向左旋转30度;第五个和六个 动作分别涉及向上下位置移动,速度为2 m/s,最后一个动作是保持当前位置;在每个时间 步长,使用策略选择观测空间作为输入,输出是这七个动作中的一个;这些高级动作使用 Gazebo仿真器提供的飞行控制器映射到低级飞行命令;通过状态空间,agent在训练和学习 过程中可以将动作行为转换并使用所有状态,用于应用程序科学的输入状态;如此即可得 到基于DRL的局部规划的神经网络; 5、训练学习阶段 5.1、设置训练参数,在步骤4基于DRL局部规划神经网络基础上,按照Q‑Learning的方 法,使用公式2设置学习过程中使用的reward;当UAV到达目的地时,给予到达的reward:回 报函数设计在DRL应用中是极其重要的一环,通过将任务目标具体化和数值化,实现了目标 与算法之间的沟通;在本研究中,条件 被视为表示到达目的地;与墙壁、其他 UAVs或汽车等障碍物碰撞时,给予碰撞reward;在其他情况下,根据UAV和目的地之间的关 系给予积极或消极的reward;对接近目的地的行动给予正面reward,对远离目的地的行动 给予负面reward; 表示 在时刻t的值, 是一个衰减超参数: 如果无人机撞到静态或动态障碍物,agent将获得负50的reward;一个新的epoch在无 人机处于[0,0,0]的初始位置开始,这表明北、东、下点的坐标与模拟器中协调一致;为了更 新网络的权重,对损失函数应用小批量梯度下降,如下所示: 公式3中的 是当前目标动作行为的输出值,代表动作行为的值;是权重;n是小批量 的梯度下降的batch大小,为了避免高估,agent使用下列的等式更新目标 的值; 公式4中的 是采取行为 后的即时回报,γ是折扣系数; 5.2、以一个epoch的训练过程为例,环境包括静态和动态移动障碍物;静态环境是指环 境中的障碍物是不会移动的,动态环境是指所有障碍物都是以不同的速度和方向随机移动 的;训练阶段的目的地是在gazebo仿真模拟器中随机标点,并人为设置障碍物,在gazebo模 拟器中实时进行训练模拟;在动作行为输出选择中,行为动作空间中的行为索引数i是通过 算法得到的; 算法选择一个在当前 状态下取最大Q‑Value的行为动作或 者选择一个在开始学习过程中概率较高的随机动作;由于动作 ,得到reward 和判断 以及下一个UAV的状态; 5.3、将5.2中得到的reward 和判断 以及下一个UAV的状态添加到神经网络经验记忆 中;通过从经验记忆中随机检索并通过误差反向传播算法更新神经网络的单位权重来执行 学习; 5.4、在5.1、5.2、5.3过程中,应该在 状态下采取的动作行为的Q‑Value被更新的更大, UAV通过避开路径上的障碍物来学习向目的地移动所需的行为; 6、将相机实时拍摄的图像传入基于DRL局部规划神经网络中,在无人机事先路径规划 之后,实时进行局部规划、重新规划调整飞行路线,其步骤如下: 6.1、在无人机机载计算设备上部署深度神经网络模型运行所依赖的环境; 6.2、将步骤5所得平均精度均值最大的模型移植到无人机机载计算设备中,将无人机 摄像头获取的图像通过硬件接口实时传入机载设备; 6.3、将步骤2预处理之后的图像、当前相对目标的位置以及当前速度传入网络模型,经 过模型检测后,程序实时的对当前全局路线进行规划并在遇到障碍物时重新规划路线控制 无人机的动作。
一种无人机混合路径规划方法专利购买费用说明
![]()
Q:办理专利转让的流程及所需资料
A:专利权人变更需要办理著录项目变更手续,有代理机构的,变更手续应当由代理机构办理。
1:专利变更应当使用专利局统一制作的“著录项目变更申报书”提出。
2:按规定缴纳著录项目变更手续费。
3:同时提交相关证明文件原件。
4:专利权转移的,变更后的专利权人委托新专利代理机构的,应当提交变更后的全体专利申请人签字或者盖章的委托书。
Q:专利著录项目变更费用如何缴交
A:(1)直接到国家知识产权局受理大厅收费窗口缴纳,(2)通过代办处缴纳,(3)通过邮局或者银行汇款,更多缴纳方式
Q:专利转让变更,多久能出结果
A:著录项目变更请求书递交后,一般1-2个月左右就会收到通知,国家知识产权局会下达《转让手续合格通知书》。





动态评分
0.0